
pytorch實現 | Deformable Convolutional Networks | CVPR | 2017
阿新 • • 發佈:2020-12-20
文章轉載自微信公眾號:【機器學習煉丹術】,請支援原創。
這一篇文章,來講解一下可變卷積的程式碼實現邏輯和視覺化效果。全部基於python,沒有C++。大部分程式碼來自:https://github.com/oeway/pytorch-deform-conv 但是我研究了挺久的,發現這個人的程式碼中存在一些問題,導致可變卷積並沒有實現。之所以發現這個問題是在我視覺化可變卷積的檢測點的時候,發現一些端倪,然後經過修改之後,可以正常視覺化,並且精度有所提升。
## 1 程式碼邏輯
```python
# 為了視覺化
class ConvOffset2D(nn.Conv2d):
"""ConvOffset2D
Convolutional layer responsible for learning the 2D offsets and output the
deformed feature map using bilinear interpolation
Note that this layer does not perform convolution on the deformed feature
map. See get_deform_cnn in cnn.py for usage
"""
def __init__(self, filters, init_normal_stddev=0.01, **kwargs):
"""Init
Parameters
----------
filters : int
Number of channel of the input feature map
init_normal_stddev : float
Normal kernel initialization
**kwargs:
Pass to superclass. See Con2d layer in pytorch
"""
self.filters = filters
self._grid_param = None
super(ConvOffset2D, self).__init__(self.filters, self.filters*2, 3, padding=1, bias=False, **kwargs)
self.weight.data.copy_(self._init_weights(self.weight, init_normal_stddev))
def forward(self, x):
"""Return the deformed featured map"""
x_shape = x.size()
offsets_ = super(ConvOffset2D, self).forward(x)
# offsets: (b*c, h, w, 2)
# 這個self._to_bc_h_w_2就是我修改的程式碼
offsets = self._to_bc_h_w_2(offsets_, x_shape)
# x: (b*c, h, w)
x = self._to_bc_h_w(x, x_shape)
# X_offset: (b*c, h, w)
x_offset = th_batch_map_offsets(x, offsets, grid=self._get_grid(self,x))
# x_offset: (b, h, w, c)
x_offset = self._to_b_c_h_w(x_offset, x_shape)
return x_offset,offsets_
```
假設我們現在要對5通道的28x28的特徵圖進行可變卷積的offset的計算。
1. ```offsets_ = super(ConvOffset2D, self).forward(x)```
現在offsets_是一個10通道的28x28的特徵圖。
2. ```offsets = self._to_bc_h_w_2(offsets_, x_shape)```
呼叫這個函式特徵圖從(b,2c, h, w)變成(bxc, h, w, 2)的結構
3. ```x = self._to_bc_h_w(x, x_shape)```
改變原來特徵圖的結構,變成(bxc,h,w)
4. ```x_offset = th_batch_map_offsets(x, offsets, grid=self._get_grid(self,x))```
這個相當於把之前的偏移offsets施加到了特徵圖x上
5. ```x_offset = self._to_b_c_h_w(x_offset, x_shape)```
把施加偏移之後的特徵圖恢復成(b,c,h,w)的結構
可以看到,關鍵就是如何把offset施加到x上這個步驟。
```python
def th_batch_map_offsets(input, offsets, grid=None, order=1):
"""Batch map offsets into input
Parameters
---------
input : torch.Tensor. shape = (b, s, s)
offsets: torch.Tensor. shape = (b, s, s, 2)
Returns
-------
torch.Tensor. shape = (b, s, s)
"""
batch_size = input.size(0)
input_height = input.size(1)
input_width = input.size(2)
offsets = offsets.view(batch_size, -1, 2)
if grid is None:
grid = th_generate_grid(batch_size, input_height, input_width, offsets.data.type(), offsets.data.is_cuda)
coords = offsets + grid
mapped_vals = th_batch_map_coordinates(input, coords)
return mapped_vals
```
1. ```offsets = offsets.view(batch_size, -1, 2)```
offsets之前被改造成了(bxc,h,w,2)的樣子,現在再改成(b,cxhxw,2)的樣子
2. ```coords = offsets + grid```
這個感覺是offsets+grid,grid類似於畫素的xy軸,offsets是一個相對偏移,這樣offset+grid就變成了偏移之後的絕對座標,可以直接從特徵圖中定位到對應的元素。**因為畫素值的xy軸肯定為整數,因為這個偏移是小數,所以在特徵圖中定位到一個小數座標的元素是通過雙線性差值的方法獲取到這個不存在位置的畫素值的。**
3. ```mapped_vals = th_batch_map_coordinates(input, coords)```
這部分的內容是把offset施加到原特徵圖中
**差不多邏輯就是這麼個邏輯**
## 2 結果展示
先看使用了不使用可變卷積的結果:
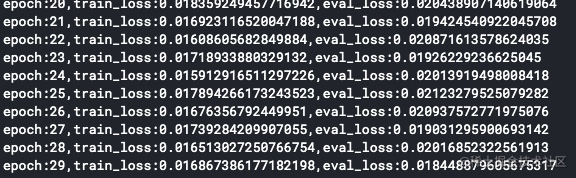
這種MNIST數字識別任務已經是幼兒園級別的了,所以成功率基本是非常高的:

在看使用了可變卷積的結果:

可以發現,最終的loss下降其實並比不過不用可變卷積的效果,**至於原因我也不確定,也許是任務太簡單了?我想到一點,也許是可變卷積的目的是對目標的紋理等更敏感,對於MNIST的分類問題反而起不到效果。**
最後我也搞出來這樣的一張圖,我在費盡千辛萬苦之後,終於實現的可變卷積的視覺化效果:

可以看到,可變卷積對於數字部分的反應大一些,檢測點在數字部分會有更大的偏移。不過可變卷積在我測試的過程中,這個偏移的大小不確定,這一次訓練模型可能偏移很大,下一次訓練可能偏移很小,似乎增加了網路訓練的難度。大概就這麼多把。(也不確定是不是自己程式碼的問題了。。)
## 3 完整程式碼
```python
class ConvOffset2D(nn.Conv2d):
"""ConvOffset2D
Convolutional layer responsible for learning the 2D offsets and output the
deformed feature map using bilinear interpolation
Note that this layer does not perform convolution on the deformed feature
map. See get_deform_cnn in cnn.py for usage
"""
def __init__(self, filters, init_normal_stddev=0.01, **kwargs):
"""Init
Parameters
----------
filters : int
Number of channel of the input feature map
init_normal_stddev : float
Normal kernel initialization
**kwargs:
Pass to superclass. See Con2d layer in pytorch
"""
self.filters = filters
self._grid_param = None
super(ConvOffset2D, self).__init__(self.filters, self.filters*2, 3, padding=1, bias=False, **kwargs)
self.weight.data.copy_(self._init_weights(self.weight, init_normal_stddev))
def forward(self, x):
"""Return the deformed featured map"""
x_shape = x.size()
offsets = super(ConvOffset2D, self).forward(x)
# offsets: (b*c, h, w, 2)
offsets = self._to_bc_h_w_2(offsets, x_shape)
# x: (b*c, h, w)
x = self._to_bc_h_w(x, x_shape)
# X_offset: (b*c, h, w)
x_offset = th_batch_map_offsets(x, offsets, grid=self._get_grid(self,x))
# x_offset: (b, h, w, c)
x_offset = self._to_b_c_h_w(x_offset, x_shape)
return x_offset
@staticmethod
def _get_grid(self, x):
batch_size, input_height, input_width = x.size(0), x.size(1), x.size(2)
dtype, cuda = x.data.type(), x.data.is_cuda
if self._grid_param == (batch_size, input_height, input_width, dtype, cuda):
return self._grid
self._grid_param = (batch_size, input_height, input_width, dtype, cuda)
self._grid = th_generate_grid(batch_size, input_height, input_width, dtype, cuda)
return self._grid
@staticmethod
def _init_weights(weights, std):
fan_out = weights.size(0)
fan_in = weights.size(1) * weights.size(2) * weights.size(3)
w = np.random.normal(0.0, std, (fan_out, fan_in))
return torch.from_numpy(w.reshape(weights.size()))
@staticmethod
def _to_bc_h_w_2(x, x_shape):
"""(b, 2c, h, w) -> (b*c, h, w, 2)"""
x = x.contiguous().view(-1, int(x_shape[2]), int(x_shape[3]), 2)
return x
@staticmethod
def _to_bc_h_w(x, x_shape):
"""(b, c, h, w) -> (b*c, h, w)"""
x = x.contiguous().view(-1, int(x_shape[2]), int(x_shape[3]))
return x
@staticmethod
def _to_b_c_h_w(x, x_shape):
"""(b*c, h, w) -> (b, c, h, w)"""
x = x.contiguous().view(-1, int(x_shape[1]), int(x_shape[2]), int(x_shape[3]))
return x
def th_generate_grid(batch_size, input_height, input_width, dtype, cuda):
grid = np.meshgrid(
range(input_height), range(input_width), indexing='ij'
)
grid = np.stack(grid, axis=-1)
grid = grid.reshape(-1, 2)
grid = np_repeat_2d(grid, batch_size)
grid = torch.from_numpy(grid).type(dtype)
if cuda:
grid = grid.cuda()
return Variable(grid, requires_grad=False)
def th_batch_map_offsets(input, offsets, grid=None, order=1):
"""Batch map offsets into input
Parameters
---------
input : torch.Tensor. shape = (b, s, s)
offsets: torch.Tensor. shape = (b, s, s, 2)
Returns
-------
torch.Tensor. shape = (b, s, s)
"""
batch_size = input.size(0)
input_height = input.size(1)
input_width = input.size(2)
offsets = offsets.view(batch_size, -1, 2)
if grid is None:
grid = th_generate_grid(batch_size, input_height, input_width, offsets.data.type(), offsets.data.is_cuda)
coords = offsets + grid
mapped_vals = th_batch_map_coordinates(input, coords)
return mapped_vals
def np_repeat_2d(a, repeats):
"""Tensorflow version of np.repeat for 2D"""
assert len(a.shape) == 2
a = np.expand_dims(a, 0)
a = np.tile(a, [repeats, 1, 1])
return a
def th_batch_map_coordinates(input, coords, order=1):
"""Batch version of th_map_coordinates
Only supports 2D feature maps
Parameters
----------
input : tf.Tensor. shape = (b, s, s)
coords : tf.Tensor. shape = (b, n_points, 2)
Returns
-------
tf.Tensor. shape = (b, s, s)
"""
batch_size = input.size(0)
input_height = input.size(1)
input_width = input.size(2)
n_coords = coords.size(1)
# coords = torch.clamp(coords, 0, input_size - 1)
coords = torch.cat((torch.clamp(coords.narrow(2, 0, 1), 0, input_height - 1), torch.clamp(coords.narrow(2, 1, 1), 0, input_width - 1)), 2)
assert (coords.size(1) == n_coords)
coords_lt = coords.floor().long()
coords_rb = coords.ceil().long()
coords_lb = torch.stack([coords_lt[..., 0], coords_rb[..., 1]], 2)
coords_rt = torch.stack([coords_rb[..., 0], coords_lt[..., 1]], 2)
idx = th_repeat(torch.arange(0, batch_size), n_coords).long()
idx = Variable(idx, requires_grad=False)
if input.is_cuda:
idx = idx.cuda()
def _get_vals_by_coords(input, coords):
indices = torch.stack([
idx, th_flatten(coords[..., 0]), th_flatten(coords[..., 1])
], 1)
inds = indices[:, 0]*input.size(1)*input.size(2)+ indices[:, 1]*input.size(2) + indices[:, 2]
vals = th_flatten(input).index_select(0, inds)
vals = vals.view(batch_size, n_coords)
return vals
vals_lt = _get_vals_by_coords(input, coords_lt.detach())
vals_rb = _get_vals_by_coords(input, coords_rb.detach())
vals_lb = _get_vals_by_coords(input, coords_lb.detach())
vals_rt = _get_vals_by_coords(input, coords_rt.detach())
coords_offset_lt = coords - coords_lt.type(coords.data.type())
vals_t = coords_offset_lt[..., 0]*(vals_rt - vals_lt) + vals_lt
vals_b = coords_offset_lt[..., 0]*(vals_rb - vals_lb) + vals_lb
mapped_vals = coords_offset_lt[..., 1]* (vals_b - vals_t) + vals_t
return mapped_vals
def th_repeat(a, repeats, axis=0):
"""Torch version of np.repeat for 1D"""
assert len(a.size()) == 1
return th_flatten(torch.transpose(a.repeat(repeats, 1), 0, 1))
def th_flatten(a):
"""Flatten tensor"""
return a.contiguous().view(a.nelemen