
Discriminative Information Retrieval for Question Answering Sentence Selection論文筆記
摘要
該演算法提出場景:text-based QA,即給定一段文字說明,提出問題,從文字說明中找出相應答案作答。
text-based QA演算法的主要步驟包含三個:1)獲取可能包含答案的段落;2)候選段落的重排;3)提取資訊選擇答案
本文的演算法主要是解決第一個步驟
演算法
演算法主要框架:
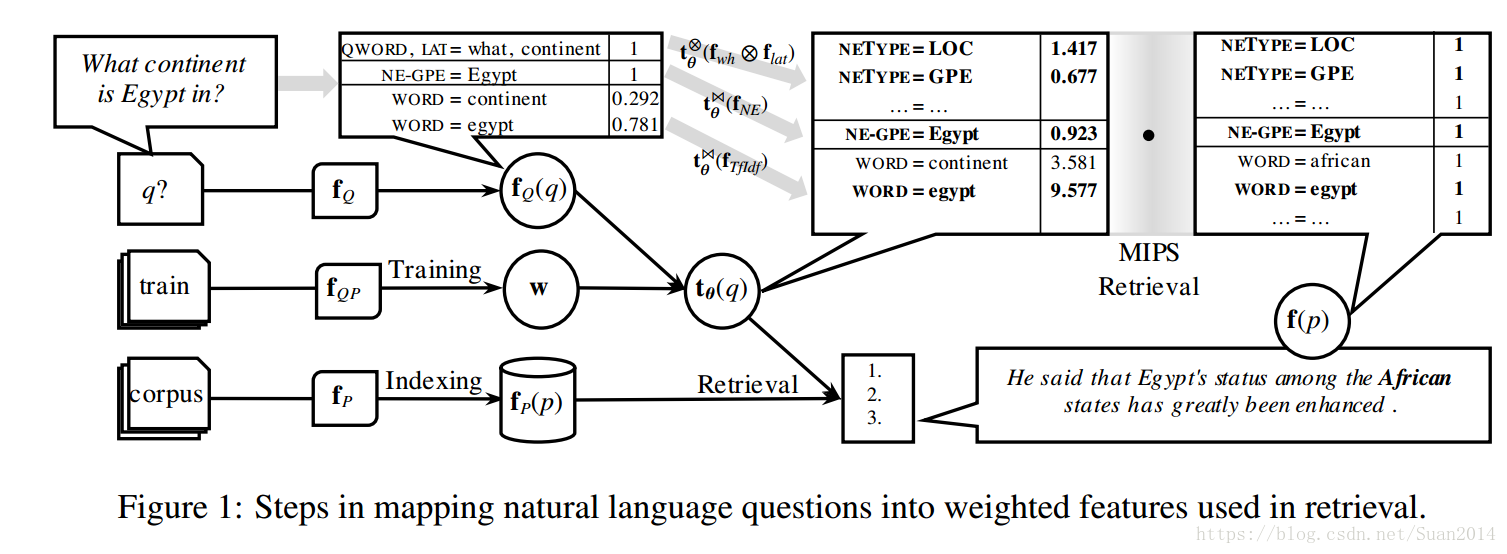
預處理:將文字說明切成一句一句,每句都作為第一步的候選集,設
設為query q的特徵,
為候選集p的特徵,
是由
和
合成的(query, candidate)對的特徵:
訓練權重向量,使得優化目標為:
,轉為:
(3),這樣
相當於將query q提取特徵後,先進行query expansion再採用點積與獲選集計算相似度得分。下邊將如何提取特徵
特徵
特徵向量f中的一個項表示為“(KEY = value,weight)”,並且特徵向量可以被視為一組這樣的元組,寫f(KEY = value)= weight表示特徵作為關聯陣列的關鍵,θX是訓練模型中特徵X的權重θ。
1.問題特徵
:問題詞,如問題是how many,則(QWORD=how many, 1)新增到特徵向量中;
:詞彙答案型別(LAT),如果query有問題詞:“what”或“which”這個問題的LAT被定義為問題詞之後的第一個名詞短語(NP)。 例如,“What is the city of brotherly love?”,該元組為(LAT = city,1)
:所有的命名實體,如:(NE-PERSON=Margaret Thatcher,1)
:tf-idf ,如
2.段落特徵(即候選句特徵)
:詞袋,段落中任何不同的x都會產生一個特徵
:命名實體型別。如果段落包含人名,則將生成(NETYPE = PERSON,1特徵
特徵向量演算法
1.合成
首先要實現公式2,對任何的query特徵向量fQ(q)= {(ki = vi,wi)},(wi≤1)和,定義兩個操作:
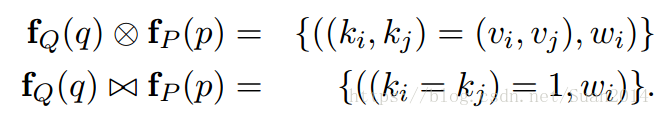
ki=kj表示ki和kj的值相同。
C定義:

2.對映
定義:,
,
則上式公式(3)中的t(theta)(q)得到表達
至此,通過(query, candidate)對進行訓練獲取theta值即可