
決策樹 Decision Tree 簡介
決策樹(Decision Tree)及其變種是另一類將輸入空間分成不同的區域,每個區域有獨立引數的演算法。決策樹分類演算法是一種基於例項的歸納學習方法,它能從給定的無序的訓練樣本中,提煉出樹型的分類模型。樹中的每個非葉子節點記錄了使用哪個特徵來進行類別的判斷,每個葉子節點則代表了最後判斷的類別。根節點到每個葉子節點均形成一條分類的路徑規則。而對新的樣本進行測試時,只需要從根節點開始,在每個分支節點進行測試,沿著相應的分支遞迴地進入子樹再測試,一直到達葉子節點,該葉子節點所代表的類別即是當前測試樣本的預測類別。
與其它機器學習分類演算法相比較,決策樹分類演算法相對簡單,只要訓練樣本集合能夠使用特徵向量和類別進行表示,就可以考慮構造決策樹分類演算法。預測分類演算法的複雜度只與決策樹的層數有關,是線性的,資料處理效率很高,適合於實時分類的場合。
機器學習中,決策樹是一個預測模型。它代表的是物件屬性與物件值之間的一種對映關係。樹中每個節點表示某個物件,而每個分支叉路徑則代表某個可能的屬性值,而每個葉節點則對應從根節點到該葉節點所經歷的路徑所表示的物件的值。決策樹僅有單一輸出,若欲有複數輸出,可以建立獨立的決策樹以處理不同輸出。資料探勘中決策樹是一種經常要用到的技術,可以用於分析資料,同樣也可以用來作預測。從資料產生決策樹的機器學習技術叫做決策樹學習,通俗說就是決策樹。
決策樹演算法包括訓練和測試兩個階段:在訓練階段,需要採用一定的標準和規則分割訓練樣本集為幾個子集,然後再以相同的規則去分割每個子集,遞迴這個過程,直到每個子集只含有屬於同一類的樣本時停止。訓練過程中,每個分割節點需要儲存好分類的屬性號。在測試階段中,將測試樣本從根節點開始進行判別,看該樣本屬於哪個子節點,同樣遞迴地執行下去,直到該樣本被分到葉節點中為止,而此時該樣本就屬於當前葉節點的類別。
由於決策樹分類方法的不穩定性,在訓練樣本集中的樣本數量較少時,樣本集中較小的變動也可能會導致決策樹結構發生很大變化。提高決策樹分類的穩定性,可以採用Bagging技術。讓決策樹演算法進行多輪的訓練,對測試樣本的類別預測採用投票的方式進行。
決策樹的樹枝節點表示屬性,也叫決策節點;樹葉節點表示類標籤,也叫決策結果。決策樹是由從上到下的根節點依次延伸而成,依據屬性閾值的差異性延伸到各個地方直至下一個屬性節點,一直延長到最後的葉子節點完成預測。
決策樹是一種樹形結構,它主要有三種不同的節點:決策節點:它表示的是一箇中間過程,主要是用來與一個數據集中各個屬性的取值作對比,以此來判斷下一步的決策走向趨勢。狀態節點:代表備選方案的期望值,通過各個狀態節點的對比,可以選出最佳的結果。結果節點:它代表的是該類最終屬於哪一個類別,同時也可以很清晰的看出該模型總共有多少個類別。最終,一個數據實例根據各個屬性的取值來得到它的決策節點。
統計學,資料探勘和機器學習中的決策樹訓練,使用決策樹作為預測模型來預測樣本的類標。這種決策樹也稱作分類數或迴歸數。在這些樹的結構裡,葉子節點給出類標而內部節點代表某個屬性。
決策樹學習:根據資料的屬性採用樹狀結構建立決策模型。決策樹模型常常用來解決分類和迴歸問題。機器學習中決策樹是一個預測模型,它表示物件屬性和物件值之間的一種對映,樹中的每一個節點表示物件屬性的判斷條件,其分支表示符號節點條件的物件。樹的葉節點表示物件所屬的預測結果。
決策樹是一種監督學習。根據決策樹的結構決策樹可分為二叉決策樹和多叉樹,例如有的決策樹演算法只產生二叉樹(其中,每個內部節點正好分叉出兩個分支),而另外一些決策樹演算法可能產生非二叉樹。
決策樹是從有類別名稱的訓練資料集中學習得到的決策樹。它是一種樹形結構的判別樹,樹內部的每個非葉子節點表示在某個屬性的判別條件,每個分支表示該判別條件的一個輸出,而每個葉子節點表示一個類別名稱。樹的首個節點是跟節點。
在決策樹模型構建完成後,應用該決策模型對一個給定的但類標號未知的元組X進行分類是通過測試該元組X的屬性值,得到一條由根節點到葉子節點的路徑,而葉子節點就存放著該元組的類預測。這樣就完成了一個未知類標號元組資料的分類,同時決策樹也可以表示成分類規則。
決策樹分量演算法有構造速度快、結構明顯、分類精度高等優點。決策樹是以例項(Instance)為核心的歸納分類方法。它從一組無序的、無特殊領域知識的資料集中提取出決策樹表現形式的分類規則,包含了分支節點、葉子節點和分支結構。它採用自頂向下的遞迴方式構造樹狀結構,在決策時分支節點進行基於屬性值的分類選擇,分支節點覆蓋了可能的分類結果,最終分支節點連線了代表分類結果的葉子節點。分類過程中經過的連線節點代表了一條分類模式,而這些分類模式的集合就組成了決策樹的框架。
決策樹是一種以歸納學習為基礎的分類演算法,它主要包括兩個階段:構造和剪枝。決策樹的構建過程是一種自頂向下、遞迴分治的過程,從決策表建立決策樹的關鍵步驟就是選擇分支屬性和劃分樣本集。決策樹的剪枝是使決策樹停止分裂的方法之一。先剪枝是在決策樹生成的過程中同時完成剪枝操作,提前停止節點的分類。選擇合適的測度值是先剪枝演算法的關鍵。先剪枝演算法避免了無謂的計算量浪費並且可以直接生成最終的分類數,因此被普遍採用。後剪枝演算法是在決策樹自由生長之後,通過指定相應測度值進行從分支到葉子節點的替換。後剪枝策略會加大決策樹演算法的計算量,但分類結果稍微準確。
決策樹的剪枝:剪枝是決策樹停止分支的方法之一,剪枝又分預先剪枝和後剪枝兩種。後剪枝的計算量代價比預剪枝方法大得多,特別是在大樣本集中,不過對於小樣本的情況,後剪枝方法還是優於預剪枝方法的。
常見決策樹分類演算法:
(1)、CLS演算法:是最原始的決策樹分類演算法,基本流程是,從一棵空數出發,不斷的從決策表選取屬性加入數的生長過程中,直到決策樹可以滿足分類要求為止。CLS演算法存在的主要問題是在新增屬性選取時有很大的隨機性。
(2)、ID3演算法:對CLS演算法的最大改進是摒棄了屬性選擇的隨機性,利用資訊熵的下降速度作為屬性選擇的度量。ID3是一種基於資訊熵的決策樹分類學習演算法,以資訊增益和資訊熵,作為物件分類的衡量標準。ID3演算法結構簡單、學習能力強、分類速度快適合大規模資料分類。但同時由於資訊增益的不穩定性,容易傾向於眾數屬性導致過度擬合,演算法抗干擾能力差。
ID3演算法的核心思想:根據樣本子集屬性取值的資訊增益值的大小來選擇決策屬性(即決策樹的非葉子結點),並根據該屬性的不同取值生成決策樹的分支,再對子集進行遞迴呼叫該方法,當所有子集的資料都只包含於同一個類別時結束。最後,根據生成的決策樹模型,對新的、未知類別的資料物件進行分類。
ID3演算法優點:方法簡單、計算量小、理論清晰、學習能力較強、比較適用於處理規模較大的學習問題。
ID3演算法缺點:傾向於選擇那些屬性取值比較多的屬性,在實際的應用中往往取值比較多的屬性對分類沒有太大價值、不能對連續屬性進行處理、對噪聲資料比較敏感、需計算每一個屬性的資訊增益值、計算代價較高。
(3)、C4.5演算法:基於ID3演算法的改進,主要包括:使用資訊增益率替換了資訊增益下降度作為屬性選擇的標準;在決策樹構造的同時進行剪枝操作;避免了樹的過度擬合情況;可以對不完整屬性和連續型資料進行處理;使用k交叉驗證降低了計算複雜度;針對資料構成形式,提升了演算法的普適性。
(4)、SLIQ演算法:該演算法具有高可擴充套件性和高可伸縮性特質,適合對大型資料集進行處理。
(5)、CART(Classification and RegressionTrees, CART)演算法:是一種二分遞迴分割技術,把當前樣本劃分為兩個子樣本,使得生成的每個非葉子節點都有兩個分支,因此,CART演算法生成的決策樹是結構簡潔的二叉樹。
分類迴歸樹演算法(Classification and Regression Trees,簡稱CART演算法)是一種基於二分遞迴分割技術的演算法。該演算法是將當前的樣本集,分為兩個樣本子集,這樣做就使得每一個非葉子節點最多隻有兩個分支。因此,使用CART演算法所建立的決策樹是一棵二叉樹,樹的結構簡單,與其它決策樹演算法相比,由該演算法生成的決策樹模型分類規則較少。
CART分類演算法的基本思想是:對訓練樣本集進行遞迴劃分自變數空間,並依次建立決策樹模型,然後採用驗證資料的方法進行樹枝修剪,從而得到一顆符合要求的決策樹分類模型。
CART分類演算法和C4.5演算法一樣既可以處理離散型資料,也可以處理連續型資料。CART分類演算法是根據基尼(gini)係數來選擇測試屬性,gini係數的值越小,劃分效果越好。設樣本集合為T,則T的gini係數值可由下式計算:
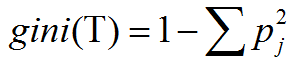
其中,pj是指類別j在樣本集T中出現的概率。若我們將T劃分為T1、T2兩個子集,則此次劃分的gini係數的值可由下式計算:
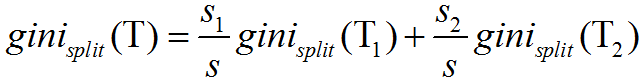
其中,s為樣本集T中總樣本的個數,s1為屬於子集T1的樣本個數,s2為屬於子集T2的樣本個數。
CART演算法優點:除了具有一般決策樹的高準確性、高效性、模式簡單等特點外,還具有一些自身的特點。如,CART演算法對目標變數和預測變數在概率分佈上沒有要求,這樣就避免了因目標變數與預測變數概率分佈的不同造成的結果;CART演算法能夠處理空缺值,這樣就避免了因空缺值造成的偏差;CART演算法能夠處理孤立的葉子結點,這樣可以避免因為資料集中與其它資料集具有不同的屬性的資料對進一步分支產生影響;CART演算法使用的是二元分支,能夠充分地運用資料集中的全部資料,進而發現全部樹的結構;比其它模型更容易理解,從模型中得到的規則能獲得非常直觀的解釋。
CART演算法缺點:CART演算法是一種大容量樣本集挖掘演算法,當樣本集比較小時不夠穩定;要求被選擇的屬性只能產生兩個子結點,當類別過多時,錯誤可能增加得比較快。
以上內容主要摘自:
1、《基於決策樹的檔案文字自動分類演算法研究》,雲南大學,碩論,2015
2、《一種改進的決策樹分類演算法》,華中師範大學,碩論,2016
3、《面向離散屬性的決策樹分類方法研究》,大連海事大學,碩論,2017