
MobileNet論文詳解
轉載於:https://blog.csdn.net/T800GHB/article/details/78879612
文章全名:MobileNets: Efficient Convolutional Neural Networks for MobileVision Applications
1.原文連結
論文地址:https://arxiv.org/abs/1704.04861
2.簡介
深度學習在影象分類,目標檢測和影象分割等任務表現出了巨大的優越性。
但是伴隨著模型精度的提升是計算量,儲存空間以及能耗方面的巨大開銷,對於移動或車載應用都是難以接受的。
之前的一些模型小型化工作是將焦點放在模型的尺寸上。
因此,在小型化方面常用的手段有:
(1)卷積核分解,使用1×N和N×1的卷積核代替N×N的卷積核
(2)使用bottleneck結構,以SqueezeNet為代表
(3)以低精度浮點數儲存,例如Deep Compression
(4)冗餘卷積核剪枝及哈弗曼編碼
MobileNet進一步深入的研究了depthwise separable convolutions使用方法後設計出MobileNet,depthwiseseparable convolutions的本質是冗餘資訊更少的稀疏化表達。在此基礎上給出了高效模型設計的兩個選擇:寬度因子(width multiplier)和解析度因子(resolutionmultiplier);通過權衡大小、延遲時間以及精度,來構建規模更小、速度更快的MobileNet。Google團隊也通過了多樣性的實驗證明了MobileNet作為高效基礎網路的有效性。
3.網路結構
3.1 Deep-wise卷積
MobileNet使用了一種稱之為deep-wise的卷積方式來替代原有的傳統3D卷積,減少了卷積核的冗餘表達。在計算量和引數數量明顯下降之後,卷積網路可以應用在更多的移動端平臺。
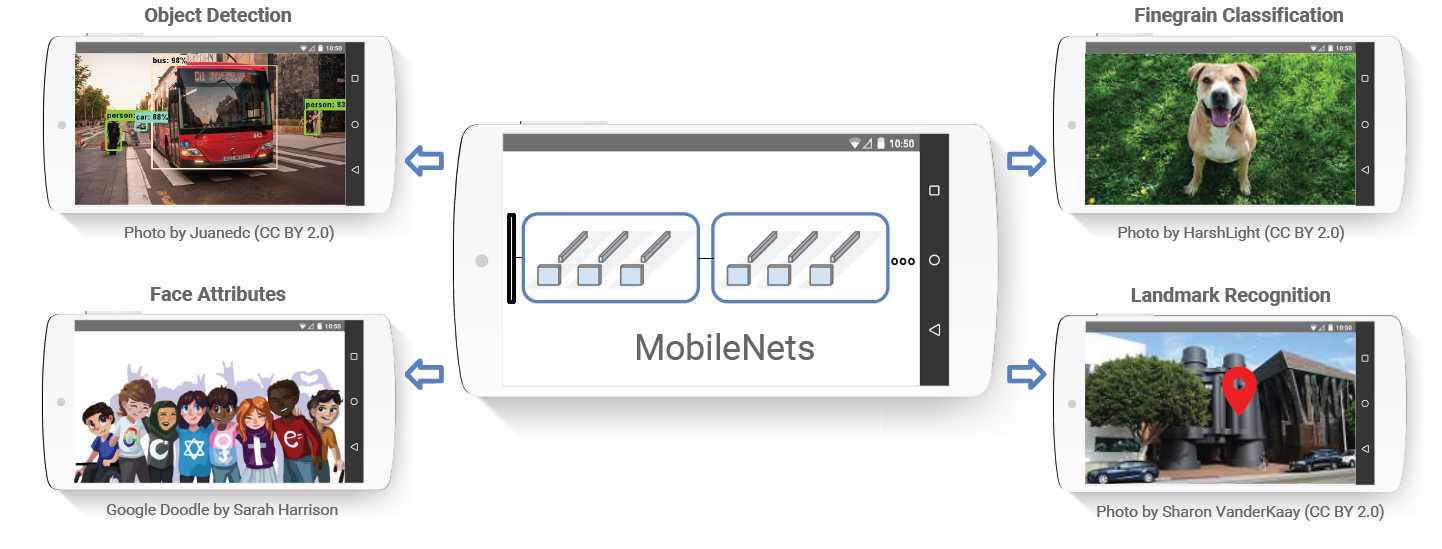
傳統的3D卷積使用一個和輸入資料通道數相同的卷積核在逐個通道卷積後求和最後得出一個數值作為結果,計算量為
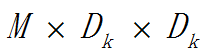
其中M為輸入的通道數,Dk為卷積核的寬和高
一個卷積核處理輸入資料時的計算量為(有Padding):
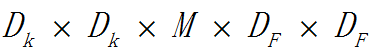
其中DF為輸入的寬和高
在某一層如果使用N個卷積核,這一個卷積層的計算量為:
如果使用deep-wise方式的卷積核,我們會首先使用一組二維的卷積核,也就是卷積核的通道數為1,每次只處理一個輸入通道的,這一組二維卷積核的數量是和輸入通道數相同的。
在使用逐個通道卷積處理之後,再使用3D的1*1卷積核來處理之前輸出的特徵圖,將最終輸出通道數變為一個指定的數量,論文原圖說明的比較到位,請看
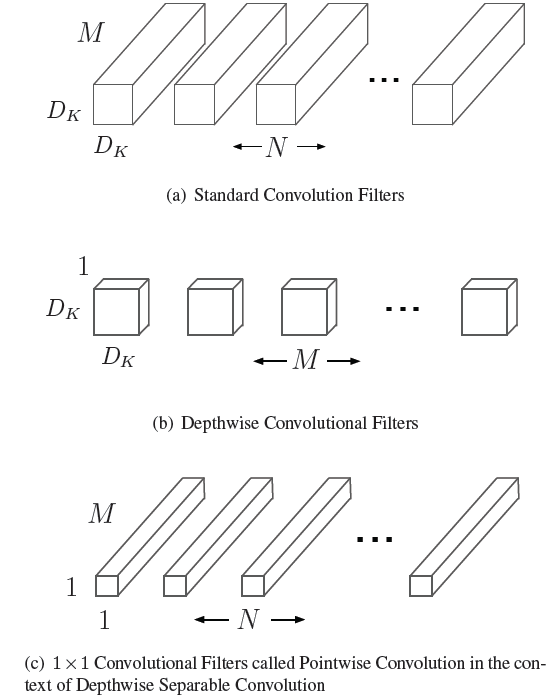
圖a中的卷積核就是最常見的3D卷積,替換為deep-wise方式:一個逐個通道處理的2D卷積(圖b)結合3D的1*1卷積(圖c)
從理論上來看,一組和輸入通道數相同的2D卷積核的運算量為:
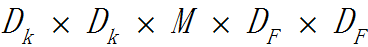
3D的1*1卷積核的計算量為:
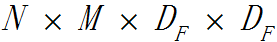
因此這種組合方式的計算量為:
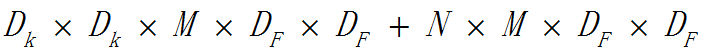
deep-wise方式的卷積相比於傳統3D卷積計算量為:
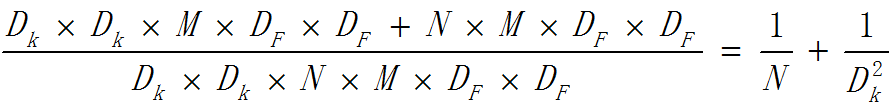
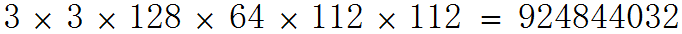
如果將傳統3D卷積替換為deep-wise結合1x1方式的卷積,計算量為:
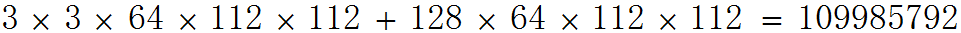
可見在這一層裡,MobileNet所採用卷積方式的計算量與傳統卷積計算量的比例為:
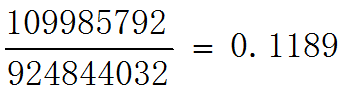
3.2 網路結構
傳統的3D卷積常見的使用方式如下圖左側所示,deep-wise卷積的使用方式如下圖右邊所示。
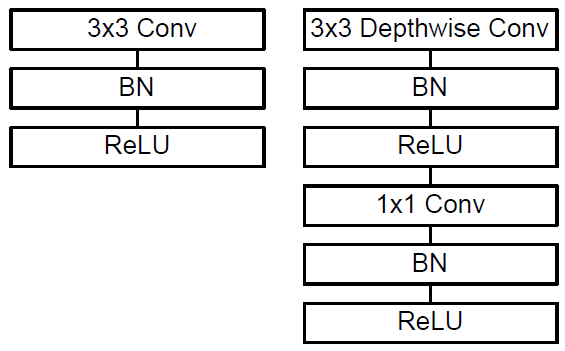
從圖中可以看出,deep-wise的卷積和後面的1x1卷積被當成了兩個獨立的模組,都在輸出結果的部分加入了Batch Normalization和非線性啟用單元。
Deep-wise結合1x1的卷積方式代替傳統卷積不僅在理論上會更高效,而且由於大量使用1x1的卷積,可以直接使用高度優化的數學庫來完成這個操作。以Caffe為例,如果要使用這些數學庫,要首先使用im2col的方式來對資料進行重新排布,從而確保滿足此類數學庫的輸入形式;但是1x1方式的卷積不需要這種預處理。
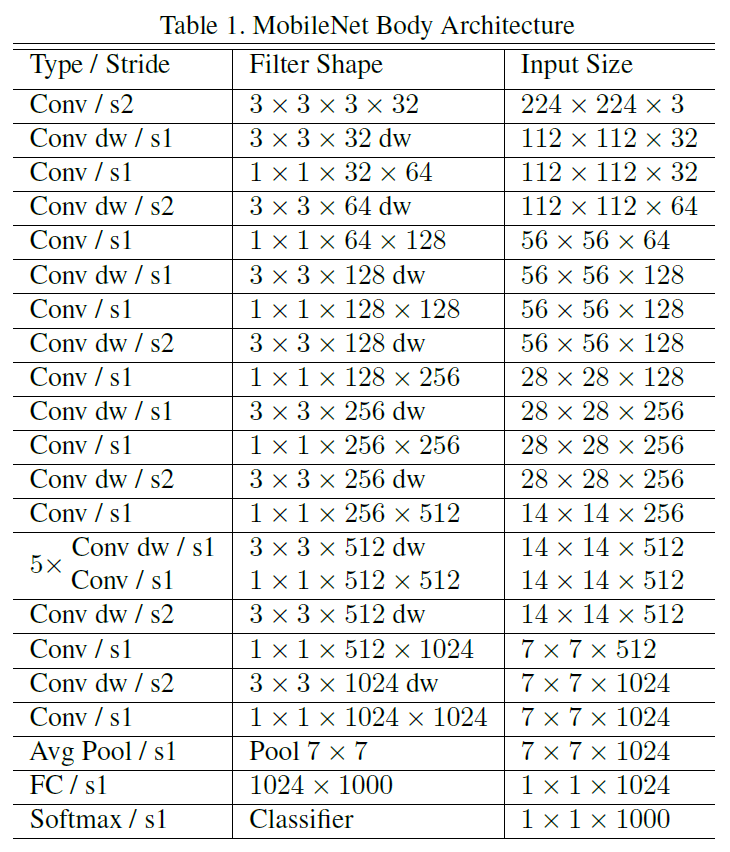
在MobileNet中,有95%的計算量和75%的引數屬於1x1卷積。下圖為MobileNet在ImageNet上訓練時使用的網路架構(表格中含有dw的就表示這一層採用了deep-wise結合1x1的方式)
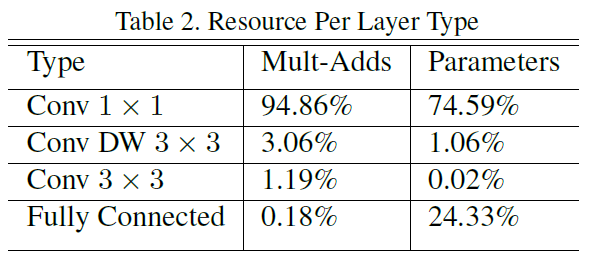
下圖為MobileNet對於不同結構單元在計算量和引數數量方面的統計。
3.3 訓練細節
作者基於TensorFlow訓練MobileNet,使用RMSprop演算法優化網路引數。考慮到較小的網路不會有嚴重的過擬合問題,因此沒有做大量的資料增強工作。在訓練過程中也沒有采用訓練大網路時的一些常用手段,例如:輔助損失函式,隨機影象裁剪輸入等。
deep-wise卷積核含有的引數較少,作者發現這部分最好使用較小的weight decay或者不使用weightdecay。
3.4 寬度因子和解析度因子
儘管標準的MobileNet在計算量和模型尺寸方面具備了很明顯的優勢,但是,在一些對執行速度或記憶體有極端要求的場合,還需要更小更快的模型,如何能夠在不重新設計模型的情況下,以最小的改動就可以獲得更小更快的模型呢?本文中提出的寬度因子(width multiplier)和解析度因子(resolutionmultiplier)就是解決這些問題的配置引數。
寬度因子α是一個屬於(0,1]之間的數,附加於網路的通道數。簡單來說就是新網路中每一個模組要使用的卷積核數量相較於標準的MobileNet比例。對於deep-wise結合1x1方式的卷積核,計算量為:
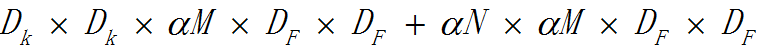
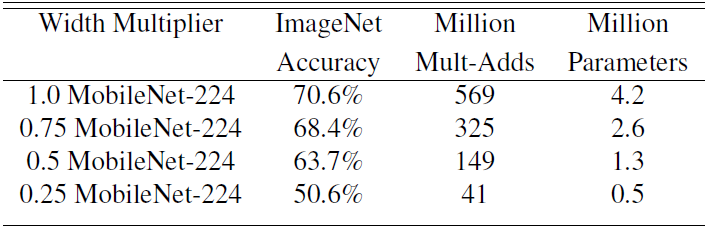
α常用的配置為1,0.75,0.5,0.25;當α等於1時就是標準的MobileNet。通過引數α可以非常有效的將計算量和引數數量約減到α的平方倍。
通過下圖可以看出使用α係數進行網路引數的約減時,在ImageNet上的準確率,為準確率,引數數量和計算量之間的權衡提供了參考(每一個項中最前面的數字表示α的取值)。
解析度因子β的取值範圍在(0,1]之間,是作用於每一個模組輸入尺寸的約減因子,簡單來說就是將輸入資料以及由此在每一個模組產生的特徵圖都變小了,結合寬度因子α,deep-wise結合1x1方式的卷積核計算量為:
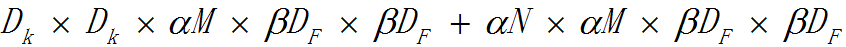
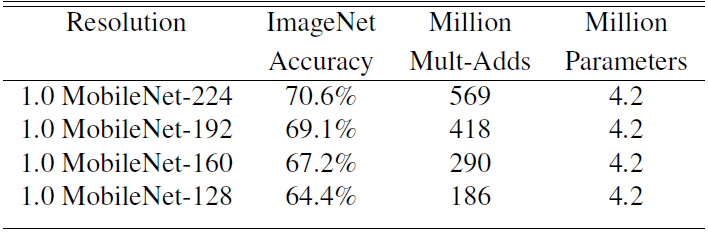
下圖為使用不同的β係數作用於標準MobileNet時,對精度和計算量以的影響(α固定)
要注意再使用寬度和解析度引數調整網路結構之後,都要從隨機初始化重新訓練才能得到新網路。
4.實驗結果
為了驗證MobileNet作為基礎網路的有效性,Google團隊使用MobileNet在不同的視覺識別任務上組為基礎網路都表現出了優異的效能。
任務1:基礎網路
MobileNet極大地降低了網路引數數量和計算量,但是相比起經典的基礎網路,其精度並未明顯的降低
如下圖所示,與VGG相比,在ImageNet分類任務上的精度差距較小

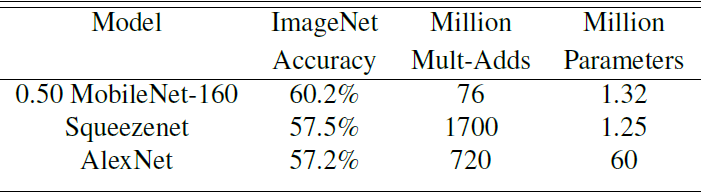
如下圖所示,與經典的小型網路SqueezeNet相比,在精度和計算量方面都有明顯提升
任務2:精細分類
在 Stanford Dogs 資料集上訓練MobileNet 進行精細分類。結果下圖所示,MobileNet 在大大減少計算量和減小模型大小的情況下分類精度接近於InceptionV3。

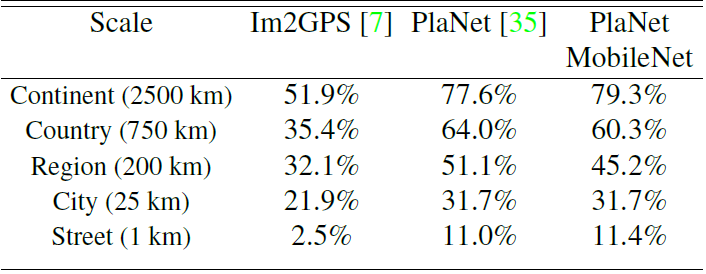
任務3:大規模地理定位
PlaNet 用於分辨一張照片拍攝於哪個地理位置的分類問題任務。基本思想是將地球劃分為成網格,用數量巨大的有地理標記的照片訓練網路。PlaNet 可以較為準確的將各種各樣的照片標記地理位置,代表了這個領域的頂級水平。
使用 MobileNet 作為基礎網路在相同的資料上重新訓練 PlaNet。如下圖所示,MobileNet作為基礎網路的PlaNet與經典 PlaNet 相比,規模小了很多,效能稍有降低,但比 Im2GPS 各方面更佳。
任務4:人臉屬性提取
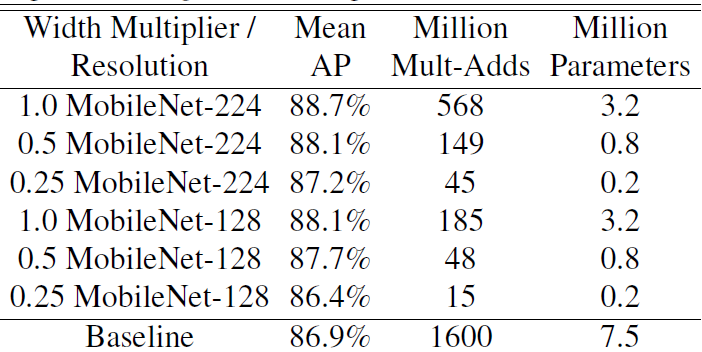
MobileNet 的一個使用情景是壓縮具有未知或複雜訓練程式的大型系統。在人臉屬性分類任務中,本文證明了 MobileNet 與 distillation間的協同關係,這是網路的一種知識遷移技術。本文在 YFCC100M 多屬性資料集上訓練。
使用 MobileNet 架構提取一個人臉屬性分類器。distillation是通過訓練分類器模擬一個更大的模型的輸出,而非人工標註標籤工作,因此能夠從大型(可能是無限大)未標記資料集訓練。結合 distillation 的可擴充套件性和MobileNet 的簡約引數化,相比於一個具有7500萬超引數和16億 Mult-Adds 的大型人臉屬性分類器,終端系統不僅不需要正則化,而且表現出更好的效能。結果如下圖所示
任務5:目標檢測
MobileNet 可以作為一個有效的基網路部署在目標檢測系統上。基於2016 COCO 資料集,比較了在 COCO 資料上訓練的 MobileNet 進行目標檢測的結果。下圖列出了在 Faster-RCNN 和 SSD 框架下,MobileNet,VGG 以及 Inception V2 作為基礎網路的對比結果。在不同而檢測框架和輸入尺寸設定下,以MobileNet為基礎網路的檢測框架表現出了不明顯遜色於兩個基礎網路的效能,而且在計算量和模型尺寸方面有較大優勢。

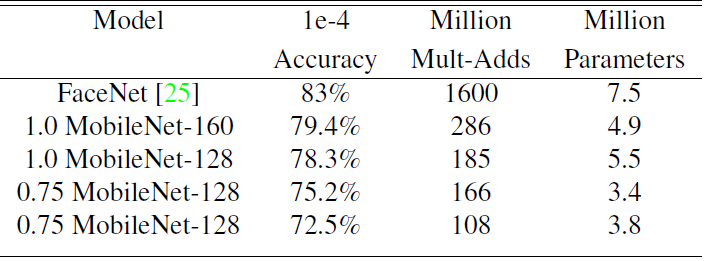
任務6:人臉識別
FaceNet 模型是目前頂級水平的人臉識別模型,它基於 triplet loss 構建 faceEmbedding。為了能夠在移動裝置上執行 FaceNet 模型,使用 distillation來最小化訓練資料上 FaceNet和 MobileNet 輸出的方差。下圖列出了輸入尺寸較小的MobileNet在此任務上的效能表現,可以看出主要還是在沒有過分損失精度的情況下,運算量大大減少。
5.總結
MobileNet在計算量,儲存空間和準確率方面取得了非常不錯的平衡。與VGG16相比,在很小的精度損失情況下,將運算量減小了30倍。通過實驗結果,我們認為MobileNet的設計思想會在自動駕駛汽車,機器人和無人機等對實時性、儲存空間、能耗有嚴格要求的終端智慧應用中發揮顯著作用。