
圖及其衍生演算法(Graphs and graph algorithms)
1. 圖的相關概念
樹是一種的圖,相比樹,圖更能用來表示現實世界中的的實體,如路線圖,網路節點圖,課程體系圖等,一旦能用圖來描述實體,能模擬和解決一些非常複雜的任務。圖的相關概念和詞彙如下:
頂點vertex:圖的節點
邊Edge:頂點間的連線,若邊具有方向時,組成有向圖(directed graph)
權重weight:從一個頂點到其他不同頂點的距離不一樣,因此邊具有權重,來表示不同的距離
路徑path:從一個頂點到另一個的所有邊的集合
迴路cycle:在有向圖中,從一個頂點開始,最後又回到起始頂點的路徑為一個迴路
圖可以表示為G={V,E},其中V為頂點的集合,E為邊的集合,如下圖所示:
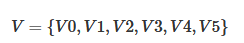
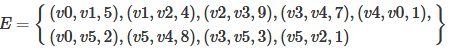
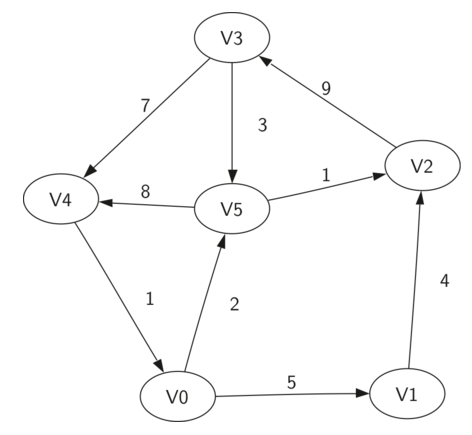
2,圖的實現
圖的相關操作如下:
Graph() #建立圖 addVertex(vert) #新增頂點 addEdge(fromVert, toVert) #新增邊 addEdge(fromVert, toVert, weight) #新增邊及其權重 getVertex(vertKey) #獲取某個頂點getVertices() #獲取所有頂點 in #判斷是否包括某個頂點
可以通過鄰接矩陣(adjacency matrix)或領接表(adjacency list)來實現圖。鄰接矩陣表示圖的結構如下,圖中的數字表示兩個頂點相連,且邊的權重為該值。可以發現鄰接矩陣更加適合於邊較多的圖,不然會造成記憶體空間的浪費。
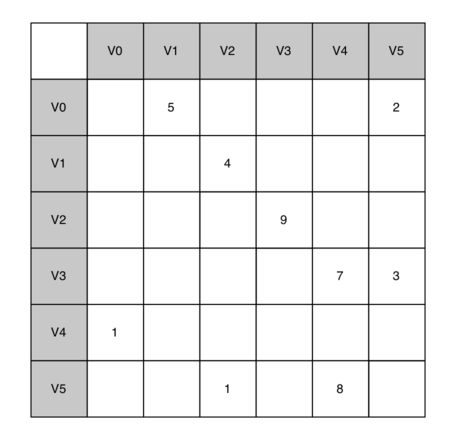
鄰接表表示圖的結構如下,一個主列表中包含圖的所有頂點,每個頂點又各包含列表記錄與其相連的邊。可以發現鄰接表更適合邊較少的圖。
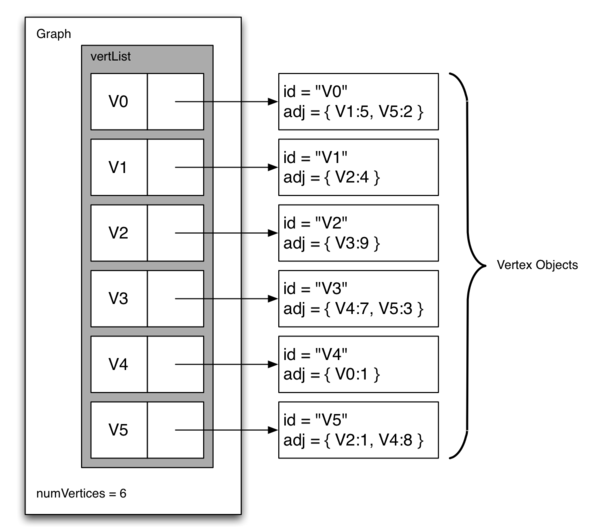
python實現鄰接表程式碼如下:


#coding:utf-8 class Vertex(object): def __init__(self,key): self.id=key self.connectedTo={} def __str__(self): return str(self.id) + "connected to" +str([x.id for x in self.connectedTo]) #nbr為vertex物件 def addNeighbor(self,nbr,weight=0): self.connectedTo[nbr]=weight def getConnections(self): return self.connectedTo.keys() def getId(self): return self.id def getWeight(self,nbr): return self.connectedTo[nbr] class Graph(object): def __init__(self): self.vertList = {} self.numVertices = 0 def addVertex(self,key): newVertex = Vertex(key) self.vertList[key]=newVertex self.numVertices +=1 return newVertex def getVertex(self,key): if key in self.vertList: return self.vertList[key] else: return None def __contains__(self, key): return key in self.vertList #fromVert,toVert為起始和終止節點的key def addEdge(self,fromVert,toVert,weight=0): if fromVert not in self.vertList: self.addVertex(fromVert) if toVert not in self.vertList: self.addVertex(toVert) self.vertList[fromVert].addNeighbor(self.vertList[toVert],weight) def getVertices(self): return self.vertList.keys() def __iter__(self): return iter(self.vertList.values()) if __name__ == '__main__': g = Graph() for i in range(6): g.addVertex(i) g.addEdge(0, 1, 5) g.addEdge(0, 5, 2) g.addEdge(1, 2, 4) g.addEdge(2, 3, 9) g.addEdge(3, 4, 7) g.addEdge(3, 5, 3) g.addEdge(4, 0, 1) g.addEdge(5, 4, 8) g.addEdge(5, 2, 1) for v in g: for w in v.getConnections(): print("( %s , %s )" % (v.getId(), w.getId()))View Code
3.圖的應用
3.1 Word ladder problem
word ladder規則:從單詞‘FOOL’變為單詞‘SAGE’,每次只能改變一個字母,且改變一個字母后的單詞必須存在,求可能的變化路徑。
一個路徑示意:FOOL POOL POLL POLE PALE SALE SAGE
解決思路:
1,建立圖,以單詞為頂點,若兩個單詞間只相差一個字母,則兩個單詞間有一條邊(雙向的邊)
2,對圖進行寬度優先搜尋,找到合適的路徑
建立圖:
下載四個字母的單詞,構造成一行一個單詞的文字檔案(大概5200個單詞)。按照下面的格式構造一個字典,方塊中的_OPE為鍵,其對應的單片語成一個列表,為字典的值,對每一個單詞,都可以構造如下四個這樣的鍵值對。然後再根據字典建立圖。

上述過程,用python程式碼實現如下:(由於資料量較大,構建圖過程中可能出現memory error)
#coding:utf-8 from graphDemo import Graph,Vertex def buildGraph(): with open('fourLetters.txt', 'r') as f: lines = f.readlines() d={} for line in lines: word = line.strip() #刪除換行符 for i in range(len(word)): label = word[:i]+'_'+word[i+1:] if label in d: d[label].append(word) else: d[label]=[word] #print d.keys() g = Graph() for x in d.keys(): for y in d.keys(): if x!=y: g.addEdge(x,y) return gView Code
寬度優先搜尋(breadth first search,BFS):即先搜尋同級的頂點,再搜尋下一級的頂點。程式碼中引入了佇列Queue,並用三種顏色標記頂點的狀態,白色表示頂點未被搜尋,灰色表示頂點被搜尋,且被放入了佇列中,黑色表示頂點被搜尋,且其所有下一級頂點都被加入了佇列中,如下圖所示。
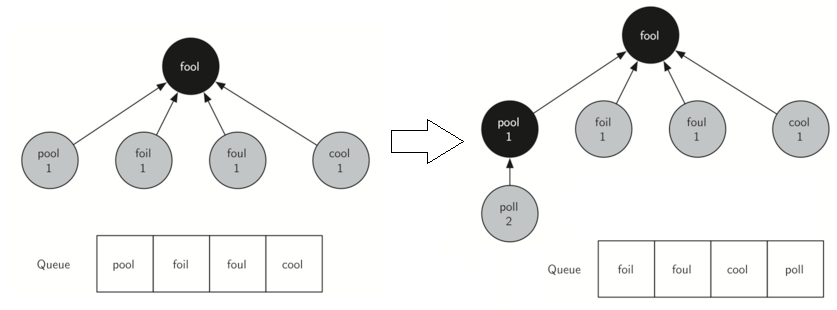
用python實現寬度優先搜尋,並尋找從FOOL 到SAGE的最短路徑,程式碼如下:
from graphDemo import Graph,Vertex from queueDemo import Queue #class Vertex(object): # def __init__(self,key): # self.id=key # self.connectedTo={} # self.color = 'white' # self.distance = None # self.predecessor = None # # def __str__(self): # return str(self.id) + "connected to" +str([x.id for x in self.connectedTo]) # # #nbr為vertex物件 # def addNeighbor(self,nbr,weight=0): # self.connectedTo[nbr]=weight # # def getConnections(self): # return self.connectedTo.keys() # # def getId(self): # return self.id # # def getWeight(self,nbr): # return self.connectedTo[nbr] # # def setColor(self,color): # self.color = color # # def getColor(self): # return self.color # # def setDistance(self,distance): # self.distance = distance # # def getDistance(self): # return self.distance # # def setPred(self,pred): # self.predecessor = pred # # def getPred(self): # return self.predecessor def buildGraph(): with open('fourLetters.txt', 'r') as f: lines = f.readlines() d={} for line in lines: word = line.strip() #刪除換行符 for i in range(len(word)): label = word[:i]+'_'+word[i+1:] if label in d: d[label].append(word) else: d[label]=[word] #print d.keys() g = Graph() for x in d.keys(): for y in d.keys(): if x!=y: g.addEdge(x,y) return g def bfs(g,start): start.setDistance(0) start.setPred(None) vertQueue = Queue() vertQueue.enqueue(start) while vertQueue.size()>0: currentVert = vertQueue.dequeue() for vert in currentVert.getConnections(): if (vert.getColor()=='white'): vert.setDistance(currentVert.getDistance()+1) vert.setColor('gray') vert.setPred(currentVert) vertQueue.enqueue(vert) currentVert.setColor('black') def traverse(y): x = y while (x!=None): print x.getId() x = x.getPred() if __name__ =='__main__': g = buildGraph() start = g.getVertex('FOOL') bfs(g,start) end =g.getVertex('SAGE') traverse(end)View Code
另外,上述程式碼中寬度優先搜尋的複雜度為O(V+E),V為頂點的數量,E為邊的數量
3.2 Knight‘s tour problem (騎士跳馬棋遊歷問題)
knight's tour問題描述:在國際象棋棋盤上(8*8方格),騎士只能走“日字”路線(和象棋中馬一樣),騎士如何才能不重複的走遍整個棋盤?
解決思路:
1,建立圖:將棋盤中的每個方格編號,以方格做為頂點,建立圖。對於每個頂點n,騎士若能從n跳到下一個頂點m,則n和m間建立邊。
2,對圖進行深度優先搜尋(depth first search, DFS)
建立圖:如左圖的5*5棋盤,編號0-24,騎士現在所在位置為12,右圖中構建了頂點12所有的邊(從12出發,騎士下一步能到達的頂點編號)
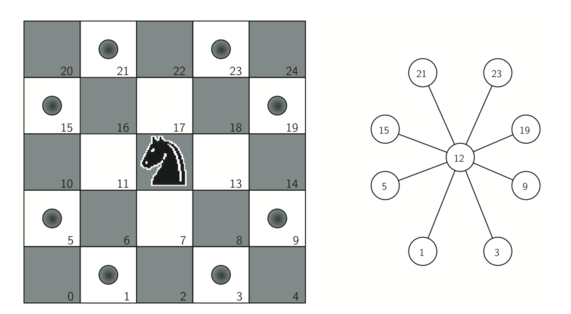
用python實現建立圖的程式碼如下:
#coding:utf-8 from graphDemo import Graph def knightGraph(boardSize): g = Graph() for row in range(boardSize): for col in range(boardSize): nodeID = posToNodeId(row,col,boardSize) #對棋盤每個方格編號 nextMoves= genLegalMoves(row,col,boardSize) #獲取騎士下一步能到達的頂點 for pos in nextMoves: g.addEdge(nodeID,pos) return g def posToNodeId(row,col,size): return row*size+col def genLegalMoves(row,col,size): nextMoves=[] moveOffset = [(-1,2),(1,2),(-2,1),(2,1),(-2,-1),(2,-1),(-1,-2),(1,-2)] for i in moveOffset: x = row+i[0] y = col+i[1] if legalCoord(x,size) and legalCoord(y,size): #判斷該座標是否在棋盤上 nodeId = posToNodeId(x,y,size) nextMoves.append(nodeId) return nextMoves def legalCoord(x,size): if x>=0 and x<size: return True else: return False if __name__ == '__main__': g = knightGraph(5) print g.vertList[0].id for vert in g.vertList[0].getConnections(): print vert.idView Code
深度優先搜尋:先找下一級的頂點,再找同級的頂點。此處的問題中,總共有64個節點,若騎士能夠依次不重複的訪問64個節點,便找到了一條成功遍歷的路徑,實現程式碼如下:
def knightTour(n, path, u, limit): ''' :param n: 一遍歷頂點數,初始為0 :param path: 遍歷的路徑 :param u: 當前頂點 :param limit:限制訪問頂點數 :return: ''' u.setColor('gray') path.append(u) if n < limit: nextVerts = list(u.getConnections()) i = 0 done = False while i < len(nextVerts) and not done: if nextVerts[i].getColor() == 'white': done = knightTour(n + 1, path, nextVerts[i], limit) i = i + 1 if not done: path.pop() u.setColor('white') else: done = True return doneView Code
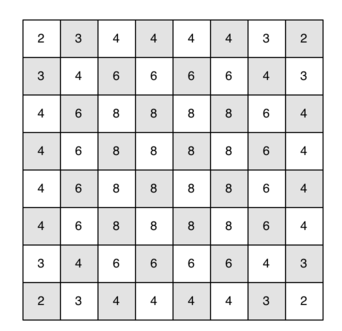
上述程式碼中的深度遍歷中,複雜發為O(kN),K為常數,N為頂點個數,隨著頂點數增加,演算法複雜度指數級增長,對於5*5的方格能較快完成,而對於8*8的方格,得幾小時才能完成演算法。可以對深度優先演算法進行輕微的改進,對於棋盤上所有頂點,其邊的數量分佈如下圖所示,可以發現,棋盤邊緣的頂點邊數較少,棋盤中央的頂點邊數多,若先訪問棋盤邊緣的頂點,再訪問棋盤中央的頂點,能降低演算法複雜度,相應程式碼如下:
def knightTour(n, path, u, limit): ''' :param n: 一遍歷頂點數,初始為0 :param path: 遍歷的路徑 :param u: 當前頂點 :param limit:限制訪問頂點數 :return: ''' u.setColor('gray') path.append(u) if n < limit: # nextVerts = list(u.getConnections()) nextVerts = orderByAvail(u) i = 0 done = False while i < len(nextVerts) and not done: if nextVerts[i].getColor() == 'white': done = knightTour(n + 1, path, nextVerts[i], limit) i = i + 1 if not done: path.pop() u.setColor('white') else: done = True return done def orderByAvail(n): resList = [] for v in n.getConnections(): if v.getColor() == 'white': c = 0 for w in v.getConnections(): if w.getColor() == 'white': c = c + 1 resList.append((c,v)) resList.sort(key=lambda x: x[0]) return [y[1] for y in resList]View Code
上述騎士遊歷問題中的深度優先搜尋演算法是一種特殊的深度優先搜尋,對於普通的問題,深度優先搜尋的程式碼如下:
#coding:utf-8 from graphDemo import Graph class DFSGraph(Graph): def __init__(self): super(DFSGraph,self).__init__() self.time = 0 def dfs(self): for vert in self: self.dfsVisit(vert) def dfsVisit(self,startVert): startVert.setColor('gray') self.time += 1 #注意self.time是DFSGraph的屬性,不是Vertex的 startVert.setDiscovery(self.time) for vert in startVert.getConnections(): if vert.getColor()=='white': vert.setPred(startVert) self.dfsVisit(vert) startVert.setColor('black') self.time += 1 startVert.setFinish(self.time) def traverse(y): x=y while x!=None: print x.getId() x = x.getPred() if __name__ == '__main__': g = DFSGraph() for i in range(6): g.addVertex(i) g.addEdge(0, 1, 5) g.addEdge(0, 5, 2) g.addEdge(1, 2, 4) g.addEdge(2, 3, 9) g.addEdge(3, 4, 7) g.addEdge(3, 5, 3) g.addEdge(4, 0, 1) g.addEdge(5, 4, 8) g.addEdge(5, 2, 1) g.dfs() traverse(g.getVertex(1))View Code
上述DFS的複雜度和BFS一樣,也為O(V+E)
4.拓撲排序(Topological sorting)
拓撲排序適用於有向無環圖(圖中不存在迴路),表示各個事件(頂點)的線性執行順序,如圖中若存在邊(v,w),則事件v在w之前發生。
拓撲排序的執行過程如下:
1,先對圖進行深度優先搜尋,計算每個頂點的finish time
2,根據finish time,對頂點進行降序排列,並存儲在一個列表中,返回列表即為拓撲排序結果
如下圖是一張表示煎餅過程的有向無環圖,箭頭表示執行先後順序:
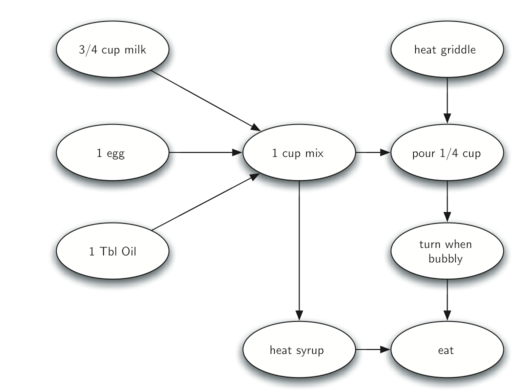
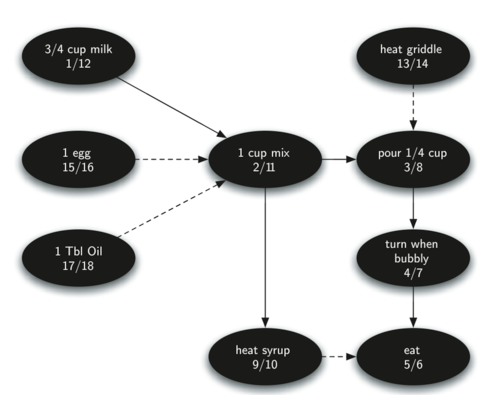
若要知道整個煎餅過程的執行流程,可以對上面的圖進行拓撲排序,計算的時間(discovery time/ finish time)和最後得到執行流程如下,即越晚結束的事件(finish time越大),應先執行。

5.最短路徑演算法
5.1迪傑斯特拉演算法(Dijkstra's Algorithm)
Dijkstra演算法:尋找最短路徑演算法之一,即在邊的權值不為負的有向圖中,尋找任意一點到其他任意結點(在兩點相互聯通的情況下)之間的最小路徑。
python實現程式碼如下:
#coding:utf-8 from graphDemo import Graph from binaryHeap import BinaryHeap import sys class PriorityQueue(BinaryHeap): def decreaseKey(self,item,cost): i=1 done=False while i<=self.size and not done: if self.heapList[i][1]==item: #先找到該元素,再將元素向上移 self.heapList[i]=(cost,item) self._percUp(i) done = True i = i+1 def dijkstra(aGraph,start): for vert in aGraph: vert.setDistance(sys.maxint) start.setDistance(0) q = PriorityQueue() q.buildHeap([(v.getDistance(),v) for v in aGraph]) #元組做為最小堆(優先佇列)的元素 while q.size>0: #元組進行比較時,先比較第一個元素,所以距離做為元素第一個值,距離相等時演算法有問題? currentVert = q.delMin()[1] for nextVert in currentVert.getConnections(): newDistance = currentVert.getDistance()+currentVert.getWeight(nextVert) if newDistance<nextVert.getDistance(): nextVert.setDistance(newDistance) nextVert.setPred(currentVert) q.decreaseKey(nextVert,newDistance) if __name__ == '__main__': g = Graph() for i in range(6): g.addVertex(i) g.addEdge(0, 1, 5) g.addEdge(0, 5, 2) g.addEdge(1, 2, 4) g.addEdge(2, 3, 9) g.addEdge(3, 4, 7) g.addEdge(3, 5, 3) g.addEdge(4, 0, 1) g.addEdge(5, 4, 8) g.addEdge(5, 2, 1) dijkstra(g, g.getVertex(5)) for vert in g: print vert.getId(),vert.getDistance()View Code
Dijkstra演算法的複雜度為O((V+E)*log V):delMin()複雜度為O(log V),共V個元素,因此複雜度為O(V*log V);decreaseKey()複雜度為O(log V),共E條邊,複雜度為O(E*log V),兩者相加O((V+E)*log V)。
5.2 普里姆演算法(Prim's Algorithm)
Prim's Algorithm:又叫最小生成樹演算法(Minimum spanning tree algorithm)
(步驟:在帶權連通圖g=(V,E),從圖中某一頂點a開始,此時集合U={a},重複執行下述操作:在所有u∈U,w∈V-U的邊(u,w)∈E中找到一條權值最小的邊,將(u,w)這條邊加入到已找到邊的集合,並且將點w加入到集合U中,當U=V時,就找到了這顆最小生成樹。)
python實現程式碼如下:
#coding:utf-8 from graphDemo import Graph from binaryHeap import BinaryHeap import sys class PriorityQueue(BinaryHeap): def decreaseKey(self,item,cost): i=1 done=False while i<=self.size and not done: if self.heapList[i][1]==item: #先找到該元素,再將元素向上移 self.heapList[i]=(cost,item) self._percUp(i) done = True i = i+1 def __contains__(self, item): i=1 found = False while i <= self.size and not found: if self.heapList[i][1] == item: found=True i = i+1 return found def prim(aGraph,start): for vert in aGraph: vert.setDistance(sys.maxint) q = PriorityQueue() start.setDistance(0) q.buildHeap([(v.getDistance(), v) for v in aGraph]) while q.size>0: currentVert = q.delMin()[1] for nextVert in currentVert.getConnections(): newCost = currentVert.getWeight(nextVert) # 每次從佇列中,挑取邊cost最小的點 if nextVert in q and newCost < nextVert.getDistance(): nextVert.setDistance(newCost) nextVert.setPred(currentVert) q.decreaseKey(nextVert, newCost) if __name__ == '__main__': g = Graph() for i in range(6): g.addVertex(i) g.addEdge(0, 1, 5) g.addEdge(0, 5, 2) g.addEdge(1, 2, 4) g.addEdge(2, 3, 9) g.addEdge(3, 4, 7) g.addEdge(3, 5, 3) g.addEdge(4, 0, 1) g.addEdge(5, 4, 8) g.addEdge(5, 2, 1) prim(g, g.getVertex(5)) for vert in g: print vert.getId(), vert.getPred()View Code
參考:http://interactivepython.org/runestone/static/pythonds/Graphs/toctree.html