
Deformable Convolutional Networks理解
文章轉自知乎:https://zhuanlan.zhihu.com/p/37578271
Deformable Convolutional Networks
論文連結:https://arxiv.org/abs/1703.06211
程式碼連結:https://github.com/msracver/Deformable-ConvNets(官方實現,但是release的版本是遷移到MXNet上的,速度和performance上有些出入)
MSRA的文章,嚴格意義上講,deformable convolutional不僅僅只適用於object detection,作為對常見的卷積的一種改良,它可以廣泛應用在各個網路中,和空洞卷積一樣,是對傳統卷積的改良,而且某種意義上也可以說是空洞卷積的進一步拓展。
1. Background
這篇文章的motivation其實比較簡單,我們都知道,常規的卷積,包括池化這些操作,不管你怎麼累加,基本得到的都是矩形框……這個其實非常不貼合實際,在對不規則的目標建模的時候有非常大的侷限性。
作者認為克服建模形變困難主要是兩種方法:
- 通過提供變化足夠豐富的大量訓練樣本,讓訓練器強行記憶擬合
- 設計能夠檢測到形變的特徵和演算法,這方面主要還是以hand-crafted的特徵為主,這種在對付沒有考慮到的形變和過於複雜的形變的時候其實比較無力
CNN其實不具有旋轉不變性和尺度不變性的,所以本質上CNN是用的策略1,缺乏判斷形變的策略依據。侷限性比較多,比如固定的box對於靈活物體來說非常僵硬,比如同一層的特徵圖的不同位置可能對應的是不同形狀的物體,但是都和同一個卷積做計算。(理解這一點比較重要,涉及到後面對deformable卷積的理解)
作為對上述問題的解決方案,作者提出了一種新的卷積方式deformable convolution,在此基礎上提出了一種新的RoI pooling方法deformable RoI pooling。主要思路就是卷積操作不是在規規矩矩的3x3的格子裡做了,而是有了種種偏移,如下圖所示:

至於這個位置偏移是怎麼做的?看下個部分
2. Deformable Convolutional Networks
2.1 deformable卷積的計算公式
我們知道,一般的卷積是這種形式的:

留意到p0是中心點,pn是屬於R的3x3的kernel的9個位置,因此這是在3x3方格內取樣的一個規則卷積,而可形變的卷積就是在x(po+pn)之中再加上一個偏移量:

在實際當中,因為新增的這個偏移量往往是小數,導致比較難處理,作者採用的辦法是雙線性差值,根據相鄰的點來進行計算具體公式如下,留意到這裡的a-b如果差值大於1了,g就是0,所以只有比較接近的點才對線性差值的點有效果:
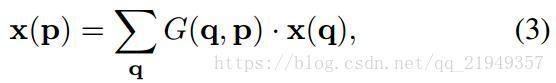
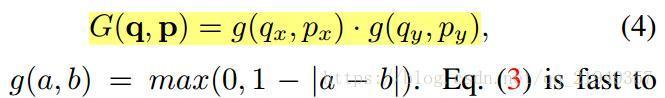
(以上是公式化的內容,關於差值內容如何求導可以到附錄裡面找)
2.2 偏置求法
重點來了,怎麼得到這個偏移量?,可變卷積神經網路的示意圖如下圖所示:
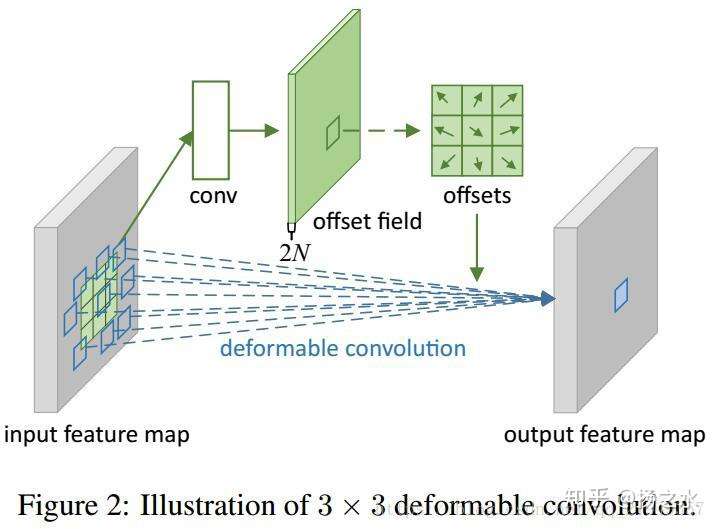
deformable convolution在特徵圖的每個位置都生成一個偏移量,注意是特徵圖的每個位置而不是卷積核的每個位置,我之前也經常誤解為後者……實際上這裡的特徵圖經過conv得到一個2N的offset field,N就是通道數,field是和feature map相同的,這樣HxWxN的feature map就得到了一個HxWx2N的offset filed,正好每個feature map位置有兩個偏移量。
然後將偏移量對應到原來feature map的每個位置,就可以在原來的feature map上做deformable卷積了~還不理解的話可以看這篇部落格https://blog.csdn.net/u011974639/article/details/79996353,是對照著程式碼講的,很詳細,不過這個只是幫助理解原理的,不能直接用,沒有重寫op,太慢。
還需要注意的一點是,如果input feature map到output feature map用的是空洞卷積之類的特殊結構的話,生成offset field的卷積也要使用相應的結構以保證一致。
2.3 Deformable RoI Pooling
為RoI pooling新增deformable機制其實和卷積的非常類似。因為本身RoI pooling的時候和卷積一樣,選取的也是方形區域,我們要做的也是增加偏移量。原來的RoI pooling過程可以表示為如下:

那麼新的RoI pooling計算公式則如下:
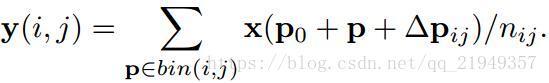
而它的偏移量的網路結構和計算過程如下圖所示:
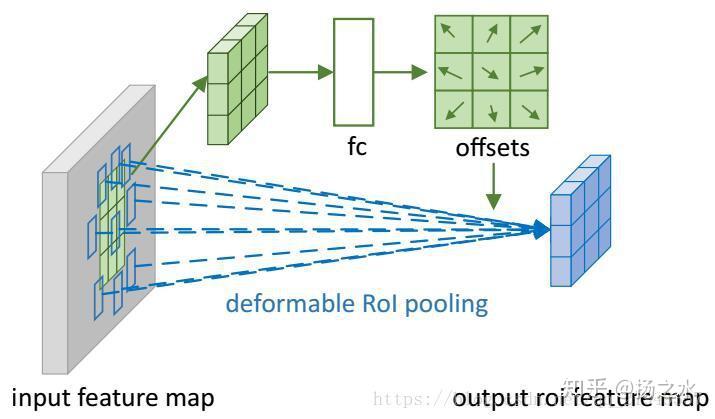
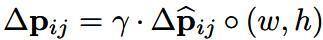
其中,要注意的有兩點:
- feature map此處是用fc來學習的,而且也不是直接學習最終偏移量,而是學習頭上帶三角號的那個變數……
- 這個變數會和(w, h)做點乘,然後再乘以一個尺度因子,其中w,h是RoI的寬和高,而伽馬是一個0.1的常數因子……個人理解,前者是為了讓deformable能和RoI的尺度結合起來,更好地估計偏移位置;而後者是為了防止偏移量太大甚至超出RoI和整個影象……之前也看到有人認為,DNN網路最後幾層經常會出現感受野不足的情況,所以空洞卷積才會效果比一般卷積好,如果不加約束,deformable的RoI可能無限制地擴大,這個觀念我還不是很理解,日後如果有了新發現再更新吧
另外就是作者還搞出了一個和R-FCN的位置敏感比較類似的另一種RoI方法,同樣是考慮deformable因素的,叫Position-Sensitive (PS) RoI Pooling,這裡就不詳細介紹了
2.4 deformable networks
這個部分沒什麼太多內容要介紹的,因為deformable卷積使用前後feature map是不變化的,因此大致上就是將卷積和Pooling方法直接替換到一些主流方法裡就好……一些網路設定就不談了,說兩個我感覺比較重要的點:
- 學習offset的那些引數怎麼初始化和學習:作者採用的是0初始化,然後按照網路其它引數學習率的$\beta$倍來學習,這個$\beata$預設是1,但在某些情況下,比如faster rcnn中的fc的那些,是0.01
- 並不是所有的卷積都一股腦地換成可行變卷積就是好的,在提取到一些語義特徵後使用形變卷積效果會更好一點,一般來說是網路靠後的幾層
3. 網路理解和實驗結果
3.1 對deformable卷積的理解
作者繪製了一些圖來方便我們理解deformable卷積,例如常規卷積和可形變卷積的一些對比:
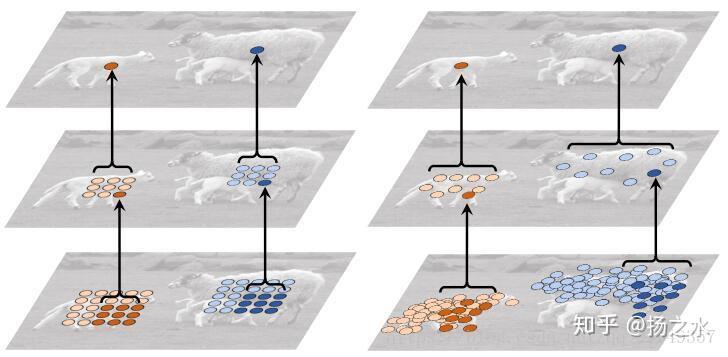
最上面的top feature map的activation units,中間層和最下層是上一層和上上層的卷積,可以看到它們產生的過程。這張圖應該會更清晰一點的:

綠色的點是activation units,而紅色的點是啟用點在3個level的deformable filters取樣位置(一共9的三次方700多個點),左中右分別是背景類,小目標和中等目標的取樣點分佈,和傳統的卷積還是產生了很大差異的。
另外也有關於RoI pooling中的9個Bin和gt的圖,可以看到和傳統的方法的差別,RoI pooling也會根據物體產生形變:

作者認為可形變卷積的優勢還是很大的,包括:
- 對物體的形變和尺度建模的能力比較強
- 感受野比一般卷積大很多,因為有偏移的原因,實際上相關實驗已經表明了DNN網路很多時候受感受野不足的條件制約;但是一般的空洞卷積空洞是固定的,對不同的資料集不同情況可能最適合的空洞大小是不同的,但是可形變卷積的偏移是可以根據具體資料的情況進行學習的
另外值得一提的是,作者發現可形變卷積可以適應物體的尺度,而背景類的尺度一般在medium和large尺寸的物體之間,作者認為這說明large的目標可以更有效幫助我們識別干擾,也算是無心插柳吧。
3. 2 實驗結果
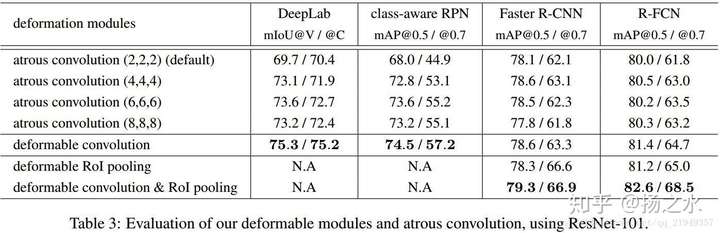
這是作者給出的最終結果,class-aware RPN是指分類別的RPN,可以視作一個簡易版本的SSD,而對DeepLab的方法筆者也不是很瞭解。
總的來說,這個工作亮點是很多,包括對卷積的改良,知乎上對這個工作有一些討論包括評論我覺得還是很不錯的:
https://www.zhihu.com/question/57493889/answer/153369805 (包括評論),卷積改變為類似取樣的思路都是很有意義的。但是看完之後總感覺也有一些疑問,比如懷疑是否一層網路真的能有效學習偏置,不同圖片的大量不同物體在offset優化上會不會引發競爭什麼的,不過都屬於很難量化和考察的內容了,最後還是要靠實驗結果說話,大概是目前煉丹的通病吧,有興趣的也可以留言討論下~