
卷積神經網路的網路結構——Siamese Network
《Learning a Similarity Metric Discriminatively, with Application to Face 》
引言:
Siamese網路是一種相似性度量方法,當類別數多,但每個類別的樣本數量少的情況下可用於類別的識別、分類等。傳統的用於區分的分類方法是需要確切的知道每個樣本屬於哪個類,需要針對每個樣本有確切的標籤。而且相對來說標籤的數量是不會太多的。當類別數量過多,每個類別的樣本數量又相對較少的情況下,這些方法就不那麼適用了。其實也很好理解,對於整個資料集來說,我們的資料量是有的,但是對於每個類別來說,可以只有幾個樣本,那麼用分類演算法去做的話,由於每個類別的樣本太少,我們根本訓練不出什麼好的結果,所以只能去找個新的方法來對這種資料集進行訓練,從而提出了siamese網路。siamese網路從資料中去學習一個相似性度量,用這個學習出來的度量去比較和匹配新的未知類別的樣本。這個方法能被應用於那些類別數多或者整個訓練樣本無法用於之前方法訓練的分類問題。
網路結構:
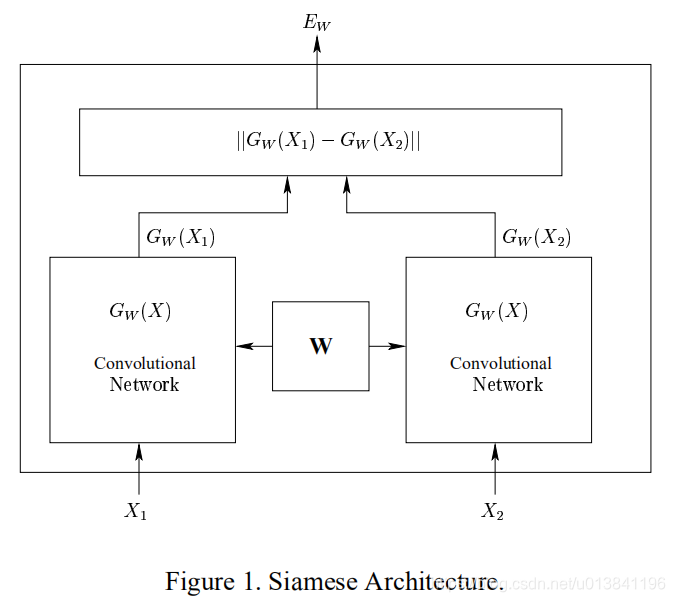
左右兩邊兩個網路是完全相同的網路結構,它們共享相同的權值W,輸入資料為一對圖片(X1,X2,Y),其中Y=0表示X1和X2屬於同一個人的臉,Y=1則表示不為同一個人。即相同對為(X1,X2,0),欺騙對為(X1,X2,1)針對兩個不同的輸入X1和X2,分別輸出低維空間結果分別是Gw(x1)和Gw(x2),這個網路的很好理解,當輸入是同一張圖片的時候,我們希望它們之間的歐式距離很小,當不是一張圖片時,我們的歐式距離很大。有了網路結構,接下來就是定義損失函式,這個很重要,而經過我們的分析,我們可以知道,損失函式的特點應該是這樣的, (1) 當我們輸入同一張圖片時,他們之間的歐式距離越小,損失是越小的,距離越大,損失越大 (2) 當我們的輸入是不同的圖片的時候,他們之間的距離越大,損失越大 即:最小化相同類的資料之間距離,最大化不同類之間的距離。
損失函式定義:
首先是定義距離,使用l2範數,公式如下:
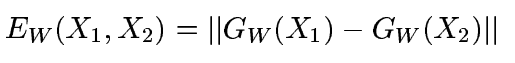 損失函式的形式為:
損失函式的形式為:
 其中是第i個樣本,是由一對圖片和一個標籤組成的,其中LG是隻計算相同類別對圖片的損失函式,LI是隻計算不相同類別對圖片的損失函式。P是訓練的樣本數。通過這樣分開設計,可以達到當我們要最小化損失函式的時候,可以減少相同類別對的能量,增加不相同對的能量。很簡單直觀的方法是實現這個的話,我們只要將LG設計成單調增加,讓LI單調遞減就可以了,但是我們要保證一個前提就是,不相同的圖片對距離肯定要比相同圖片對的距離小,那麼就是要滿足:
其中是第i個樣本,是由一對圖片和一個標籤組成的,其中LG是隻計算相同類別對圖片的損失函式,LI是隻計算不相同類別對圖片的損失函式。P是訓練的樣本數。通過這樣分開設計,可以達到當我們要最小化損失函式的時候,可以減少相同類別對的能量,增加不相同對的能量。很簡單直觀的方法是實現這個的話,我們只要將LG設計成單調增加,讓LI單調遞減就可以了,但是我們要保證一個前提就是,不相同的圖片對距離肯定要比相同圖片對的距離小,那麼就是要滿足:
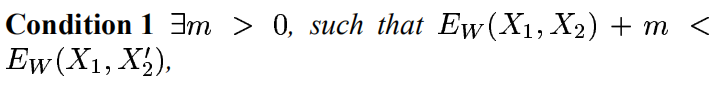 其他條件如下:
其他條件如下:

然後作者也給出了證明,最終損失函式為:
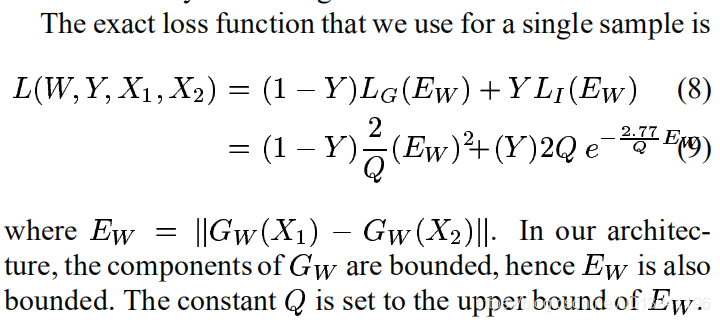 Q是一個常數。
Q是一個常數。
需要強調的是,程式碼中同一類圖片是0,不同類圖片是1,使用tensorflow實現的這個損失函式如下:
程式碼:
def siamese_loss(model1, model2, y):
# L(W,Y,X1,X2) = Y*2/Q*||CNN(p1i)-CNN(p2i)||^2 + (1-Y)*2*Q*exp(-2.77/Q*||CNN(p1i)-CNN(p2i)||
margin = 5.0
Q = tf.constant(margin, name="Q", dtype=tf.float32)
E_w = tf.sqrt(tf.reduce_sum(tf.square(model1 - model2),1))
pos = tf.multiply(tf.multiply(tf.to_float(y), 2/Q), tf.square(E_w))
neg = tf.multiply(tf.multiply(tf.to_float(1-y),2*Q),tf.exp(-2.77/Q*E_w))
loss = pos + neg
loss = tf.reduce_mean(loss, name="loss")
return model1, model2, loss