
a*演算法解讀
A*演算法
Dijkstra演算法從物體所在的初始點開始,訪問圖中的結點。它迭代檢查待檢查結點集中的結點,並把和該結點最靠近的尚未檢查的結點加入待檢查結點集。該結點集從初始結點向外擴充套件,直到到達目標結點。Dijkstra演算法保證能找到一條從初始點到目標點的最短路徑,只要所有的邊都有一個非負的代價值。
最佳優先搜尋(BFS)演算法按照類似的流程執行,不同的是它能夠評估(稱為啟發式的)任意結點到目標點的代價。與選擇離初始結點最近的結點不同的是,它選擇離目標最近的結點。BFS不能保證找到一條最短路徑。然而,它比Dijkstra演算法快的多,因為它用了一個啟發式函式(heuristic function)快速地導向目標結點。
然而,這兩個例子都僅僅是最簡單的情況——地圖中沒有障礙物,最短路徑是直線的。現在我們來考慮前邊描述的凹型障礙物。Dijkstra演算法執行得較慢,但確實能保證找到一條最短路徑。 另一方面,BFS執行得較快,但是它找到的路徑明顯不是一條好的路徑。
A*把Dijkstra演算法(靠近初始點的結點)和BFS演算法(靠近目標點的結點)的資訊塊結合起來,在討論A*的標準術語中,g(n)表示從初始結點到任意結點n的代價,h(n)表示從結點n到目標點的啟發式評估代價(heuristic estimated cost)。A*權衡這兩者。每次進行主迴圈時,它檢查f(n)最小的結點n,其中f(n) = g(n) + h(n)。
搜尋區域(The Search Area)
我們假設某人要從 A 點移動到 B 點,但是這兩點之間被一堵牆隔開。如圖 1 ,綠色是 A ,紅色是 B ,中間藍色是牆。
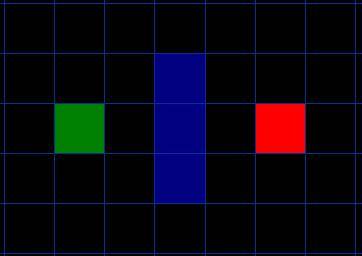
1.把要搜尋的區域劃分成了正方形的格子,這是尋路的第一步,簡化搜尋區域,這個特殊的方法把我們的搜尋區域簡化為了 2 維陣列。陣列的每一項代表一個格子,它的狀態就是可走 (walkalbe) 和不可走 (unwalkable) 。通過計算出從 A 到 B需要走過哪些方格,就找到了路徑。一旦路徑找到了,人物便從一個方格的中心移動到另一個方格的中心,直至到達目的地。
方格的中心點我們成為“節點 (nodes) ”。因為我們有可能把搜尋區域劃為為其他多變形而不是正方形,例如可以是六邊形,矩形,甚至可以是任意多變形。而節點可以放在任意多邊形裡面,可以放在多變形的中心,也可以放在多邊形的邊上。我們使用這個系統,因為它最簡單。
開始搜尋(Starting the Search)
一旦我們把搜尋區域簡化為一組可以量化的節點後,我們下一步要做的便是查詢最短路徑。在 A* 中,我們從起點開始,檢查其相鄰的方格,然後向四周擴充套件,直至找到目標。
我們這樣開始我們的尋路旅途:
1. 從起點 A 開始,並把它就加入到一個由方格組成的 open list( 開放列表 ) 中。這個 open list 有點像是一個購物單。當然現在 open list 裡只有一項,它就是起點 A ,後面會慢慢加入更多的項。 Open list 裡的格子是路徑可能會是沿途經過的,也有可能不經過。基本上 open list 是一個待檢查的方格列表。
2. 檢視與起點 A 相鄰的方格 ( 忽略其中牆壁所佔領的方格,河流所佔領的方格及其他非法地形佔領的方格 ) ,把其中可走的 (walkable) 或可到達的 (reachable) 方格也加入到 open list 中。把起點 A 設定為這些方格的父親 (parent node 或 parent square) 。當我們在追蹤路徑時,這些父節點的內容是很重要的。
3. 把 A 從 open list 中移除,加入到 close list( 封閉列表 ) 中, close list 中的每個方格都是現在不需要再關注的。
深綠色的方格為起點,它的外框是亮藍色,表示該方格被加入到了 close list 。與它相鄰的黑色方格是需要被檢查的,他們的外框是亮綠色。每個黑方格都有一個灰色的指標指向他們的父節點,這裡是起點 A 。

下一步,我們需要從 open list 中選一個與起點 A 相鄰的方格,按下面描述的一樣或多或少的重複前面的步驟。
路徑排序(Path Sorting)
計算出組成路徑的方格的關鍵是下面這個等式:
f(n) = g(n) + h(n)
g(n) = 從起點 A 移動到指定方格的移動代價,沿著到達該方格而生成的路徑。
h(n) = 從指定的方格移動到終點 B 的估算成本。這個通常被稱為試探法,有點讓人混淆。因為這是個猜測。直到我們找到了路徑我們才會知道真正的距離,因為途中有各種各樣的東西 ( 比如牆壁,水等 ) 。本教程將教你一種計算 H 的方法。
我們的路徑是這麼產生的:反覆遍歷 open list ,選擇 F 值最小的方格。這個過程稍後詳細描述。我們還是先看看怎麼去計算上面的等式。
g(n) 是從起點A移動到指定方格的移動代價。在本例中,橫向和縱向的移動代價為 10 ,對角線的移動代價為 14 。之所以使用這些資料,是因為實際的對角移動距離是 2 的平方根,或者是近似的 1.414 倍的橫向或縱向移動代價。使用 10 和 14 就是為了簡單起見。既然我們是沿著到達指定方格的路徑來計算 G 值,那麼計算出該方格的 G 值的方法就是找出其父親的 G 值,然後按父親是直線方向還是斜線方向加上 10 或 14 。
有很多方法可以估算 H 值。這裡我們使用 Manhattan (曼哈頓)方法,計算從當前方格橫向或縱向移動到達目標所經過的方格數,忽略對角移動,然後把總數乘以 10 。之所以叫做 Manhattan 方法,是因為這很像統計從一個地點到另一個地點所穿過的街區數,而你不能斜向穿過街區。重要的是,計算 H 是,要忽略路徑中的障礙物。這是對剩餘距離的估算值,而不是實際值,因此才稱為試探法。
把 G 和 H 相加便得到 F 。我們第一步的結果如下圖所示。每個方格都標上了 F , G , H 的值,就像起點右邊的方格那樣,左上角是 F ,左下角是 G ,右下角是 H 。
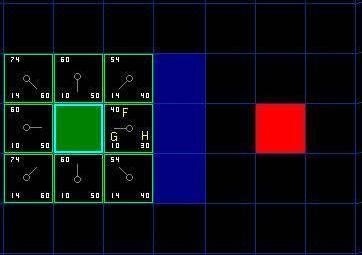
在標有字母的方格, G = 10 。這是因為水平方向從起點到那裡只有一個方格的距離。與起點直接相鄰的上方,下方,左方的方格的 G 值都是 10 ,對角線的方格 G 值都是 14 。H 值通過估算起點於終點 ( 紅色方格 ) 的 Manhattan 距離得到,僅作橫向和縱向移動,並且忽略沿途的牆壁。使用這種方式,起點右邊的方格到終點有 3 個方格的距離,因此 H = 30 。這個方格上方的方格到終點有 4 個方格的距離 ( 注意只計算橫向和縱向距離 ) ,因此 H = 40 。對於其他的方格,你可以用同樣的方法知道 H 值是如何得來的。每個方格的 F 值,再說一次,直接把 G 值和 H 值相加就可以了。
繼續搜尋(Continuing the Search)
為了繼續搜尋,我們從 open list 中選擇 F 值最小的 ( 方格 ) 節點,然後對所選擇的方格作如下操作:
4. 把它從 open list 裡取出,放到 close list 中。
5. 檢查所有與它相鄰的方格,忽略其中在 close list 中或是不可走 (unwalkable) 的方格 ( 比如牆,水,或是其他非法地形 ) ,如果方格不在open lsit 中,則把它們加入到 open list 中。
把我們選定的方格設定為這些新加入的方格的父親。
6. 如果某個相鄰的方格已經在 open list 中,則檢查這條路徑是否更優,也就是說經由當前方格 ( 我們選中的方格 ) 到達那個方格是否具有更小的 G 值。如果沒有,不做任何操作。相反,如果 G 值更小,則把那個方格的父親設為當前方格 ( 我們選中的方格 ) ,然後重新計算那個方格的 F 值和 G 值。如果你還是很混淆,請參考下圖。
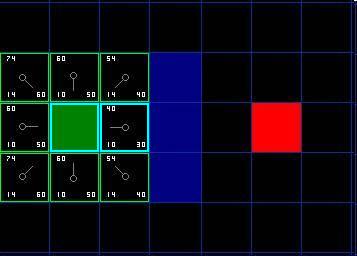
Ok ,讓我們看看它是怎麼工作的。在我們最初的 9 個方格中,還有 8 個在 open list 中,起點被放入了 close list 中。在這些方格中,起點右邊的格子的 F 值 40 最小,因此我們選擇這個方格作為下一個要處理的方格。它的外框用藍線打亮。
首先,我們把它從 open list 移到 close list 中 ( 這就是為什麼用藍線打亮的原因了 ) 。然後我們檢查與它相鄰的方格。它右邊的方格是牆壁,我們忽略。它左邊的方格是起點,在 close list 中,我們也忽略。其他 4 個相鄰的方格均在 open list 中,我們需要檢查經由這個方格到達那裡的路徑是否更好,使用 G 值來判定。讓我們看看上面的方格。它現在的 G 值為 14 。如果我們經由當前方格到達那裡, G 值將會為 20(其中 10 為到達當前方格的 G 值,此外還要加上從當前方格縱向移動到上面方格的 G 值 10) 。顯然 20 比 14 大,因此這不是最優的路徑。如果你看圖你就會明白。直接從起點沿對角線移動到那個方格比先橫向移動再縱向移動要好。
當把 4 個已經在 open list 中的相鄰方格都檢查後,沒有發現經由當前方格的更好路徑,因此我們不做任何改變。現在我們已經檢查了當前方格的所有相鄰的方格,並也對他們作了處理,是時候選擇下一個待處理的方格了。
因此再次遍歷我們的 open list ,現在它只有 7 個方格了,我們需要選擇 F 值最小的那個。有趣的是,這次有兩個方格的 F 值都 54 ,從速度上考慮,選擇最後加入 open list 的方格更快。這導致了在尋路過程中,當靠近目標時,優先使用新找到的方格的偏好。但是這並不重要。 ( 對相同資料的不同對待,導致兩中版本的 A* 找到等長的不同路徑 ) 。
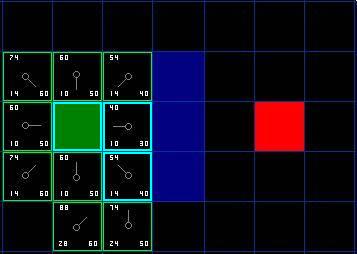
這次,當我們檢查相鄰的方格時,我們發現它右邊的方格是牆,忽略之。上面的也一樣。我們把牆下面的一格也忽略掉。為什麼?因為如果不穿越牆角的話,你不能直接從當前方格移動到那個方格。你需要先往下走,然後再移動到那個方格,這樣來繞過牆角。 ( 注意:穿越牆角的規則是可選的,依賴於你的節點是怎麼放置的 )
不斷重複這個過程,直到把終點也加入到了 open list 中,此時如下圖所示。
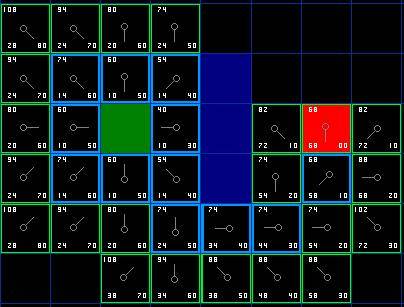
注意,在起點下面 2 格的方格的父親已經與前面不同了。之前它的 G 值是 28 並且指向它右上方的方格。現在它的 G 值為 20 ,並且指向它正上方的方格。這在尋路過程中的某處發生,使用新路徑時 G 值經過檢查並且變得更低,因此父節點被重新設定, G 和 F 值被重新計算。儘管這一變化在本例中並不重要,但是在很多場合中,這種變化會導致尋路結果的巨大變化。
那麼我們怎麼樣去確定實際路徑呢?很簡單,從終點開始,按著箭頭向父節點移動,這樣你就被帶回到了起點,這就是你的路徑。如下圖所示。從起點 A 移動到終點 B 就是簡單從路徑上的一個方格的中心移動到另一個方格的中心,直至目標。就是這麼簡單!
A*演算法總結(Summary of the A* Method)
Ok ,現在你已經看完了整個的介紹,現在我們把所有步驟放在一起:
- 把起點加入 open list 。
- 重複如下過程:
- 遍歷 open list ,查詢 F 值最小的節點,把它作為當前要處理的節點。
- 把這個節點移到 close list 。
- 對當前方格的 8 個相鄰方格的每一個方格?
- 如果它是不可抵達的或者它在 close list 中,忽略它。否則,做如下操作。
- 如果它不在 open list 中,把它加入 open list ,並且把當前方格設定為它的父親,記錄該方格的 F , G 和 H 值。
- 如果它已經在 open list 中,檢查這條路徑 ( 即經由當前方格到達它那裡 ) 是否更好,用 G 值作參考。更小的 G 值表示這是更好的路徑。如果是這樣,把它的父親設定為當前方格,並重新計算它的 G 和 F 值。如果你的 open list 是按 F 值排序的話,改變後你可能需要重新排序。
- 停止,當你把終點加入到了 open list 中,此時路徑已經找到了,或者查詢終點失敗,並且 open list 是空的,此時沒有路徑。
- 儲存路徑。從終點開始,每個方格沿著父節點移動直至起點,這就是你的路徑。
實現的註解(Notes on Implemetation)
現在你已經明白了基本方法,這裡是你在寫自己的程式是需要考慮的一些額外的東西。下面的材料引用了一些我用 C++ 和 Basic 寫的程式,但是對其他語言同樣有效。
1. 維護 Open List :這是 A* 中最重要的部分。每次你訪問 Open list ,你都要找出具有最小 F 值的方格。有幾種做法可以做到這個。你可以隨意儲存路徑元素,當你需要找到具有最小 F 值的方格時,遍歷整個 open list 。這個很簡單,但對於很長的路徑會很慢。這個方法可以通過維護一個排好序的表來改進,每次當你需要找到具有最小 F 值的方格時,僅取出表的第一項即可。我寫程式時,這是我用的第一個方法。
對於小地圖,這可以很好的工作,但這不是最快的方案。追求速度的 A* 程式設計師使用了叫做二叉堆的東西,我的程式裡也用了這個。以我的經驗,這種方法在多數場合下會快 2—3 倍,對於更長的路徑速度成幾何級數增長 (10 倍甚至更快 ) 。如果你想更多的瞭解二叉堆,請閱讀Using Binary Heaps in A* Pathfinding 。
2. 其他單位:如果你碰巧很仔細的看了我的程式,你會注意到我完全忽略了其他單位。我的尋路者實際上可以互相穿越。這取決於遊戲,也許可以,也許不可以。如果你想考慮其他單位,並想使他們移動時繞過彼此,我建議你的尋路程式忽略它們,再寫一些新的程式來判斷兩個單位是否會發生碰撞。如果發生碰撞,你可以產生一個新的路徑,或者是使用一些標準的運動法則(比如永遠向右移動,等等)直至障礙物不在途中,然後產生一個新的路徑。為什麼在計算初始路徑是不包括其他單位呢?因為其他單位是可以動的,當你到達的時候它們可能不在自己的位置上。這可以產生一些怪異的結果,一個單位突然轉向來避免和一個已不存在的單位碰撞,在它的路徑計算出來後和穿越它路徑的那些單位碰撞了。
在尋路程式碼中忽略其他單位,意味著你必須寫另一份程式碼來處理碰撞。這是遊戲的細節,所以我把解決方案留給你。本文末尾引用的 Bryan Stout's 的文章中的幾種解決方案非常值得了解。
3. 一些速度方面的提示:如果你在開發自己的 A* 程式或者是改編我寫的程式,最後你會發現尋路佔用了大量的 CPU 時間,尤其是當你有相當多的尋路者和一塊很大的地圖時。如果你閱讀過網上的資料,你會發現就算是開發星際爭霸,帝國時代的專家也是這樣。如果你發現事情由於尋路而變慢了,這裡有些主意很不錯:
- 使用小地圖或者更少的尋路者。
- 千萬不要同時給多個尋路者尋路。取而代之的是把它們放入佇列中,分散到幾個遊戲週期中。如果你的遊戲以每秒 40 週期的速度執行,沒人能察覺到。但是如果同時有大量的尋路者在尋路的話,他們會馬上就發現遊戲慢下來了。
- 考慮在地圖中使用更大的方格。這減少了尋路時需要搜尋的方格數量。如果你是有雄心的話,你可以設計多套尋路方案,根據路徑的長度而使用在不同場合。這也是專業人士的做法,對長路徑使用大方格,當你接近目標時使用小方格。如果你對這個有興趣,請看 Two-Tiered A* Pathfinding 。
- 對於很長的路徑,考慮使用路徑點系統,或者可以預先計算路徑並加入遊戲中。
- 預先處理你的地圖,指出哪些區域是不可到達的。這些區域稱為“孤島”。實際上,他們可以是島嶼,或者是被牆壁等包圍而不可到達的任意區域。 A* 的下限是,你告訴他搜尋通往哪些區域的路徑時,他會搜尋整個地圖,直到所有可以抵達的方格都通過 open list 或 close list 得到了處理。這會浪費大量的 CPU 時間。這可以通過預先設定不可到達的區域來解決。在某種陣列中記錄這些資訊,在尋路前檢查它。在我的 Blitz 版程式中,我寫了個地圖預處理程式來完成這個。它可以提前識別尋路演算法會忽略的死路徑,這又進一步提高了速度。
4. 不同的地形損耗:在這個教程和我的程式中,地形只有 2 種:可抵達的和不可抵達的。但是如果你有些可抵達的地形,移動代價會更高些,沼澤,山丘,地牢的樓梯 等都是可抵達的地形,但是移動代價比平地就要高。類似的,道路的移動代價就比它周圍的地形低。
在你計算給定方格的 G 值時加上地形的代價就很容易解決了這個問題。簡單的給這些方格加上一些額外的代價就可以了。 A* 演算法用來查詢代價最低的路徑,應該很容易處理這些。在我的簡單例子中,地形只有可達和不可達兩種, A* 會搜尋最短和最直接的路徑。但是在有地形代價的環境中,代價最低的的路徑可能會很長。
就像沿著公路繞過沼澤而不是直接穿越它。
另一個需要考慮的是專家所謂的“ influence Mapping ”,就像上面描述的可變成本地形一樣,你可以建立一個額外的計分系統,把它應用到尋路的 AI 中。假設你有這樣一張地圖,地圖上由個通道穿過山丘,有大批的尋路者要通過這個通道,電腦每次產生一個通過那個通道的路徑都會變得很擁擠。如果需要,你可以產生一個 influence map ,它懲罰那些會發生大屠殺的方格。這會讓電腦選擇更安全的路徑,也可以幫助它避免因為路徑短(當然也更危險)而持續把隊伍或尋路者送往某一特定路徑。
5. 維護未探測的區域:你玩 PC 遊戲的時候是否發現電腦總是能精確的選擇路徑,甚至地圖都未被探測。對於遊戲來說,尋路過於精確反而不真實。幸運的是,這個問題很容易修正。答案就是為每個玩家和電腦(每個玩家,不是每個單位 --- 那會浪費很多記憶體)建立一個獨立的 knownWalkability 陣列。每個陣列包含了玩家已經探測的區域的資訊,和假設是可到達的其他區域,直到被證實。使用這種方法,單位會在路的死端徘徊,並會做出錯誤的選擇,直到在它周圍找到了路徑。地圖一旦被探測了,尋路又向平常一樣工作。
6. 平滑路徑: A* 自動給你花費最小的,最短的路徑,但它不會自動給你最平滑的路徑。看看我們的例子所找到的路徑(圖 7 )。在這條路徑上,第一步在起點的右下方,如果第一步在起點的正下方是不是路徑會更平滑呢?
有幾個方法解決這個問題。在你計算路徑時,你可以懲罰那些改變方向的方格,把它的 G 值增加一個額外的開銷。另一種選擇是,你可以遍歷你生成的路徑,查詢那些用相鄰的方格替代會使路徑更平滑的地方。要了解更多,請看 Toward More Realistic Pathfinding 。
7. 非方形搜尋區域:在我們的例子中,我們使用都是 2D 的方形的區域。你可以使用不規則的區域。想想冒險遊戲中的那些國家,你可以設計一個像那樣的尋路關卡。你需要建立一張表格來儲存國家相鄰關係,以及從一個國家移動到另一個國家的 G 值。你還需要一個方法了估算 H 值。其他的都可以向上面的例子一樣處理。當你向 open list 新增新項時,不是使用相鄰的方格,而是查看錶裡相鄰的國家。
類似的,你可以為一張固定地形的地圖的路徑建立路徑點系統。路徑點通常是道路或地牢通道的轉折點。作為遊戲設計者,你可以預先設定路徑點。如果兩個路徑點的連線沒有障礙物的話它們被視為相鄰的。在冒險遊戲的例子中,你可以儲存這些相鄰資訊在某種表中,當 open list 增加新項時使用。然後記錄 G 值(可能用兩個結點間的直線距離)和 H 值(可能使用從節點到目標的直線距離)。其它的都想往常一樣處理。
進一步閱讀(Further Reading)
Ok ,現在你已經對 A* 有了個基本的瞭解,同時也認識了一些高階的主題。我強烈建議你看看我的程式碼,壓縮包裡包含了 2 個版本的實現,一個是 C++ ,另一個是 Blitz Basic 。 2 個版本都有註釋,你以該可以很容易就看懂。下面是連結:
如果你不會使用 C++ 或是 BlitzBasic ,在 C++ 版本下你可以找到兩個 exe 檔案。 BlitzBasic 版本必須去網站 Blitz Basic 下載 BlitzBasic 3D 的免費 Demo 才能執行。 在這裡 here 你可以看到一個 Ben O'Neill 的 A* 線上驗證例項。
你應該閱讀下面這幾個站點的文章。在你讀完本教程後你可以更容易理解他們。
Amit's A* Pages : Amit Patel 的這篇文章被廣泛引用,但是如果你沒有閱讀本教程的話,你可能會感到很迷惑。尤其是你可以看到 Amit Patel自己的一些想法。
Smart Moves: Intelligent Path Finding : Bryan Stout 的這篇需要去 Gamasutra.com 註冊才能閱讀。 Bryan 用 Delphi 寫的程式幫助我學習了A* ,同時給了我一些我的程式中的一些靈感。他也闡述了 A* 的其他選擇。
Terrain Analysis : Dave Pottinger 一篇非常高階的,有吸引力的文章。他是 Ensemble Studios 的一名專家。這個傢伙調整了遊戲帝國時代和王者時代。不要期望能夠讀懂這裡的每一樣東西,但是這是一篇能給你一些不錯的主意的很有吸引力的文章。它討論了包 mip-mapping ,
influence mapping ,和其他高階 AI 尋路主題。他的 flood filling 給了我在處理死路徑 ”dead ends” 和孤島 ”island” 時的靈感。這包含在我的 Blitz版本的程式裡。
下面的一些站點也值得去看看: