
Data Distillation: Towards Omni-Supervised Learning
- Introduction
主要思想是用通過使用一個在大量已標記資料上訓練過的模型在未標記資料上生成annotations,然後再將所有的annotations(已有的或者新生成的)對模型進行重新訓練。作者將其思想同 G. Hinton, O. Vinyals, and J. Dean. 等人的Distilling the knowledge in a neural network. 的model distillation進行了對比
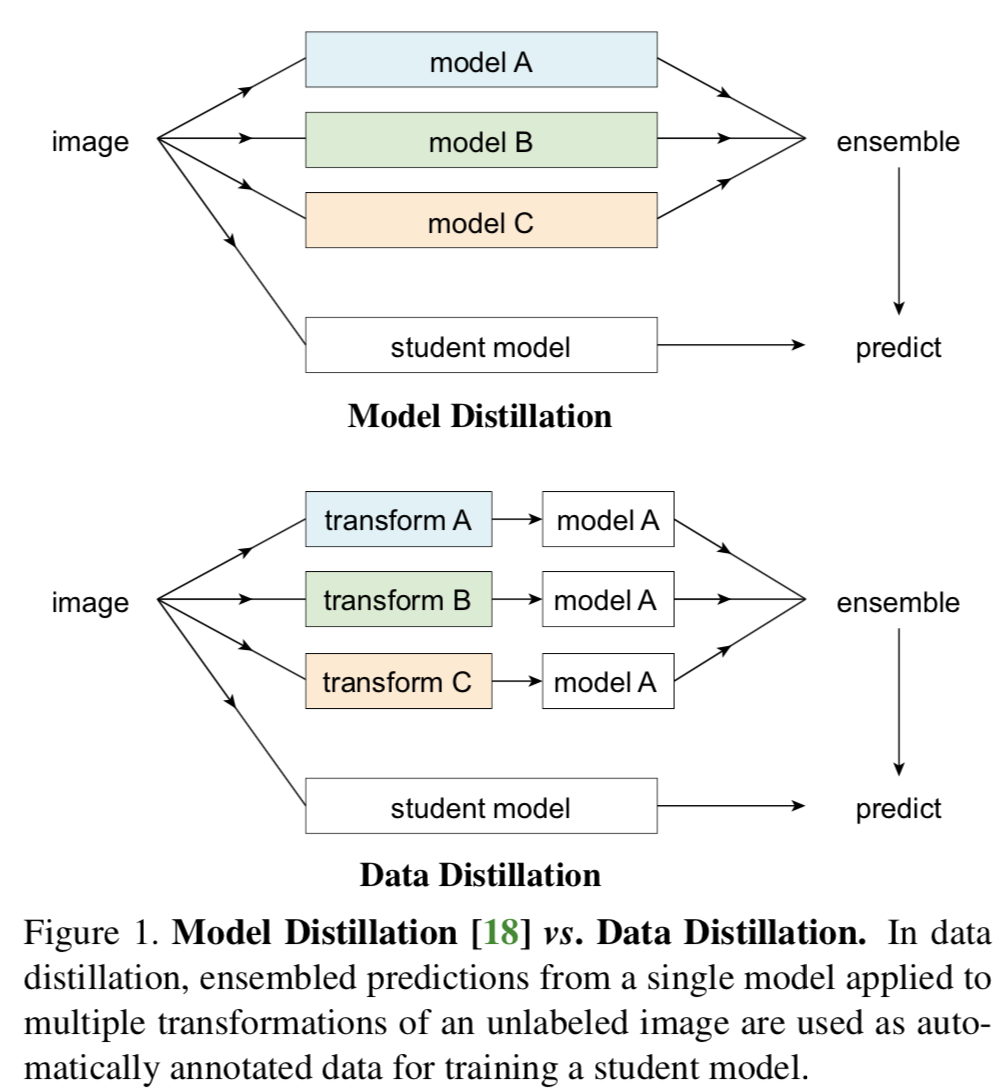
不同於Hinton等人從不同模型的預測中得出結論的思想,作者的方法則是通過對未標記資料的多種形式變換運用於同一個模型之上得出結論。
- Data Distillation
資料蒸餾主要包括4步:(1)首先在人工標記的資料上訓練一個模型;(2)將(1)中訓練好的模型運用到各種轉變形式過後的未標記的資料;(3)將(2)中得到的未標記資料轉變成它們通過模型獲得的預測;(4)將人工標記資料和預測資料進行彙總之後,對模型進行訓練。
1)multi-transform inference
比如,對輸入圖片進行multiple crops,或者對不同大小的圖片進行檢測之後彙總目標檢測的結果
2) Generating labels on unlabeled data
很自然地,對於只存在一種形式的資料進行多個模型的訓練和針對多種形式(將一種形式進行變換得到的多種資料)進行單個模型的訓練,後者效果肯定更好。
在多種形式的未標記資料上生成標籤的可行辦法有:用平均分類概率進行標記,這種方法可能存在兩個問題,一是最後得到的標籤可能是一個概率向量,因此我們需要通過調整它的損失函式來適應這種情況的產生,二是對於輸出空間結構化的問題而言,使用平均概率去處理要謹慎。
因此作者採用的方法是生成相同結構的hard labels以及在人工標記的資料中已經出現了的種類。
3) Knowledge distillation
從這一步開始,就採用一個新的模型(可以和之前的模型一樣也可以不一樣)在之前的人工資料以及被預測的資料的集合上進行訓練了,我們把這個模型叫做student model。在這一過程中,主要考慮了兩點,首先是每一個mini-batch,既要包括人工標記的資料也要包括自動標記的資料,第二是,在現在資料量充足的情況下,我們必須延長訓練時間來充分利用這些資料。
- Data Distillation for Key Point Detection
1) teacher 和 student model選擇的是Mask R-CNN, Mask R-CNN的backbone選擇的是 ResNet and ResNeXt with FPN
2) 資料變換選擇的是幾何變換,對於資料變換唯一的要求是最後的預測結果要適合ensemble。作者最後採取了兩種常用的資料變換的方法:scaling和水平旋轉。
3)在實驗中,為了簡化,作者只將多種形式變換資料的預測運用到了關鍵部位,比如頭部,其他部位則都來自於沒有進行過任何變換的資料。
4)選擇預測的標準是,選用預測目標得分來代表對預測質量的估計,並且只針對那些大於預測目標得分閾值生成annotation。當每張未標記圖片中平均標記物體大致等於已標記圖片中的平均物體個數。
5)生成關鍵點的annotation,標準同4)中類似。
6)再訓練中保持原始圖片和新生成標籤的圖片的比例為6:4
- Experiments on Keypoint Detection
1)測試集為COCO資料集
2)資料分割為三部分,即COCO已標記資料集、COCO未標記資料集以及 Sports-1M static frames
3)主要結果,在三種情況下進行了data distillation實驗,分別是:
a)小規模資料: co-35作為標記資料, co-80作為未標記資料
b)同分布的大規模資料: co-115作為標記資料, un-120作為未標記資料
c)不同分佈的大規模資料:co-115作為標記資料, s1m-180作為未標記資料
接下來這張表展示了結果:

從表(1)的(a)中可以得出,如果所有訓練資料都有標籤,那麼使用所有標籤可以提升半監督學習的準確性。從第二行可以看出,現實世界中總有一些資料是未標記的,因此我們可以追求一個稍微低一點的準確率。除此之外,當資料集較大時,能從未標記資料中獲得的資訊就越少。
表(1)的(b)中比較的是 只在co-115同“同分布的大規模資料: co-115作為標記資料, un-120作為未標記資料“的情況,可以看出每個實驗大概提升了1.7至2個百分點。作者同時提到近期另外一個實驗中通過增加一半資料提升了大約3個百分點,因此他們的效果是promising的。
表(1)的(c)中比較的是隻在co-115同“不同分佈的大規模資料:co-115作為標記資料, s1m-180作為未標記資料“的情況,可以看出後面兩張表的表現情況大致相同,因此作者認為他們的方法對於不同分佈的資料具有穩健型。
下面這張圖展示了第三個實驗的具體表現情況:
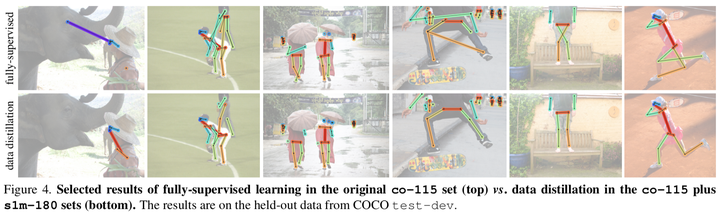
- Ablation Experiments
1)迭代次數
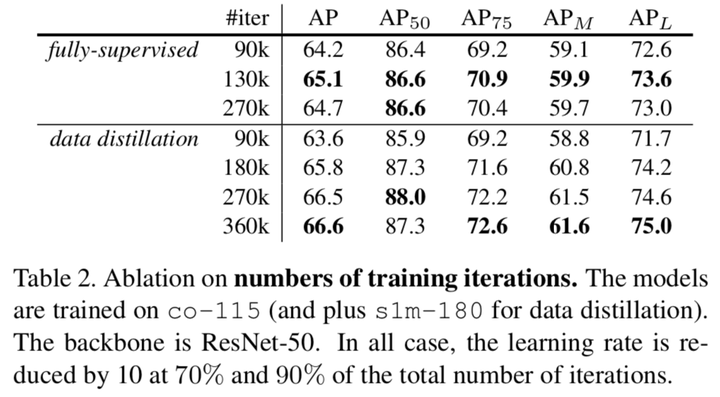
從這張表的第一欄中可以看出,增加迭代次數的確可以在一定程度上提升效果,但是如果不增大資料量的話,可能導致模型傾向於過擬合。
從這張表的第二欄中可以看出,當使用作者的方法時,增加迭代次數提升效果的作用是肯定的。當資料量較小的時候全監督比資料蒸餾方法要好是可以理解的,因為同gt相比,預測的標籤的準確性肯定是不能與之比較的,但是隨後作者方法的優越性就顯現了出來。
2)未標記資料的量
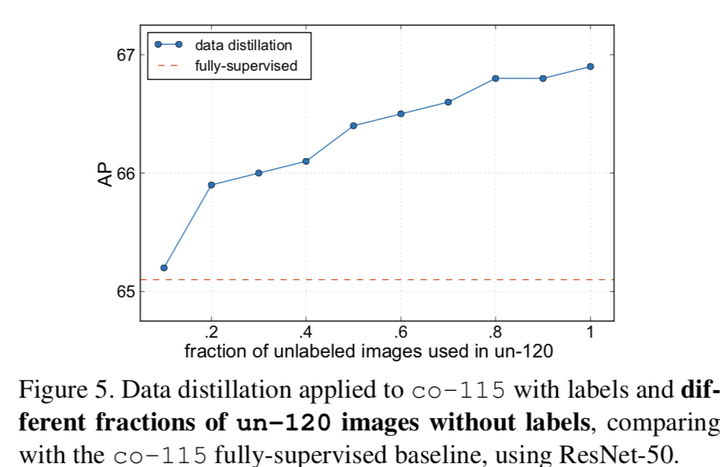
3)the impact of teacher quality
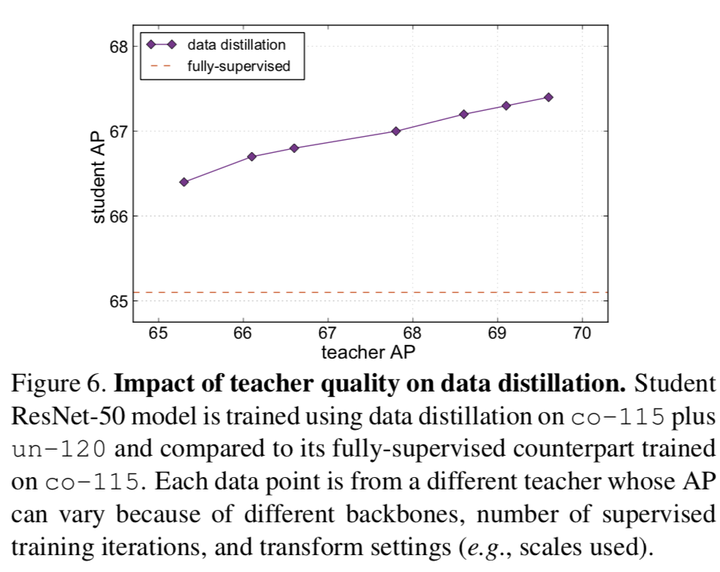
很自然,teacher model的AP越高,student model的AP自然也會更高。
4) test-time augmentation
將資料轉換同樣也實時運用到測試時,同樣可以提升模型表現
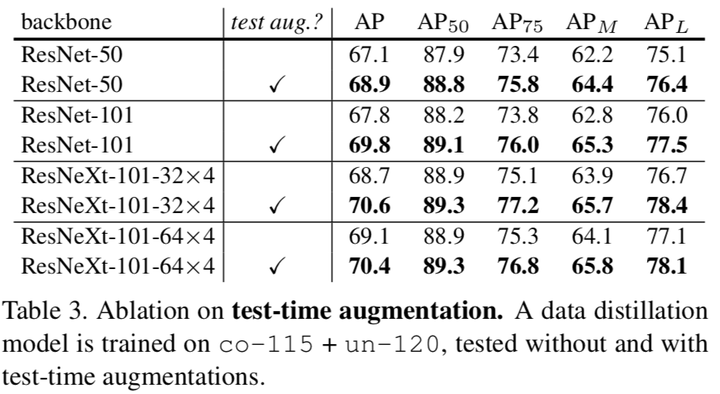
- 目標檢測實驗
小規模資料上的表現情況不是很好,有待研究。
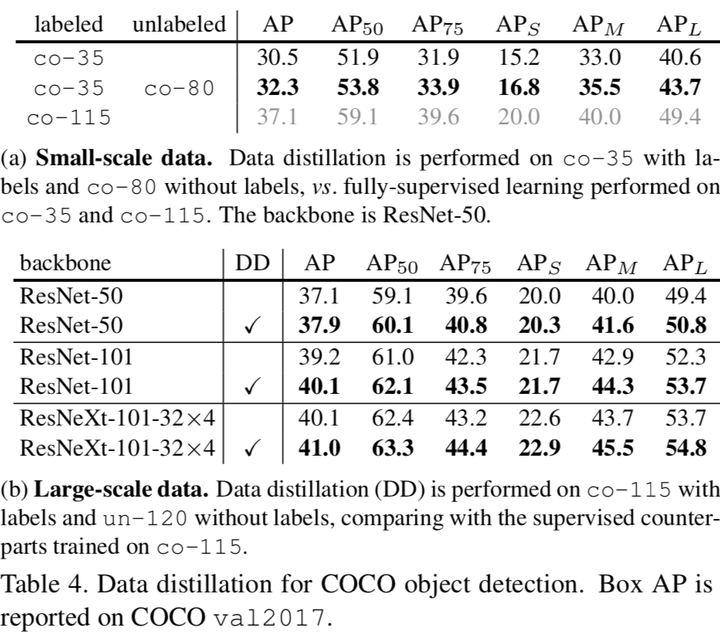
未標記資料在目標檢測上的應用是在是....作者說很challenging.