
文字分類概述
內容提要
分類概述
分類(Classification)是指自動對資料進行標註。人們在日常生活中通過經驗劃分類別。但是要依據一些規則手工地對網際網路上的每一個頁面進行分類,是不可能的。因此,基於計算機的高效自動分類技術成為人們解決網際網路應用難題的迫切需求。與分類技術類似的是聚類,聚類不是將資料匹配到預先定義的標籤集合,而是通過與其他資料相關的隱含結構自動的聚集為一個或多個類別。文字分類是資料探勘和機器學習領域的一個重要研究方向。
分類是資訊檢索領域多年來一直研究的課題,一方面以搜尋的應用為目的來提高有效性和某些情況下的效率;另一方面,分類也是經典的機器學習技術。在機器學習領域,分類是在有標註的預定義類別體系下進行,因此屬於有監督的學習問題;相反聚類則是一種無監督的學習問題。
文字分類(Text Classification或Text Categorization,TC),或者稱為自動文字分類(Automatic Text Categorization),是指計算機將載有資訊的一篇文字對映到預先給定的某一類別或某幾類別主題的過程。文字分類另外也屬於自然語言處理領域。本文中文字(Text)和文件(Document)不加區分,具有相同的意義。
F. Sebastiani以如下數學模型描述文字分類任務:文字分類的任務可以理解為獲得這樣的一個函式Φ:D×C→{T,F},其中,D={d1

對於單類別的分類,即某篇文件只允許被分入一個類別中,我們可以增加限定條件,對於第j行( j = 1,…,N)的所有元素,必須滿足:
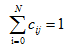
在實際應用中,根據預定義的類別不同,分類系統可以分兩種:兩類分類器和多類分類器。如果從文字的標註類別上來講,文字分類可以又可以分為單標籤和多標籤兩類。文字分類系統的任務簡單的說:在預定義分類體系下,根據文字的內容相關性自動地判定文字與類別之間的關聯。從數學角度來看,文字分類是一個函式對映過程,它將未標明類別的文字對映到預定義的類別,該對映可以是一一對映,也可以是一對多的對映,因為通常一篇文字可以同時關聯到多個類別。
分類流程
文字分類系統可以簡單的表示為如圖2.1所示:

- 文字預處理模型(Text Preprocessing Model),
- 文字表示模型(Text Expressing Model),
- 特徵選擇模型( Feature Selection Model),
- 學習訓練模型(Learning and Selection Model),
- 分類處理模型(Classification Processing Model),
- 效能評估模型(Performance Evaluation Model)。
多數情況下的監督型機器學習演算法,學習訓練模型僅需在分類預測前執行一次即可;效能評估模型主要起到評估訓練模型學習效果,衡量分類精度的作用。 文字分類的一般流程如圖所示:

資料採集
資料採集是文字我覺的基礎,主要包括爬蟲技術和頁面處理。
爬蟲技術
Web資訊檢索的第一步就是要抓取網路文件,爬蟲就承擔瞭解決這一問題的主要責任。爬蟲有很多種型別,但最典型的就是網路爬蟲。網路爬蟲通過跟蹤網頁上的超連結來搜尋並下載新的頁面。似乎聽起來該過程比較簡單,但是如何能夠高效處理Web上出現的大量新頁面,如何處理已抓取頁面的更新頁面,如何保持頁面的最新性,這些問題都成為網路爬蟲設計富有挑戰的難題。網路爬蟲抓取任務可以限定在一個比較小的範圍內,例如一個公司,一個網站,或者一所大學的站點。主題網路爬蟲與話題網路爬蟲要採用分類技術來限制所搜尋頁面屬於同一主題類別。
頁面處理
通過網路爬蟲抓取的頁面是最原始的Web頁面,它們的格式多種多樣,如HTML、XML、Adobe PDF、Microsoft Word等等。這些web頁面含有大量的噪聲資料,包括導航欄、廣告資訊、Web標籤、超連結或者其他非內容格式資料等,這些資料幾乎都成是阻礙文字下一步處理的因素。因此需要經過預處理去除上述噪音資料,將Web頁面轉化成為純淨統一的文字格式和元資料格式。Web關注內容過濾也是Web資訊處理領域的一項熱門研究課題。 另外一個普遍存在的頁面處理問題是編碼不一致。由於計算機發展、民族語言、國家地域的不同造成現在計算機儲存資料採用許多種編碼格式,例如ASCII、UTF-8、GBK、BIG5等等。在實際應用過程中,在對不同編碼格式的文件進行深入處理之前,必須要保證對它們編碼格式進行統一轉換。
文字預處理
文字要轉化成計算機可以處理的資料結構,就需要將文字切分成構成文字的語義單元。這些語義單元可以使句子、短語、詞語或單個的字。本文無論對於中文還是英文文字,統一將最小語義單元稱為“片語”。對於不同的語言來說處理有所區別,下面簡述最常見的中文和英文文字的處理方式。
英文處理
英文文字的處理相對簡單,每一個單詞之間有空格或標點符號隔開。如果不考慮短語,僅以單詞作為唯一的語義單元的話,處理英文單詞切分相對簡單,只需要分類多有單詞,去除標點符號。英文還需要考慮的一個問題是大小寫轉換,一般認為大小寫不具有不同的意義,這就要求將所有單詞的字幕都轉換成小寫或大寫。另外,英文文字預處理更為重要的問題是詞根的還原,或稱詞幹提取。詞根還原的任務就是講屬於同一個詞幹(Stem)的派生詞進行歸類轉化為統一形式。例如,把“computed”, “computer”, “computing”可以轉化為“compute”。通過使用一個給定的詞來代替一類中每一個元素,可以進一步增加類別與文件中的詞之間匹配度。詞根還原可以針對所有詞進行,也可以針對少部分詞進行或者不採用詞根還原。針對所有詞的詞根還原可能導致分類結果的下降,這主要的原因或許是刪除了不同形式單詞所含有的形式意義。哪些詞在哪些應用中應該詞根還原尚不清楚。McCallum等人研究工作顯示,詞根還原可能有損於分類效能。
中文處理
相對於英文來說,中文的文字處理相對複雜。中文的字與字之間沒有間隔,並且單個漢字具有的意義弱於片語。一般認為中文詞語為最小的語義單元,當然詞語可以由一個或多個漢字組成。中文文字分類首先要解決的難題就是中文分詞技術,用特殊符號(例如空格符)將中文具有獨立語義資訊的語義單元分割開。中文分詞是中文文字分類的前提條件。目前常用的中文分詞演算法可分為三大類:基於字串匹配的分詞方法、基於理解的分詞方法和基於統計的分詞方法。詳細介紹見中文分詞篇。
停用詞去除
停用詞(Stop Word)是一類普遍純在與文字中的常用詞,並且脫離語境它們本身並不具有明顯的意義。最常用的詞是一些典型的功能詞,這些詞構成句子的結構,但對於描述文字所表述的意義幾乎沒有作用,並且容易造成統計偏差,影響機器學習效果。在英文中這詞如:“the”、“of”、“for”、“with”、“to”等,在中文中如:“啊”、“了”、“並且”、“因此”等。由於這些詞的用處太普遍,去除這些詞,對於文字分類來說沒有什麼不利影響,相反可能改善機器學習效果。停用詞去除元件的任務比較簡單,只需從停用詞表中剔除別定義為停用詞的常用詞就可以了。儘管停用詞去除簡單,含有潛在優勢,但是停用詞去除與詞根還原具有同樣的問題,定義停用詞表中應該包含哪些詞確是比較困難,一般科研中停用詞表的規模為幾百。
文字表示
文字通常表現為一個由文字或字元與標點符號組成的符號串,由字或字元組成詞,由片語成短語,進而形成句子、段落、篇章結構。要使計算機能夠有效地處理文字串,就必需找到一種理想的文字表示方法,這種表示形式要既能夠真實的反應文字的內容又能區分不同文件。 向量空間模型(VSM,Vector Space Model)是目前文字處理應用領域使用最多且效果較好的文字表示法。VSM是20 世紀60年代末期由G. Salton等人提出的,最早用在SMART資訊檢索系統中。 定義:向量空間模型:給定文件D,如下
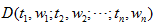
其中 tk 是組成文字的詞元素, 1<=k<=n; wk 是詞元素tk 的權重,或者說詞在文字中的某種重要程度。 性質:向量空間模型滿足以下兩條性質: a) 互異性:各片語元素間屬於集合元素關係,即若i!=j ,則 ti!=tj ; b) 無關性:各片語元素間無順序關係和相互聯絡,即對於文字D,若i!=j ,交換ti 與tj 的位置,仍表示文件D。片語與片語之間不含任何關係。 可以把片語t1, t2,…,tn 看成n維座標空間,而權重*w1, w2,…,wn*為相應座標值。因此,一個文字可以表示為一個n維向量。
特徵選擇
在向量空間模型中,文字可以選擇字、片語、短語、甚至“概念”等多種元素表示。這些元素用來表徵文字的性質,區別文字的屬性,因此這些元素可以被稱為文字的特徵。在文字資料集上一般含有數萬甚至數十萬個不同的片語,如此龐大的片語構成的向量規模驚人,計算機運算非常困難。進行特徵選擇,對文字分類具有重要的意義。特徵選擇就是要選擇那些最能表徵文字含義的片語元素。特徵選擇不僅可以降低問題的規模,還有助於分類效能的改善。選取不同的特徵對文字分類系統的效能有不同程度的影響。已提出的文字分類特徵選擇方法比較多,常用的方法有:文件頻率(Document Frequency,DF)、資訊增益(Information Gain,IG)、 校驗(CHI)和互資訊(Mutual Information,MI)等方法。另外特徵抽取[36]也是一種特徵降維技術,特徵抽取通過將原始的特徵進行變換運算,形成新的特徵。詳細內容見特徵選擇篇。
參考文獻: [1] 周志華.機器學習. 清華大學出版社,2016. [2] 邱江濤,唐常傑,曾濤,劉胤田.關聯文字分類的規則修正策略.計算機研究與發展,2009,46(4):683- 688. [3] Lewis,D.,Schapire,R.,Callan,J.,Papka,R. Training algorithms for linear text classifiers. In: Proc. of the ACM SIGIR. 1996:298−306. [4] Joachims,T. Text categorization with support vector machines: Learning with many relevant features In: Proc. of the Machine Learning: ECML’98, 10th European Conf. on Machine Learning. 1998:137−142. [5] Lewis,D. A comparison of two learning algorithms for text categorization . In: Proc. of Symp. On Document Analysis and IR. 1994. [6] Sebastiani,F. Machine learning in automated text categorization. ACM Comput. Surv. 2002, 34(1): 1-47. [7] 楊靜.基於SVM的中文電子郵件作者性別識別技術研究.河北:河北農業大學,2007. [8] 靖紅芳,王斌,楊雅輝,徐燕.基於類別分佈的特徵選擇框架.計算機研究與發展,2009,46(9):1586-1593.