
CART演算法解讀
目錄
資料探勘十大演算法之一
1、演算法解讀
CART分類樹用的是另外一個指標 – 基尼指數. 假設一共有K個類,樣本屬於第k類的概率是pk,則概率分佈的基尼指數定義為:
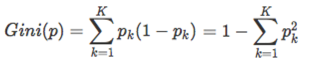
基尼係數類似於熵,選擇最佳劃分的度量通常是根據劃分後子女結點不純性的程度。不純的程度越低,類分佈就越傾斜。例如,類分佈為(0, 1)的結點具有零不純性,而均衡分佈(0.5,0.5)的結點具有最高的不純性。
對於二分類問題,如果樣本點屬於第一類的概率為p,則概率分佈的基尼係數為
Gini(p)=2p(1-p)
對於給定的樣本集合D,其基尼係數為:

CART分類時,使用基尼指數(Gini)來選擇最好的資料分割的特徵,gini描述的是純度,與資訊熵的含義相似。CART中每一次迭代都會降低GINI係數。下圖顯示資訊熵增益的一半,Gini指數,分類誤差率三種評價指標非常接近。

例項對比
可以與C4.5進行對比

Gini(是否打球)=2*(5/14)*(9/14)=0.459
對離散值如{x,y,x},則在該屬性上的劃分有三種情況({{x,y},{z}},{{x,z},y},{{y,z},x}),空集和全集的劃分除外
對於Outlook:有三個屬性,進行二分類取值時,有三種分類可能
1、{sunny}|{overcast,rainy}
2、{overcast}|{sunny, rainy}
3、{rainy}|{overcast, sunny}
1、{sunny}|{overcast, rainy}
Δ{Outlook}=0.459–5/14*(2*(2/5)*(3/5))-9/14*(2*(2/9)*(7/9)) = 0.065
2、{overcast}|{sunny, rainy}
Δ{Outlook}=0.459–4/14*(2*(4/4)*(0/4))-10/14*(2*(5/10)*(5/10)) = 0.102
3、{rainy}|{overcast, sunny}
Δ{Outlook}=0.459–5/14*(2*(3/5)*(2/5))-9/14*(2*(3/9)*(6/9))=0.002
對比計算結果,根據Outlook屬性來劃分根節點時取Gini係數增益最大的分組作為劃分結果,也就是:{overcast}|{sunny, rainy}
過程總結
1.設結點的訓練資料集為D,計算現有特徵對該資料集的Gini係數。此時,對每一個特徵A,對其可能取的每個值a,根據樣本點對A=a的測試為“是”或“否”將D分割成D1和D2兩部分,計算A=a時的Gini係數。
2.在所有可能的特徵A以及它們所有可能的切分點a中,選擇Gini係數最小的特徵及其對應的切分點作為最優特徵與最優切分點。依最優特徵與最優切分點,從現結點生成兩個子結點,將訓練資料集依特徵分配到兩個子結點中去。
3.對兩個子結點遞迴地呼叫步驟l~2,直至滿足停止條件。
4.生成CART決策樹。
python實戰
import pandas as pd
df = pd.read_csv("tree.csv")
df.head()資料還是上面的案例

資料處理
df.loc[df["outlook"] == "sunny", "outlook"] = 0
df.loc[df["outlook"] == "overcast", "outlook"] = 1
df.loc[df["outlook"] == "rainy", "outlook"] = 2
df.loc[df["temperature"] == "hot", "temperature"] = 0
df.loc[df["temperature"] == "mild", "temperature"] = 1
df.loc[df["temperature"] == "cool", "temperature"] = 2
df.loc[df["humidity"] == "high", "humidity"] = 0
df.loc[df["humidity"] == "normal", "humidity"] = 1
df.loc[df["windy"] =="N", "windy"] = 0
df.loc[df["windy"] =="Y", "windy"] = 1y=df["play"]
col=df.columns.tolist()
x_col=col[0:4]
x=df[x_col]from sklearn import tree
clf = tree.DecisionTreeClassifier(max_depth = 2,criterion='gini').fit(x,y)clf: DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=2, max_features=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, presort=False, random_state=None, splitter='best')
畫圖
from IPython.display import Image
dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=col[0:4],
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
Image(graph.create_png()) 
預測驗證
from sklearn import metrics
expected = y
predicted = clf.predict(x)
# summarize the fit of the model
print(metrics.classification_report(expected, predicted))
print(metrics.confusion_matrix(expected, predicted))準確率、召回率以及混淆矩陣

引數解釋
函式 tree.DecisionTreeClassifier()中的具體引數,在sklearn的官網中有給出,如下:
class sklearn.tree.DecisionTreeClassifier(criterion='gini', splitter='best', max_depth=None, min_samples_split=2,min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None,class_weight=None, presort=False)
criterion:string型別,可選(預設為"gini")
衡量分類的質量。支援的標準有"gini"代表的是Gini impurity(不純度)與"entropy"代表的是information gain(資訊增益)。
splitter:string型別,可選(預設為"best")
一種用來在節點中選擇分類的策略。支援的策略有"best",選擇最好的分類,"random"選擇最好的隨機分類。
max_features:int,float,string or None 可選(預設為None)
在進行分類時需要考慮的特徵數。
1.如果是int,在每次分類是都要考慮max_features個特徵。
2.如果是float,那麼max_features是一個百分率並且分類時需要考慮的特徵數是int(max_features*n_features,其中n_features是訓練完成時發特徵數)。
3.如果是auto,max_features=sqrt(n_features)
4.如果是sqrt,max_features=sqrt(n_features)
5.如果是log2,max_features=log2(n_features)
6.如果是None,max_features=n_features
注意:至少找到一個樣本點有效的被分類時,搜尋分類才會停止。
max_depth:int or None,可選(預設為"None")
表示樹的最大深度。如果是"None",則節點會一直擴充套件直到所有的葉子都是純的或者所有的葉子節點都包含少於min_samples_split個樣本點。忽視max_leaf_nodes是不是為None。
min_samples_split:int,float,可選(預設為2)
區分一個內部節點需要的最少的樣本數。
1.如果是int,將其最為最小的樣本數。
2.如果是float,min_samples_split是一個百分率並且ceil(min_samples_split*n_samples)是每個分類需要的樣本數。ceil是取大於或等於指定表示式的最小整數。
min_samples_leaf:int,float,可選(預設為1)
一個葉節點所需要的最小樣本數:
1.如果是int,則其為最小樣本數
2.如果是float,則它是一個百分率並且ceil(min_samples_leaf*n_samples)是每個節點所需的樣本數。
min_weight_fraction_leaf:float,可選(預設為0)
一個葉節點的輸入樣本所需要的最小的加權分數。
max_leaf_nodes:int,None 可選(預設為None)
在最優方法中使用max_leaf_nodes構建一個樹。最好的節點是在雜質相對減少。如果是None則對葉節點的數目沒有限制。如果不是None則不考慮max_depth.
class_weight:dict,list of dicts,"Banlanced" or None,可選(預設為None)
表示在表{class_label:weight}中的類的關聯權值。如果沒有指定,所有類的權值都為1。對於多輸出問題,一列字典的順序可以與一列y的次序相同。
"balanced"模型使用y的值去自動適應權值,並且是以輸入資料中類的頻率的反比例。如:n_samples/(n_classes*np.bincount(y))。
對於多輸出,每列y的權值都會想乘。
如果sample_weight已經指定了,這些權值將於samples以合適的方法相乘。
random_state:int,RandomState instance or None
如果是int,random_state 是隨機數字發生器的種子;如果是RandomState,random_state是隨機數字發生器,如果是None,隨機數字發生器是np.random使用的RandomState instance.
persort:bool,可選(預設為False)
是否預分類資料以加速訓練時最好分類的查詢。在有大資料集的決策樹中,如果設為true可能會減慢訓練的過程。當使用一個小資料集或者一個深度受限的決策樹中,可以減速訓練的過程。
這裡面大部分引數選擇預設即可。