Keras特徵圖Tensorboard視覺化
前言
之前在用Tensorflow框架的時候,對於特徵圖的視覺化已經研究了一下。主要的思路其實就是將特徵圖展開鋪平成一張大圖。具體文章參考Tensorboard特徵圖視覺化。
文章主要的函式就是將特徵圖沿著第四通道展開,然後將其拼接。最後的返回結果 all_concact 其實還是個四維的張量,第一維是 batch_size,最後一維是 1,中間兩維則是大的特徵圖的尺寸。
def _concact_features(self, conv_output):
"""
對特徵圖進行reshape拼接
:param conv_output:輸入多通道的特徵圖
:return:
""" 最近在用 Keras 框架,Keras 框架使用 Tensorboard 似乎更加簡單,利用 Tensorboard 這個 Callback 回撥函式,自帶了顯示 loss 等曲線的功能。但是對於特徵圖、輸入圖片等涉及到 image 相關的,Keras 自帶的 Tensorboard 並沒有幫我們實現,所以需要我們自己去完善。
關於這方面的現成的資料可能有點難找,所以自己稍微摸索了一陣子,主要思路還是基於修改原始碼的方式進行擴充套件我們自己需要的功能。
主要有兩個注意點:
- 利用Keras的API獲取到網路中間層的輸出結果時,這些只能用來定義
summary,並不是直接就獲取到輸出值了,想要獲取到真正的輸出值,需要給網路填充資料; - 我們只需要在
set_model()函式中利用tf.summary.image()之類的函式定義summary一次即可,想要更新則在on_batch_end()函式中不斷的計算更新,也就是sess.run()和add_summary()。
可能表述的不是很清楚,沒有用專業的詞彙去表達,不能理解的可以直接看程式碼的實現思路,然後再回頭看這兩個注意點。
程式碼實現
下面附上自定義的 Tensorboard 原始碼。程式碼的自定義 MyTensorBoard 類的建構函式引數的含義都用註釋標明,程式碼的主要修改在於加入了顯示學習率變化的曲線和特徵圖的展示。
利用 self.model.layers 獲取 Keras 的 model 的每一個網路層,然後遍歷每一層,通過 layer.output 獲取網路層的輸出。利用 tf.summary.image() 將這些層的輸出新增至 Tensorboard 中即可。
實現過程需要注意上述的兩個注意點。其實主要就是 Keras 官方文件的那些獲取網路中間層輸出等等 API 都是不能直接有資料的,一定要 feed 資料才行。其實仔細想想是有道理的,Keras 只是包裝了一下 Tensorflow 的計算圖(網路模型),而不是幫我們都直接計算 (sess.run) 好了值。
# coding=utf-8
"""
自定義Tensorboard顯示特徵圖
"""
from keras.callbacks import Callback
from keras import backend as K
import warnings
import math
import numpy as np
class MyTensorBoard(Callback):
"""TensorBoard basic visualizations.
log_dir: the path of the directory where to save the log
files to be parsed by TensorBoard.
write_graph: whether to visualize the graph in TensorBoard.
The log file can become quite large when
write_graph is set to True.
batch_size: size of batch of inputs to feed to the network
for histograms computation.
input_images: input data of the model, because we will use it to build feed dict to
feed the summary sess.
write_features: whether to write feature maps to visualize as
image in TensorBoard.
update_features_freq: update frequency of feature maps, the unit is batch, means
update feature maps per update_features_freq batches
update_freq: `'batch'` or `'epoch'` or integer. When using `'batch'`, writes
the losses and metrics to TensorBoard after each batch. The same
applies for `'epoch'`. If using an integer, let's say `10000`,
the callback will write the metrics and losses to TensorBoard every
10000 samples. Note that writing too frequently to TensorBoard
can slow down your training.
"""
def __init__(self, log_dir='./logs',
batch_size=64,
update_features_freq=1,
input_images=None,
write_graph=True,
write_features=False,
update_freq='epoch'):
super(MyTensorBoard, self).__init__()
global tf, projector
try:
import tensorflow as tf
from tensorflow.contrib.tensorboard.plugins import projector
except ImportError:
raise ImportError('You need the TensorFlow module installed to '
'use TensorBoard.')
if K.backend() != 'tensorflow':
if write_graph:
warnings.warn('You are not using the TensorFlow backend. '
'write_graph was set to False')
write_graph = False
if write_features:
warnings.warn('You are not using the TensorFlow backend. '
'write_features was set to False')
write_features = False
self.input_images = input_images[0]
self.log_dir = log_dir
self.merged = None
self.im_summary = []
self.lr_summary = None
self.write_graph = write_graph
self.write_features = write_features
self.batch_size = batch_size
self.update_features_freq = update_features_freq
if update_freq == 'batch':
# It is the same as writing as frequently as possible.
self.update_freq = 1
else:
self.update_freq = update_freq
self.samples_seen = 0
self.samples_seen_at_last_write = 0
def set_model(self, model):
self.model = model
if K.backend() == 'tensorflow':
self.sess = K.get_session()
if self.merged is None:
# 顯示特徵圖
# 遍歷所有的網路層
for layer in self.model.layers:
# 獲取當前層的輸出與名稱
feature_map = layer.output
feature_map_name = layer.name.replace(':', '_')
if self.write_features and len(K.int_shape(feature_map)) == 4:
# 展開特徵圖並拼接成大圖
flat_concat_feature_map = self._concact_features(feature_map)
# 判斷展開的特徵圖最後通道數是否是1
shape = K.int_shape(flat_concat_feature_map)
assert len(shape) == 4 and shape[-1] == 1
# 寫入tensorboard
self.im_summary.append(tf.summary.image(feature_map_name, flat_concat_feature_map, 4)) # 第三個引數為tensorboard展示幾個
# 顯示學習率的變化
self.lr_summary = tf.summary.scalar("learning_rate", self.model.optimizer.lr)
self.merged = tf.summary.merge_all()
if self.write_graph:
self.writer = tf.summary.FileWriter(self.log_dir, self.sess.graph)
else:
self.writer = tf.summary.FileWriter(self.log_dir)
def on_epoch_end(self, epoch, logs=None):
logs = logs or {}
if self.validation_data:
val_data = self.validation_data
tensors = (self.model.inputs +
self.model.targets +
self.model.sample_weights)
if self.model.uses_learning_phase:
tensors += [K.learning_phase()]
assert len(val_data) == len(tensors)
val_size = val_data[0].shape[0]
i = 0
while i < val_size:
step = min(self.batch_size, val_size - i)
if self.model.uses_learning_phase:
# do not slice the learning phase
batch_val = [x[i:i + step] for x in val_data[:-1]]
batch_val.append(val_data[-1])
else:
batch_val = [x[i:i + step] for x in val_data]
assert len(batch_val) == len(tensors)
feed_dict = dict(zip(tensors, batch_val))
result = self.sess.run([self.merged], feed_dict=feed_dict)
summary_str = result[0]
self.writer.add_summary(summary_str, epoch)
i += self.batch_size
if self.update_freq == 'epoch':
index = epoch
else:
index = self.samples_seen
self._write_logs(logs, index)
def _write_logs(self, logs, index):
for name, value in logs.items():
if name in ['batch', 'size']:
continue
summary = tf.Summary()
summary_value = summary.value.add()
if isinstance(value, np.ndarray):
summary_value.simple_value = value.item()
else:
summary_value.simple_value = value
summary_value.tag = name
self.writer.add_summary(summary, index)
self.writer.flush()
def on_train_end(self, _):
self.writer.close()
def on_batch_end(self, batch, logs=None):
if self.update_freq != 'epoch':
self.samples_seen += logs['size']
samples_seen_since = self.samples_seen - self.samples_seen_at_last_write
if samples_seen_since >= self.update_freq:
self._write_logs(logs, self.samples_seen)
self.samples_seen_at_last_write = self.samples_seen
# 每update_features_freq個batch重新整理特徵圖
if batch % self.update_features_freq == 0:
# 計算summary_image
feed_dict = dict(zip(self.model.inputs, self.input_images[np.newaxis, ...]))
for i in range(len(self.im_summary)):
summary = self.sess.run(self.im_summary[i], feed_dict)
self.writer.add_summary(summary, self.samples_seen)
# 每個batch顯示學習率
summary = self.sess.run(self.lr_summary, {self.model.optimizer.lr: K.eval(self.model.optimizer.lr)})
self.writer.add_summary(summary, self.samples_seen)
def _concact_features(self, conv_output):
"""
對特徵圖進行reshape拼接
:param conv_output:輸入多通道的特徵圖
:return: all_concact
"""
all_concact = None
num_or_size_splits = conv_output.get_shape().as_list()[-1]
each_convs = tf.split(conv_output, num_or_size_splits=num_or_size_splits, axis=3)
if num_or_size_splits < 4:
# 對於特徵圖少於4通道的認為是輸入,直接橫向concact輸出即可
concact_size = num_or_size_splits
all_concact = each_convs[0]
for i in range(concact_size - 1):
all_concact = tf.concat([all_concact, each_convs[i + 1]], 1)
else:
concact_size = int(math.sqrt(num_or_size_splits) / 1)
for i in range(concact_size):
row_concact = each_convs[i * concact_size]
for j in range(concact_size - 1):
row_concact = tf.concat([row_concact, each_convs[i * concact_size + j + 1]], 1)
if i == 0:
all_concact = row_concact
else:
all_concact = tf.concat([all_concact, row_concact], 2)
return all_concact
該自定義類基本和具體的網路無關,可以直接就用。唯一需要自己實現的部分就是傳入 input_images 引數,這其實就是網路的輸入資料。一般使用 Keras 框架,都會定義資料的讀取函式(generate 函式),並將該讀取函式傳給 model.fit_generator() 中。我們僅僅需要利用 __next__ 方法(python2是 next())即可獲取到一組資料傳入我們自定義的 MyTensorBoard 建構函式中。
例如:
# 定義一個讀取資料的generate函式
def _get_data(self, path, batch_size, normalize):
"""
Generator to be used with model.fit_generator()
:param path: .npz資料路徑
:param batch_size: batch_size
:param normalize: 是否歸一化
:return:
"""
while True:
files = glob.glob(os.path.join(path, '*.npz'))
np.random.shuffle(files)
for npz in files:
# Load pack into memory
archive = np.load(npz)
images = archive['images']
offsets = archive['offsets']
del archive
self._shuffle_in_unison(images, offsets)
# 切分獲得batch
num_batches = int(len(offsets) / batch_size)
images = np.array_split(images, num_batches)
offsets = np.array_split(offsets, num_batches)
while offsets:
batch_images = images.pop()
batch_offsets = offsets.pop()
if normalize:
batch_images = (batch_images - 127.5) / 127.5
yield batch_images, batch_offsets
train_loader = _get_data(/path/xxx, 128, True)
MyTensorBoard(
log_dir=self.config.tb_dir,
input_images=train_loader.__next__(), # 使用__next__()獲取一組資料
batch_size=self.config.batch_size,
update_features_freq=50,
write_features=True,
write_graph=True,
update_freq='batch'
)
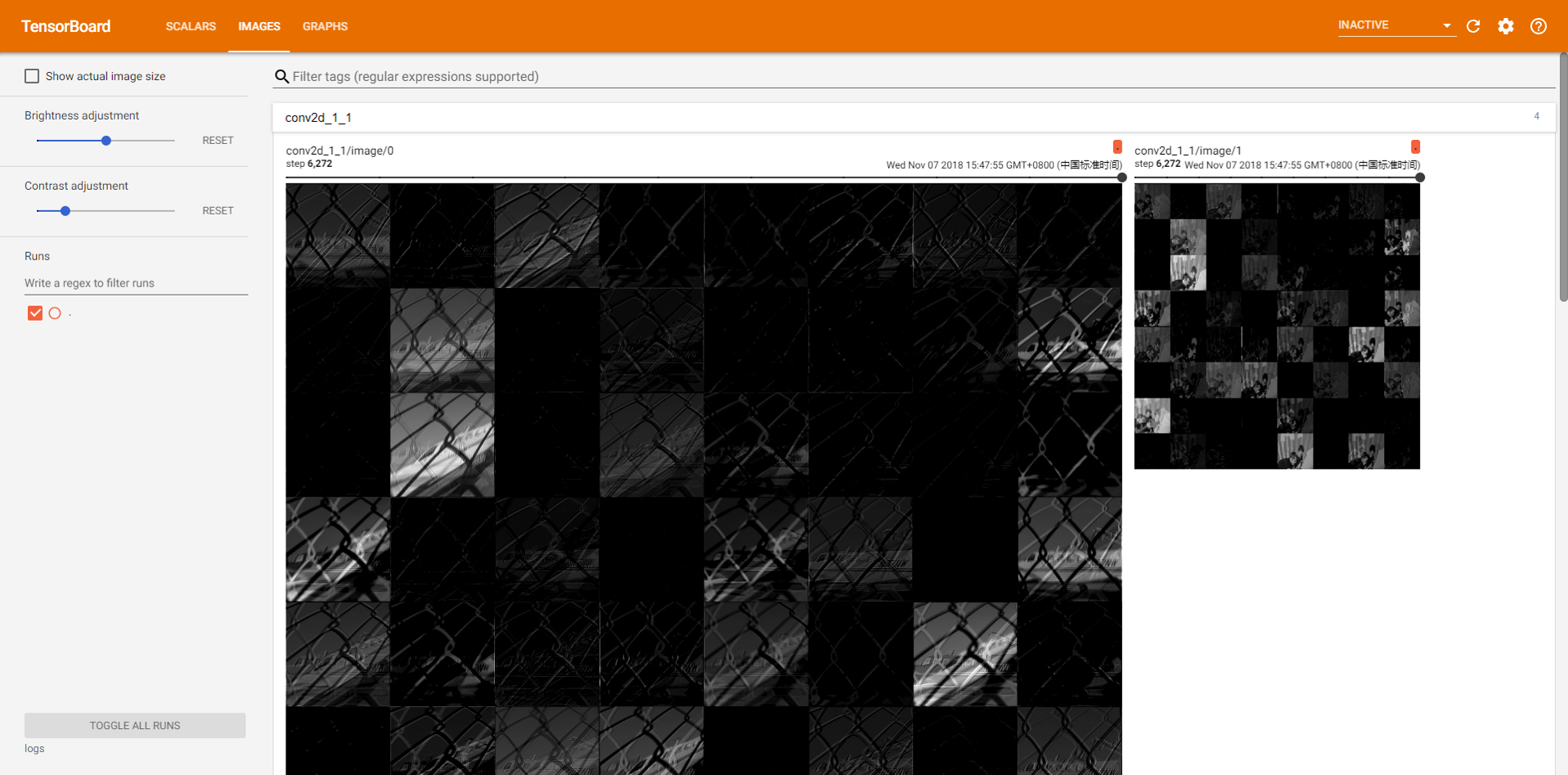
結果圖
- 顯示學習率變化曲線(附自定義指數下降學習率的實現程式碼);
class LearningRate(Callback): """ 自定義學習率調整函式 """ def __init__(self, config): super(LearningRate, self).__init__() self.base_lr = config.learning_rate self.num_total_steps = config.num_epochs * int(np.ceil(config.num_datas / float(config.batch_size))) self.step = 0 # 記錄訓練batch的次數 # 下降間隔 self.decay_steps = int((math.log(0.96) * self.num_total_steps) / math.log(config.min_lr * 1.0 / self.base_lr)) print("[DEBUG]: learning rate decay steps is %d ......" % self.decay_steps) def on_batch_begin(self, batch, logs=None): self.step += 1 if self.step % self.decay_steps == 0: cur_lr = self.base_lr * math.pow(0.96, self.step / self.decay_steps) K.set_value(self.model.optimizer.lr, cur_lr)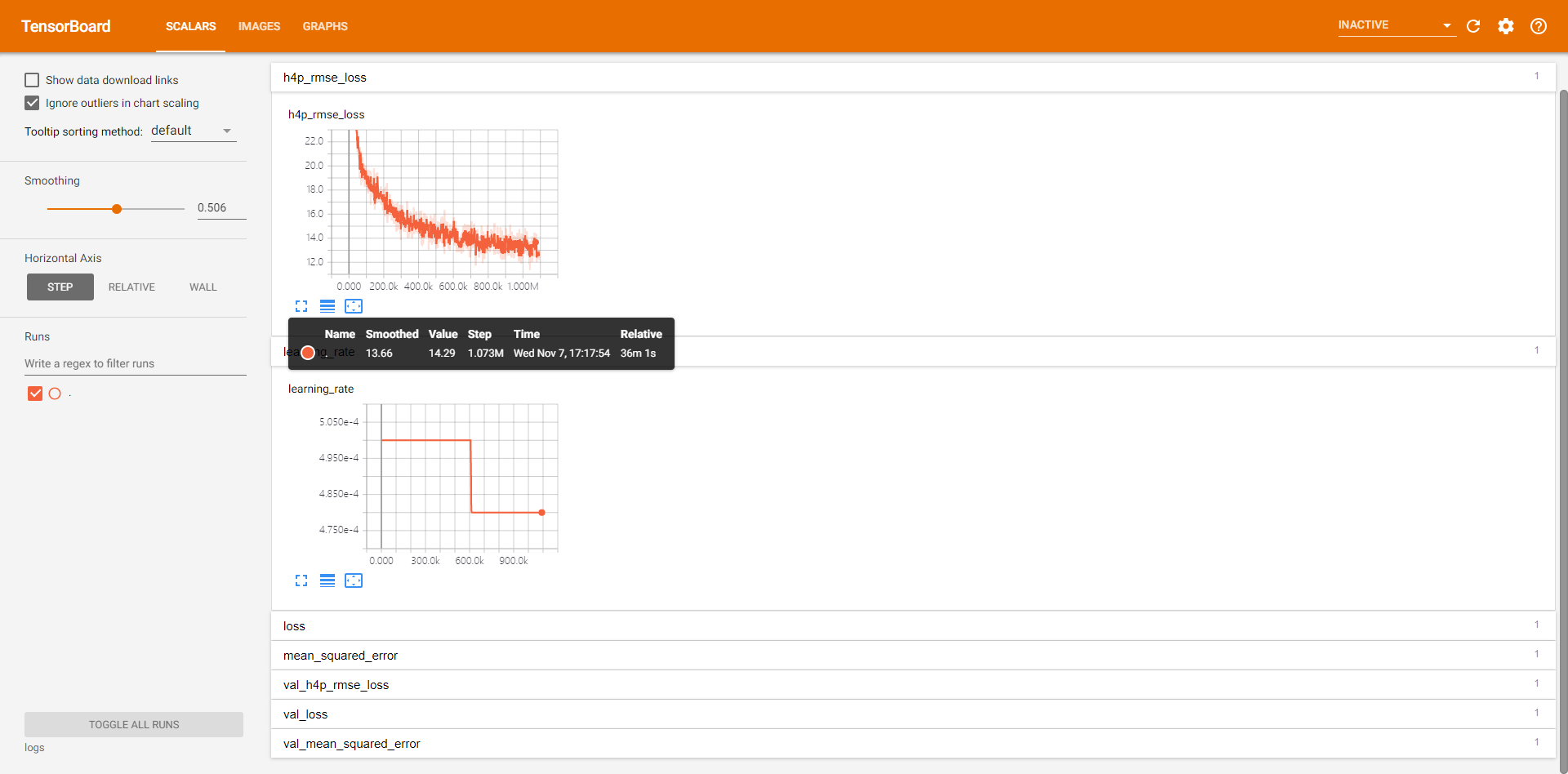
- 顯示特徵圖。