
行為識別 人體骨架檢測+LSTM
轉自http://geek.csdn.net/news/detail/138011
在人工智慧研究領域,這一技能叫人體行為識別,是智慧監控、人機互動、機器人等諸多應用的一項基礎技術。以電影提到的老人智慧看護場景為例,智慧系統通過實時檢測和分析老人的行動,判斷老人是否正常吃飯、服藥、是否保持最低的運動量、是否有異常行動出現(例如摔倒), 從而及時給予提醒,確保老人的生活質量不會由於獨自居住而有所降低。第二個例子是人機互動系統,通過對人的行為進行識別,猜測使用者的“心思”,預測使用者的意圖,及時給予準確的響應。第三個例子是醫院的康復訓練,通過對動作行為的規範程度做出識別,評估恢復程度以提供更好的康復指導等。
俗話說“排骨好吃,骨頭難啃”,行為識別是一項具有挑戰性的任務,受光照條件各異、視角多樣性、背景複雜、類內變化大等諸多因素的影響。對行為識別的研究可以追溯到1973年,當時Johansson通過實驗觀察發現,人體的運動可以通過一些主要關節點的移動來描述,因此,只要10-12個關鍵節點的組合與追蹤便能形成對諸多行為例如跳舞、走路、跑步等的刻畫,做到通過人體關鍵節點的運動來識別行為[2]。正因為如此,在Kinect的遊戲中,系統根據深度圖估計出的人體骨架(Skeleton,由人體的一些關節點的位置資訊組成),對人的姿態動作進行判斷,促成人機互動的實現。另一個重要分支則是基於RGB視訊做行為動作識別。與RGB資訊相比,骨架資訊具有特徵明確簡單、不易受外觀因素影響的優點。我們在這裡主要探討基於骨架的行為識別及檢測。
人體骨架怎麼獲得呢?主要有兩個途徑:通過RGB影象進行關節點估計(Pose Estimation)獲得[3][4],或是通過深度攝像機直接獲得(例如Kinect)。每一時刻(幀)骨架對應人體的K個關節點所在的座標位置資訊,一個時間序列由若干幀組成。行為識別就是對時域預先分割好的序列判定其所屬行為動作的型別,即“讀懂行為”。但在現實應用中更容易遇到的情況是序列尚未在時域分割(Untrimmed),因此需要同時對行為動作進行時域定位(分割)和型別判定,這類任務一般稱為行為檢測。
基於骨架的行為識別技術,其關鍵在於兩個方面:一方面是如何設計魯棒和有強判別性的特徵,另一方面是如何利用時域相關性來對行為動作的動態變化進行建模。
我們採用基於LSTM (Long-Short Term Memory)的迴圈神經網路(RNN)來搭建基礎框架,用於學習有效的特徵並且對時域的動態過程建模,實現端到端(End-to-End)的行為識別及檢測。關於LSTM的詳細介紹可參考[5]。我們的工作主要從以下三個方面進行探討和研究:
- 如何利用空間注意力(Spatial Attention)和時間注意力(Temporal Attention)來實現高效能行為動作識別 [8]?
- 如何利用人類行為動作具有的共現性(Co-occurrence)來提升行為識別的效能[7]?
- 如何利用RNN網路對未分割序列進行行為檢測(行為動作的起止點的定位和行為動作型別的判定)[9]?
空時注意力模型(Attention)之於行為識別
注意力模型(Attention Model)在過去這兩年裡成了機器學習界的“網紅”,其想法就是模擬人類對事物的認知,將更多的注意力放在資訊量更大的部分。我們也將注意力模型引入了行為識別的任務,下面就來看一下注意力模型是如何在行為識別中大顯身手的。
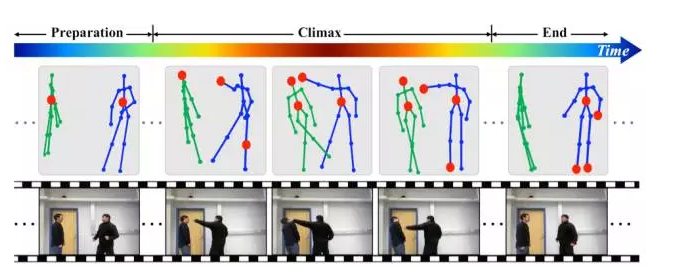
時域注意力:眾所周知,一個行為動作的過程要經歷多個狀態(對應很多時間幀),人體在每個時刻也呈現出不同的姿態,那麼,是不是每一幀在動作判別中的重要性都相同呢?以“揮拳”為例,整個過程經歷了開始的靠近階段、揮動拳腳的高潮階段以及結束階段。相比之下,揮動拳腳的高潮階段包含了更多的資訊,最有助於動作的判別。依據這一點,我們設計了時域注意力模型,通過一個LSTM子網路來自動學習和獲知序列中不同幀的重要性,使重要的幀在分類中起更大的作用,以優化識別的精度。
空域注意力:對於行為動作的判別,是不是每個關節點在動作判別中都同等重要呢?研究證明,一些行為動作會跟某些關節點構成的集合相關,而另一些行為動作會跟其它一些關節點構成的集合相關。比如“打電話”,主要跟頭、肩膀、手肘和手腕這些關節點密切相關,同時跟腿上的關節點關係很小,而對“走路”這個動作的判別主要通過腿部節點的觀察就可以完成。與此相適應,我們設計了一個LSTM子網路,依據序列的內容自動給不同關節點分配不同的重要性,即給予不同的注意力。由於注意力是基於內容的,即當前幀資訊和歷史資訊共同決定的,因此,在同一個序列中,關節點重要性的分配可以隨著時間的變化而改變。
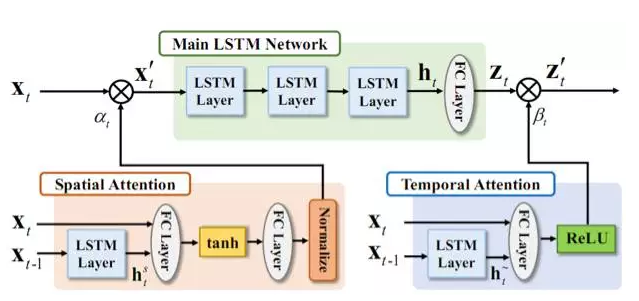
圖1.2展示了網路框架圖。時域注意力子網路 (Temporal Attention)學習一個時域注意力模型來給不同幀分配合適的重要性,並以此為依據對不同幀資訊進行融合。空域注意力子網路(Spatial Attention)學習一個時域注意力模型來給不同節點分配合適的重要性,作用於網路的輸入關節點上。
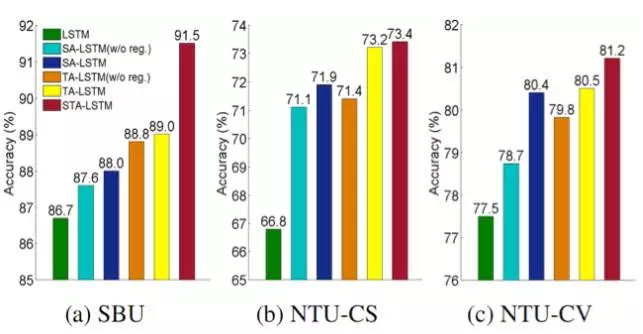
空時注意力模型能帶來多大的好處呢?我們在SBU 資料庫、NTU RGB+D 資料庫的Cross Subject(CS) 和 Cross View(CV) 設定上分別進行了實驗,以檢測其有效性。圖1.3展示了效能的比較:LSTM表示只有主LSTM網路時的效能(沒引入注意力模型)。當同時引入時域注意力(TA)和空域注意力(SA)網路後,如STA-LSTM所示,識別的精度實現了大幅提升。
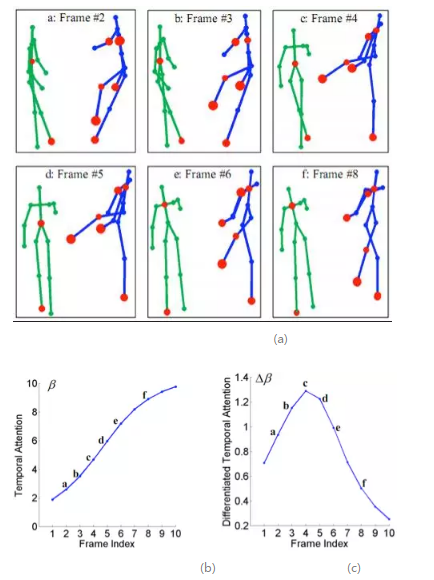
細心的讀者可能已經發現,序列中的空域注意力和時域注意力具體為多大是沒有參考的(不知道Groundtruth)。網路是以優化最終分類效能來自動習得注意力。那麼,學到的注意力模型分配的注意力數值是什麼樣呢?我們視覺化並分析了空時注意力模型的輸出。圖1.4可視化了在 “揮拳”行為動作的測試序列上,模型輸出的空域注意力權重的大小,時域注意力權重值 以及相鄰幀時域注意力的差值。如圖1.4(a)中所示,主動方(右側人)的節點被賦予了更大的權值,且腿部的節點更加活躍。圖(b)展示了時域注意力的變化,可以看到,時域注意力隨著動作的發展逐漸上升,相鄰幀時域注意力差值的變化則表明了幀間判別力的增量。時域注意力模型會對更具判別力的幀賦予較大的注意力權重。對不同的行為動作,空間注意力模型賦予較大權重的節點也不同,整體和人的感知一致。
LSTM網路框架和關節點共現性(Co-occurrence)的挖掘之於行為識別
欣賞完“網紅”的魅力之後,我們還是迴歸一下LSTM網路的本真吧。近年來,除了在網路結構上的探索,如何在網路設計中利用人的先驗知識以及任務本身的特性來提升效能,也越來越多地受到關注。
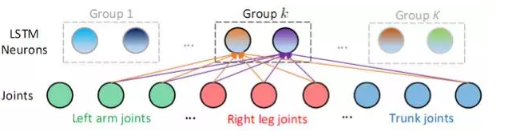
著眼於人的行為動作的特點,我們將行為動作中關節點具有的共現性特性引入到LSTM網路設計中,將其作為網路引數學習的約束來優化識別效能。人的某個行為動作常常和骨架的一些特定關節點構成的集合,以及這個集合中節點的互動密切相關。如要判別是否在打電話,關節點“手腕”、“手肘”、“肩膀”和“頭”的動作最為關鍵。不同的行為動作與之密切相關的節點集合有所不同。例如對於“走路”的行為動作,“腳腕”、“膝蓋”、“臀部”等關節點構成具有判別力的節點集合。我們將這種幾個關節點同時影響和決定判別的特性稱為共現性(Co-occurrence)。
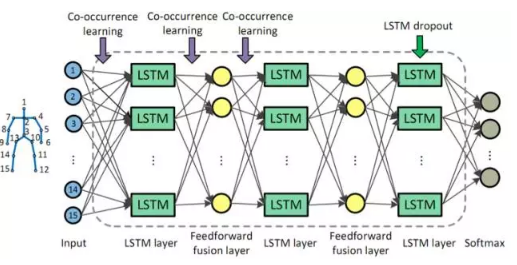
在訓練階段,我們在目標函式中引入對關節點和神經元相連的權重的約束,使同一組的神經元對某些關節點組成的子集有更大的權重連線,而對其他節點有較小的權重連線,從而挖掘關節點的共現性。如圖2.2所示,一個LSTM 層由若干個LSTM神經元組成,這些神經元被分為K組。同組中的每個神經元共同地和某些關節點有更大的連線權值(和某類或某幾類動作相關的節點構成關節點子集),而和其他關節點有較小的連線權值。不同組的神經元對不同動作的敏感程度不同,體現在不同組的神經元對應於更大連線權值的節點子集也不同。在實現上,我們通過對每組神經元和關節點的連線加入組稀疏(Group Sparse)約束來達到上述共現性的挖掘和利用。
關節點共現性約束的引入,在SBU資料庫上帶來了3.4%的效能改進。通過引入Dropout技術,最終實現了高達90.4%的識別精度。
基於聯合分類和迴歸的迴圈神經網路之於行為動作檢測
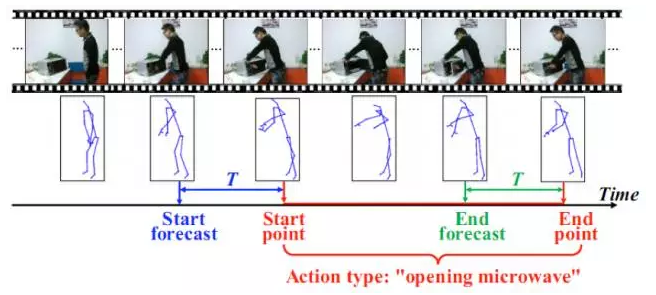
前面討論了對於時域分割好的序列的行為動作分類問題。但是想要計算機get到“察言觀色”的技能並不那麼容易。在實際的應用中多有實時的需求,而攝像頭實時獲取的視訊序列並沒有根據行為動作的發生位置進行預先時域分割,因此識別系統不僅需要判斷行為動作的型別,也需要定位行為動作發生的位置,即進行行為動作檢測。如圖3.1所示,對於時間序列流,檢測系統在每個時刻給出是否當前是行為動作的開始或結束,以及行為動作的型別資訊。

線上(Online)的行為動作檢測常常採用滑窗的方法,即對視訊序列流每次觀察一個時間視窗內的內容,對其進行分類。然而基於滑窗的方法常常伴隨著冗餘的計算,效能也會受到滑動視窗大小的影響。
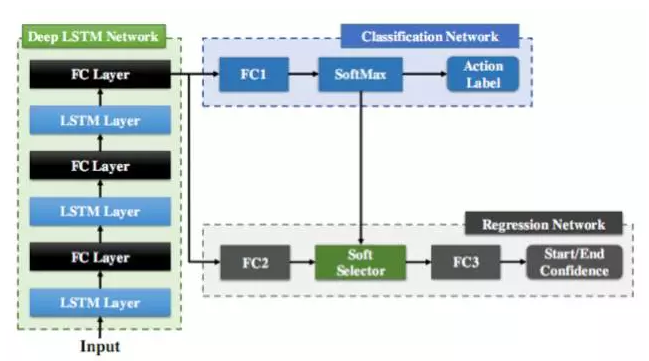
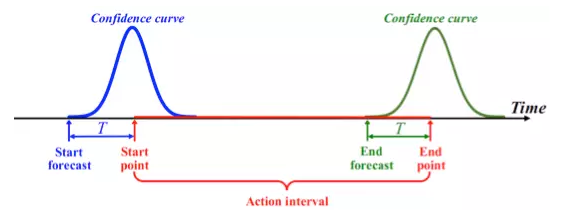
對於骨架序列流,我們設計了基於迴圈神經網路LSTM的線上行為動作檢測系統,在每幀給出行為動作判定的結果。LSTM的記憶性可以避免顯式的滑動視窗設計。如圖3.3所示,網路由LSTM 層和全連層(FC Layer)組成前端的網路Deep LSTM Network, 後面連線的分類網路 (Classification Network)用於判定每幀的動作類別,同時,迴歸網路 ( Regression Network )用於輔助確定動作行為的起止幀。圖3.4展示了該回歸子網路對起止點位置的目標迴歸曲線,即以起始點(結束點)為中心的高斯形狀曲線。在測試時,當發現代表起始點的迴歸曲線到達區域性峰值時,便可以定位為行為動作的起點位置。由於LSTM網路對時間序列處理的強大能力,加上聯合分類迴歸的設計,聯合分類和迴歸迴圈網路(JCR-RNN)實現了快速準確的行為動作檢測。
總結和展望
由於行為識別技術在智慧監控、人機互動、視訊序列理解、醫療健康等眾多領域扮演著越來越重要的角色,研究人員正使出“洪荒之力”提高行為識別技術的準確度。說不定在不久的某一天,你家門口真會出現一個能讀懂你的行為、和你“心有靈犀”的機器人,對於這一幕,你是不是和我們一樣充滿期待?
[1] https://movie.douban.com/subject/25757903/
[2] Gunnar Johansson. Visual perception of biological motion and a model for it is analysis. Perception and Psychophysics 14(2), pp 201–211, 1973.
[3] Alejandro Newell, Kaiyu Yang, Jia Deng. Stacked Hourglass Networks for Human Pose Estimation, In ECCV, 2016.
[4] Zhe Cao, Tomas Simon, Shih-En Wei, Yaser Sheikh. Realtime Multi-person 2D Pose Estimation using Part Affinity Fields. arXiv preprint arXiv:1611.08050, 2016.
[5] http://colah.github.io/posts/2015-08-Understanding-LSTMs/
[6] CVPR2011 Tutorial on Human Activity Recognition.
http://michaelryoo.com/cvpr2011tutorial/
[7] Wentao Zhu, Cuiling Lan, Junliang Xing, Wenjun Zeng, Yanghao Li, Li Shen, Xiaohui Xie. Co-Occurrence Feature Learning for Skeleton Based Action Recognition Using Regularized Deep LSTM Networks. In AAAI, 2016.
[8] Sijie Song, Cuiling Lan, Junliang Xing, Wenjun Zeng, Jiaying Liu. An End-to-End Spatio-Temporal Attention Model for Human Action Recognition from Skeleton Data. Accepted by AAAI, 2017.
[9] Yanghao Li, Cuiling Lan, Junliang Xing, Wenjun Zeng, Chunfeng Yuan, Jiaying Liu. Online Human Action Detection Using Joint Classification-Regression Recurrent Neural Networks. In ECCV, 2016.
作者簡介:蘭翠玲博士,微軟亞洲研究院副研究員,從事計算機視覺,訊號處理方面的研究。她的研究興趣包括行為識別、姿態估計、深度學習、視訊分析、視訊壓縮和通訊等,並在多個頂級會議,期刊上發表了近20篇論文,如AAAI, ECCV, TCSVT等。
來源::微軟研究院AI頭條,授權CSDN釋出。