
文字分類——常見分類模型
內容提要
文字分類方法模型主要分為兩個大類,一類是基於規則的分類模型;另一類是基於概率統計的模型。
基於規則的模型
基於規則的分類模型相對簡單,易於實現。它在特定領域的分類往往能夠取得較好的效果。相對於其它分類模型來說,基於規則的分類模型的優點就是時間複雜度低、運算速度快。在基於規則的分類模型中,使用許多條規則來表述類別。類別規則可以通過領域專家定義,也可以通過計算機學習獲得。
決策樹就是一種基於訓練學習方法獲取分類規則的常見分類模型,它建立物件屬性與物件值之間的一種對映。通過構造決策樹來對未標註文字進行分類判別。常用的決策樹方法包括CART 演算法、ID3、C4.5、CHAID 等。
在Web文字應用領域普遍存在著層級形式,這種層級形式可以通過一顆決策樹來描述。決策樹的根節點表示整個資料集空間,每個子節點是依據單一屬性做出的分支判定,該判定將資料集分成兩個或兩個以上的分支區域。決策樹的葉子節點就是相應類別的資料集合。
決策樹分類模型的一般構建過程:
1.首先將訓練資料分成兩部分,一部分(訓練集A)用於構建初始決策樹,另一部分(訓練集B)用來對決策樹進行剪枝;
2.以訓練集A作為樹的根節點,找出變異量最大的屬性變數作為高層分割標準;以訓練集A作為樹的根節點,找出變異量最大的屬性變數作為高層分割標準;
3.通過對訓練集A的學習訓練構建一顆初始決策樹;通過對訓練集A的學習訓練構建一顆初始決策樹;
4.再通過訓練集B對初始決策樹進行剪枝操作;再通過訓練集B對初始決策樹進行剪枝操作;
5.一般還要通過遞迴的過程來構建一顆穩定的決策樹,根據預測結果的正確率及未滿足條件,則再對決策樹進行分支或剪枝。
決策樹的構建過程一般是自上而下的,剪枝的方法有多種,但是具有一致目標,即對目標文字集進行最優分割。決策樹可以是二叉樹也可以是多叉樹。
基於概率的模型
假設未標註文件為d,類別集合為C={c1,c2,…,cm} ,概率模型分類是對1≤i≤n 求條件概率模型P(ci|d) ,將與文件d條件概率最大的那個類別作為該文件的輸出類別。其中樸素貝葉斯分類器是應用最為廣泛的概率分類模型。
樸素貝葉斯分類的基本思想是利用片語與類別的聯合概率來估計給定文件的類別概率。基於貝葉斯分類器的貝葉斯規則如式:
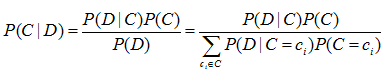
其中:C和D為隨機變數。
貝葉斯規則計算文件d屬於每一個類別的可能性 P(ci|d),然後將文件d標註為概率最大的那一類。對文件d的貝葉斯分類如下式
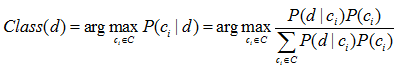
先驗概率P(ci) 的估計很簡單,計算如下式所示:
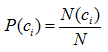
其中: N(ci) 表示訓練集中類別ci 的樣本數量,N為訓練集樣本總數。 本質上表示訓練集樣例中類別ci 的比例。
概率P(d|ci) 計算相對複雜,它首先基於一個貝葉斯假設:文件d為片語元素的集合,集合中片語(元素)之間相互獨立。由於文件的表示簡化了,所以這也就是樸素(Naïve) 的由來之一。事實上,片語之間並不是相互獨立的。雖然這是一種假設獨立性,但是樸素貝葉斯還是能夠在分類任務中表現出很好的分類效果和魯棒性。這一假設簡化了聯合概率的計算,它允許條件概率的乘機來表示聯合概率。P(d|ci) 的計算式:
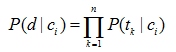
其中:tk 表示含有n項片語的片語表vi
概率的估計與分類結果非常依賴於事件空間的選擇。下面介紹兩種卡內基梅隆大學McCallum 和 Nigam 提出的事件空間模型,並說明相應的P(tk|ci) 是如何估計的。
1) 多重伯努利模型
多重伯努利(Multiple-Bernoulli)事件空間是一種布林獨立模型的事件空間,為每一個片語tk 建立一個二值隨機變數。最簡單的方式就是使用最大似然估計來估計概率,即式:
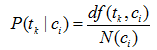
其中: df(tk|ci) 表示類別ci 含有片語tk 的樣本數量。
雖然上式來估計概率很簡單,但是存在“零概率”問題,真實應用是不可能的。這就需要採用平滑技術來克服“零概率”問題。貝葉斯平滑是一種常用的平滑估計技術。多重伯努利模型的平滑估計如下式所示:
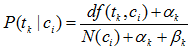
其中: αk 與βk 是依賴與片語tk 的引數。一種常見的引數選擇方式是αk =1且βk* =0,得到如下概率估計公式
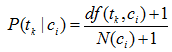
多重伯努利模型僅僅考慮片語是否出現,而沒有考慮出現的多少,而詞頻也是一個重要分類資訊。下面介紹加入詞頻資訊的多項式模型。
2) 多項式模型
多項式(Multinomial)時間空間與多重伯努利事件空間類似,但是多項式事件空間假設片語的出現次數是零次或多次,而不是出現與否。
多項式模型的最大似然估計計算如式:
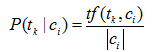
其中: tf(tk|ci) 表示訓練集中類別ci 中片語tk 出現的次數。 |ci|表示訓練集類別ci 中的總詞數。加入平滑估計的概率如式:
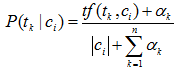
這裡 αk 是依賴於片語tk 的引數。對所有片語tk* 取αk =1是一種常見選擇。這就導致概率估計:
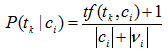
實際應用中,多項式模型已經表明優於多重伯努利模型。
基於幾何的模型
使用向量空間模型表示文字,文字就被表示為一個多維的向量,那麼它就是多維空間的一個點。通過幾何學原理構建一個超平面將不屬於同一個類別的文字區分開。最典型的基於幾何學原理的分類器是支援向量機(SVM),最簡單的SVM應用就是二值分類,就是常見的正例和反例。SVM的目標就是構建能夠區分正例和反例的N維空間決策超平面。
SVM是上世紀九十年代中期,由Vapnik等人逐漸完善的統計機器學習理論。該模型主要用來解決模式識別中的二分類問題,在文字分類、手寫識別、影象處理等領域都取得了很好的分類效果。其基本思想就是在向量空間中找到一個決策超平面,該決策超平面能夠最大限度地將正例和反例區分開來。在一定的範圍內,決策超平面是可以平行移動的,這種平移不會造成訓練集資料的分類錯誤。但是為了獲取在未知樣本的分類預測中的穩定性,要求分類超平面距離兩類樣本的距離儘可能大,也就是說,超平面儘可能位於邊界區域的中心位置。
SVM採用計算學習理論的結構風險最小化(Structural Risk Minimization, SRM)原則。其主要思想:以支援向量(Support Vector, SV)作為訓練集的基礎,在N維空間內尋找能將訓練集樣本分成兩類,並且具有最大邊緣(Margin)值的最優超平面(Optimal Separating Hyper-plane,OSH),來達到最大的分類正確率。
SVM選擇最大化邊緣距離的分類決策超平面,這個選擇不僅直觀,而且也得到了理論的支援。對於線性可分資料的超平面以及支援向量的圖形解釋如圖:
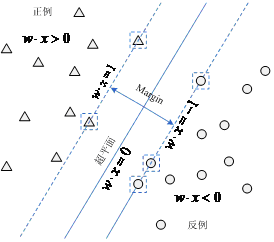
其中:左上方為正例區域,右下方為反例區域,中間實線為w定義的決策超平面,箭頭所示為邊緣,虛線方框內的樣本表示支援向量。邊緣(Margin)的定義如式:
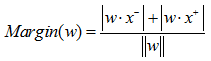
其中:x- 是訓練集距離超平面最近的反例, x+ 是訓練集距離超平面最近的正例。定義邊緣(Margin)為x- 到決策超平面距離與x+ 到決策超平面距離之和。
SVM演算法中超平面的概念是發現使分離資料最大邊緣化的超平面w。一個等價的形式是,尋找解決下列優化問題的決策超平面,如式:

這一優化目標容易求解,一般通過動態規劃來解決。
現實世界中的資料集很少是線性可分的。為了解決這個問題,一般需要修改SVM優化目標公式加入懲罰因子來完成不滿足線性可分約束的訓練例項的分類。加入了懲罰因子的SVM最優化目標如式:
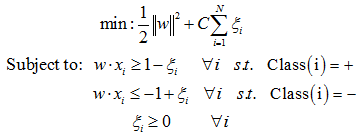
這裡ζi 表示允許目標被違反的鬆弛變數(Stack Variable),這個鬆弛變數加強了關鍵損失函式。
另外一個SVM關鍵技術是核技巧,通過核函式將線性不可分的訓練資料變換或對映到更高維空間中,得到線性可分的資料集。核函式技術大多數情形下都可以提高分類的精度。常用SVM核函式如下:
線性核:
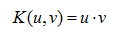
多項式核:
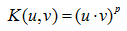
徑向基(RBF)核(也稱為高斯核):
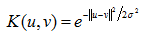
SVM能夠取得比較好的分類效果。其優點在於:
1.SVM是一種針對有限樣本條件下的分類演算法,其目標是得到當前訓練集下的最優解而不是樣本數趨於無窮大時的最優值,該演算法最終將問題轉化成二次線性規劃尋求最優解問題。從理論上來講,它得到的是全域性最優解,能夠避免區域性極值問題。
2.該方法將實際問題通過核函式技巧將線性不可分空間對映到高維線性可分空間,在高維空間中構造線性決策函式來實現原線性不可分空間的決策函式。這保證了SVM具有較好的推廣能力,計算的複雜度不再取決於空間維數,而是取決於訓練集樣本數量。
3.SVM方法能夠很好的處理稀疏資料,更好的捕捉了資料的內在特徵,準確率較高。
SVM雖然有許多優點,但是固有的缺點是不可避免的。其缺點包括:
1.SVM演算法時間和空間複雜度較高,隨著訓練樣本數和類別的增加,分類時間和空間代價很高。
2.核函式空間變換會增加訓練集空間的維數,使得SVM對時間和空間需求加大,又進一步降低了分類的效率。
3.SVM演算法一般含有較多引數,並且引數隨著訓練樣本的不同,呈現較大的差異,調整引數以獲得最優分類效果相對困難。而且引數的不同對分類結果的顯示出較大的差異性。
基於統計的模型
基於統計的機器學習方法已經成為自然語言研究領域裡面的主流研究方法。事實上無論是樸素貝葉斯分類模型,還是支援向量機分類模型,也都採用了統計的方式。文字分類演算法中一種最典型的基於統計的分類模型就是k近鄰(k-Nearest Neighbor,kNN)模型,是比較好的文字分類演算法之一。
kNN分類模型的主要思想:通過給定一個未標註文件d,分類系統在訓練集中查詢與它距離最接近的k篇相鄰(相似或相同)標註文件,然後根據這k篇鄰近文件的分類標註來確定文件d的類別。分類實現過程:
1) 將訓練集樣本轉化為向量空間模型表示形式並計算每一特徵的權重;
2) 採用類似步驟1的方式轉化未標註文件d並計算相應片語元素的權重;
3) 計算文件d與訓練集樣本中每一樣本的距離(或相似度);
4) 找出與文件d距離最小(或相似度最大)的k篇訓練集文字;
5) 統計這個k篇訓練集文字的類別屬性,一般將文件d的類歸為k中最多的樣本類別。
kNN 分類模型是一種“懶學習”演算法,實質上它沒有具體的訓練學習過程。分類過程只是將未標註文字與每一篇訓練集樣本進行相似度計算, kNN 演算法的時間和空間複雜度較高。因而隨著訓練集樣本的增加,分類的儲存資源消耗大,時間代價高。一般不適合處理訓練樣本較大的分類應用。
參考文獻:
[1].McCallum,A.,Nigam,K. A comparison of event models for naive Bayes text classification [C]. In: Proc. of the AAAI ’98 Workshop on Learning for Text Categorization. 41 - 48.
[2].宗成慶. 統計自然語言處理[M].北京:清華大學出版社,2008
[3].王斌,潘文峰.基於內容的垃圾郵件過濾技術綜述[J].中文資訊學報,19(5):1-10
[4].Yang,Y.,Liu,X. A re-examination of text categorization methods [C]. In: Proceedings of the 22nd ACM Int’l Conference on Research and Development in Information Retrieval. Berkeley: ACM Press: 42-49