
Siamese-fc孿生網路目標跟蹤
全名:Fully-Convolutional Siamese Networks for Object Tracking
論文摘自ECCV Workshop 2016,由Luca Bertinetto、Jack Valmadre、Jo ̃ao F. Henriques、Andrea Vedaldi與Philip H. S. Torr撰寫,它是Jo ̃ao F. Henriques繼KCF之後又一大作。
摘要
傳統演算法使用視訊本身作為唯一的訓練資料,限制了模型豐富性。作者利用深度卷積網路,為了避免影響速度,線上進行隨機梯度下降以適應網路權重。
提出思路:使用ILSVRC15資料集,訓練一個端到端的全卷積Siamese網路
特點:(1)超實時的幀速率執行;(2)極其簡單;(3)在多個基準測試中實現了最佳的效能。
1 前言
傳統演算法可以跟蹤任意物件,故不可能有收集好的資料和訓練好的檢測器。比如:TLD [2],Struck [3]和KCF [4]等方法。目前計算機視覺中的其他問題越來越普遍地採用從大型監督資料集訓練的深度卷積網路(conv-nets),但監督資料稀缺和實時操作約束阻礙了深度學習在該方法(每個視訊訓練一個檢測模型)中的應用。最近的一些工作使用預訓練的深度卷積來克服上述限制:
法一:使用網路的內部表示作為特徵應用於“淺層”方法(例如相關濾波器),但並未充分利用端到端訓練
法二:用SGD(隨機梯度下降)來微調網路的多個層,雖然實現結果很好卻不實時。
作者提出,在初始離線訓練階段訓練深度卷積網路以解決更一般的相似性學習問題,然後在跟蹤期間簡單地線上評估該網路。使得在速度遠遠超過幀速要求的現代跟蹤基準測試中表現很好。本文的主要貢獻是
(1)我們訓練一個孿生(Siamese)網路,在更大的候選影象中定位目標
(2)建立了一種新的Siamese結構,它對候選影象進行全卷積:使用計算其兩個輸入互相關的雙線性層實現密集而有效的滑窗評估。
2 訓練
設學習函式f(z,x),即將示例影象z與相同大小的候選影象x進行比較,相同則返回高分。
測試所有可能位置
更進一步,將深度卷積網路作為函式f。Siamese網路對輸入x、z用變換φ,定義:f(z,x)= g(φ(z),φ(x))用函式g組合輸入表示。
深度Siamese卷積網路先前已應用於面部驗證[18,20,14],關鍵點描述學習[19,21]和一次性字元識別[22]等任務。
2.1 全卷積Siamese架構
作者提出一種對於候選影象x的全卷積Siamese架構。當一個函式為轉換函式,那麼它就是全卷積的。引入Lτ來表示平移運算元(Lτ x)[u] = x [u-τ],對於任意平移τ與整數步長k,如果滿足
![]()
(當x是有限訊號時,輸出範圍也是有限區間)那麼訊號對映函式h是全卷積的。
全卷積網路與候選影象大小無關,它將計算所有轉換子視窗x與z的相似性。作者使用卷積嵌入函式φ和互相關層組合所得到
![]()
其中b1表示在每個位置的取值(b∈R)。
(1)此網路的輸出f(z,x)是在有限網格D⊂上定義的分數圖,網路滿足:f(z,x)= f(x,z)
(2)嵌入函式的輸出φ是空域上的特徵對映(不是普通向量)

分數塊中的紅色和藍色畫素包含對應塊的相似性。
在跟蹤期間,我們使用以目標的先前位置的中心作為候選影象x的中心,其中最大分數的位置=分數圖中心網路塊大小。使用互相關組合特徵圖並在較大的候選影象上評估該訓練網路,在數學上等同於使用內積組合特徵圖並且獨立地評估每個轉換子窗上的訓練網路。互相關層提供了一種非常簡單的方法,可以在現有的conv-net庫的框架內有效地實現此操作,它在訓練和測試期間非常有用。
2.2 訓練
(1)對於損失計算:採用判別性方法,在正負樣本對上訓練網路,採用log損失
![]()
其中v是單個樣本候選對的實際分數,y∈{+1,-1}是對應的GT值。
訓練期間,使用包含示例圖對和更大候選圖對來實現網路全卷積。這將生成分數圖v:D→R,生成對每個影象對的對映。
將得分圖的損失定義為所有損失的均值
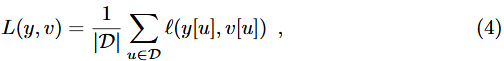
要求分數圖中每個位置u∈D的GT值y[u]∈{+1,-1}。通過將隨機梯度下降(SGD)來獲得卷積網路的引數θ
![]()
如圖2所示,通過提取兩個幀(最多相隔T幀)中以目標為中心的示例圖x(第n幀)和候選圖z(第n+T幀)
在訓練期間忽略目標類別。在不破壞影象的長寬比的情況下對每個影象內的目標比例進行歸一化。
(2)對於正負樣本的劃分:分數圖的元素在中心的半徑R內(考慮到網路的步幅k),即:

將正負樣本損失值加權用來消除類不平衡。

2.3 在ImageNet資料集上訓練
ImageNet2015物件檢測:對30種不同類別的動物和車輛進行分類和定位。 訓練集和驗證集合包含4417個視訊(train-3862與val-555),超過200萬個標記的bounding-box。(VOT [12],ALOV [1]和OTB [11]中標記序列的數量總共少於500個視訊)
作者認為,ImageNet資料集在跟蹤方面影響更廣,場景和物件與規範跟蹤基準中的不同,不會導致過擬合。
2.4 實際考慮
1、資料集處理
訓練階段
輸入影象大小:127×127的第n幀,255×255的第n+T幀。bounding-box大小為(w,h),變動區間為p,比例因子s使得面積不變:
![]()
我們使用原始圖,p =(w + h)/ 4。為了避免在訓練期間調整影象大小,每個幀的原始和候選圖都進行了離線提取。用全卷積Siamese網路訓練。
資料集
ImageNet Video視訊,作者採用先驗法來限制提取訓練資料的幀數。
2、網路架構
採用嵌入函式φ的體系結構(類似於Krizhevsky等人的網路的卷積階段)
引數等資訊在表1中給出。除了conv5(最後一層)之外,ReLU非線性應用於每個卷積層及全連線層的輸出。在每個線性層之後都會進行批量標準化[24]。最後一步的Stride是8。

3、跟蹤測試階段
特點:不更新模型;不儲存之前幀的目標外觀;沒有采用光流法或顏色直方圖特徵;沒有使用Bounding-box迴歸來改進預測框。
測試階段:只搜尋大約Bounding-box大小的四倍的區域內的物件,並且在分數圖中新增餘弦窗以懲罰大位移。
通過處理候選圖的幾個縮放形式來實現跟蹤。分數變化會造成懲罰,並且當前規模的更新會受到抑制。
3 目前相關工作
詳情請看論文。
4 實驗結果
4.1 實施細節
訓練階段
使用MatConvNet [31]通過簡單的SGD計算式(5),式中引數初值遵循高斯分佈,然後根據改進的Xavier方法[32]進行縮放,總共進行50多次迭代,每次都有50,000個取樣對(第2.2節)。使用尺寸為8的小批量估計每次迭代的梯度,當數值達到到
範圍時,降低學習速率。
跟蹤測試階段
策略:(1)初始幀的目標外觀嵌入函式φ(z)只計算一次,並與後續幀的子視窗進行卷積比較。
(2)線上更新(特徵表示)樣本效果並不大,故不線上更新。
(3)跟蹤階段使用雙三次插值從17×17到272×272對得分圖進行上取樣,定位更準確。
(4)為了處理尺度變化,搜尋超過五個尺度()的物件,並通過線性插值更新尺度,阻尼係數為0.35。
程式碼網址:http://www.robots.ox.ac.uk/~luca/siamese-fc.html。
配置:單個NVIDIA GeForce GTX Titan X,4.0GHz英特爾酷睿i7-4790K
速度:86幀(SiamFC-3s);58幀(SiamFC)
4.3 OTB-13基準
OTB-13 [11]基準考慮了不同閾值下的每幀平均成功率:IoU高於某一閾值,則跟蹤成功。(曲線下方的面積大小代表跟蹤效果)
演算法比較:Staple [33] ,LCT [34],CCT [35],SCT4 [36],DLSSVM NU [37],DSST [38]和KCFDP [39]。
在訓練期間將25%的影象對轉換為灰度。所有其他超引數(用於訓練和跟蹤)固定不變。

4.4 VOT基準
資料集:標籤vot2015-final。(其中,當IOU=0時,認為跟蹤器失敗,則自動重新初始化五幀)
VOT-14結果
演算法比較:VOT2014最佳10個跟蹤器、Staple(CVPR2016)、GOTURN(ECCV2016)
評估指標:準確性(圖4中的縱座標:平均IOU)和魯棒性(圖4中的橫座標:失敗幀數/總幀數)。

VOT-15結果
演算法:VOT2015最佳40個跟蹤器。
評估指標:在VOT2015論文中,將長度為N幀的視訊中計算從Nn到Nm幀的平均IOU(對於[Nn,Nm]的取值方式:描述出概率密度函式(簡稱pdf:使用核函式估計)曲線,從中取出積分面積為0.5的幀區間[Nn,Nm],並且兩端的pdf值近似相等)

需要改進的方法:模型更新,邊界框迴歸,微調,記憶體
4.5 資料集
使用更大的視訊資料集可以進一步提高模型效能。
5 總結
(1)引入一種側重於在離線學習強嵌入的替代方法。
(2)Siamese全卷積深度網路能夠更有效地使用可用資料。 既可以在測試時通過執行有效的空間搜尋來反映,也可以在訓練時反映,其中每個子視窗有效地代表了一個有用的樣本,且成本很低。
(3)深度嵌入為線上跟蹤器提供了很多功能來源,並在跟蹤時很好地執行。