
分類演算法之決策樹(Decision tree)
1.1、決策樹引導
通俗來說,決策樹分類的思想類似於找物件。現想象一個女孩的母親要給這個女孩介紹男朋友,於是有了下面的對話:
女兒:多大年紀了?
母親:26。
女兒:長的帥不帥?
母親:挺帥的。
女兒:收入高不?
母親:不算很高,中等情況。
女兒:是公務員不?
母親:是,在稅務局上班呢。
女兒:那好,我去見見。
這個女孩的決策過程就是典型的分類樹決策。相當於通過年齡、長相、收入和是否公務員對將男人分為兩個類別:見和不見。假設這個女孩對男人的要求是:30歲以下、長相中等以上並且是高收入者或中等以上收入的公務員,那麼這個可以用下圖表示女孩的決策邏輯(宣告:此決策樹純屬為了寫文章而YY的產物,沒有任何根據,也不代表任何女孩的擇偶傾向,請各位女同胞莫質問我^_^
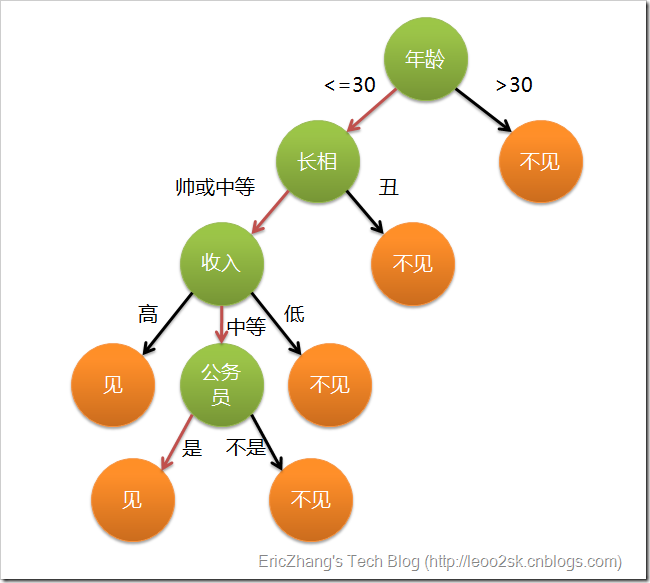
上圖完整表達了這個女孩決定是否見一個約會物件的策略,其中綠色節點表示判斷條件,橙色節點表示決策結果,箭頭表示在一個判斷條件在不同情況下的決策路徑,圖中紅色箭頭表示了上面例子中女孩的決策過程。
這幅圖基本可以算是一顆決策樹,說它“基本可以算”是因為圖中的判定條件沒有量化,如收入高中低等等,還不能算是嚴格意義上的決策樹,如果將所有條件量化,則就變成真正的決策樹了。
有了上面直觀的認識,我們可以正式定義決策樹了:
決策樹(decision tree)是一個樹結構(可以是二叉樹或非二叉樹)。其每個非葉節點表示一個特徵屬性上的測試,每個分支代表這個特徵屬性在某個值域上的輸出,而每個葉節點存放一個類別。使用決策樹進行決策的過程就是從根節點開始,測試待分類項中相應的特徵屬性,並按照其值選擇輸出分支,直到到達葉子節點,將葉子節點存放的類別作為決策結果。
可以看到,決策樹的決策過程非常直觀,容易被人理解。目前決策樹已經成功運用於醫學、製造產業、天文學、分支生物學以及商業等諸多領域。知道了決策樹的定義以及其應用方法,下面介紹決策樹的構造演算法。
1.2、決策樹的構造
不同於貝葉斯演算法,決策樹的構造過程不依賴領域知識,它使用屬性選擇度量來選擇將元組最好地劃分成不同的類的屬性。所謂決策樹的構造就是進行屬性選擇度量確定各個特徵屬性之間的拓撲結構。
構造決策樹的關鍵步驟是分裂屬性。所謂分裂屬性就是在某個節點處按照某一特徵屬性的不同劃分構造不同的分支,其目標是讓各個分裂子集儘可能地“純”。儘可能“純”就是儘量讓一個分裂子集中待分類項屬於同一類別。分裂屬性分為三種不同的情況:
1、屬性是離散值且不要求生成二叉決策樹。此時用屬性的每一個劃分作為一個分支。
2、屬性是離散值且要求生成二叉決策樹。此時使用屬性劃分的一個子集進行測試,按照“屬於此子集”和“不屬於此子集”分成兩個分支。
3、屬性是連續值。此時確定一個值作為分裂點split_point,按照>split_point和<=split_point生成兩個分支。
構造決策樹的關鍵性內容是進行屬性選擇度量,屬性選擇度量是一種選擇分裂準則,是將給定的類標記的訓練集合的資料劃分D“最好”地分成個體類的啟發式方法,它決定了拓撲結構及分裂點split_point的選擇。
屬性選擇度量演算法有很多,一般使用自頂向下遞迴分治法,並採用不回溯的貪心策略。這裡介紹ID3和C4.5兩種常用演算法。
1.2.1、ID3演算法
從資訊理論知識中我們直到,期望資訊越小,資訊增益越大,從而純度越高。所以ID3演算法的核心思想就是以資訊增益度量屬性選擇,選擇分裂後資訊增益最大的屬性進行分裂。下面先定義幾個要用到的概念。
設D為用類別對訓練元組進行的劃分,則D的熵(entropy)表示為:
其中pi表示第i個類別在整個訓練元組中出現的概率,可以用屬於此類別元素的數量除以訓練元組元素總數量作為估計。熵的實際意義表示是D中元組的類標號所需要的平均資訊量。
現在我們假設將訓練元組D按屬性A進行劃分,則A對D劃分的期望資訊為:
而資訊增益即為兩者的差值:
ID3演算法就是在每次需要分裂時,計算每個屬性的增益率,然後選擇增益率最大的屬性進行分裂。下面我們繼續用SNS社群中不真實賬號檢測的例子說明如何使用ID3演算法構造決策樹。為了簡單起見,我們假設訓練集合包含10個元素:
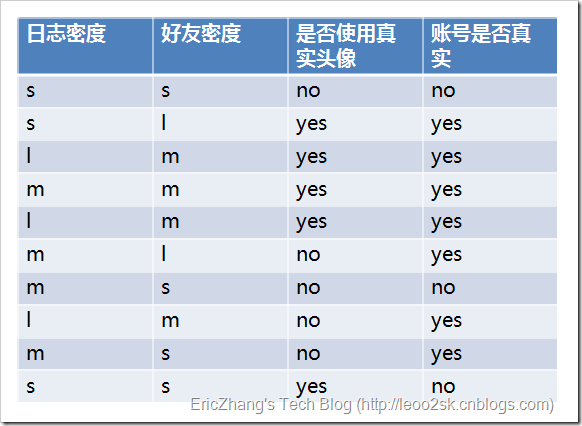
其中s、m和l分別表示小、中和大。
設L、F、H和R表示日誌密度、好友密度、是否使用真實頭像和賬號是否真實,下面計算各屬性的資訊增益。
因此日誌密度的資訊增益是0.276。
用同樣方法得到H和F的資訊增益分別為0.033和0.553。
因為F具有最大的資訊增益,所以第一次分裂選擇F為分裂屬性,分裂後的結果如下圖表示:
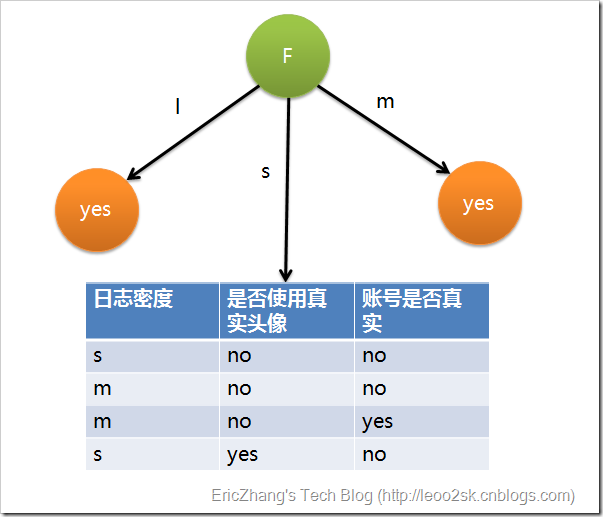
在上圖的基礎上,再遞迴使用這個方法計運算元節點的分裂屬性,最終就可以得到整個決策樹。
上面為了簡便,將特徵屬性離散化了,其實日誌密度和好友密度都是連續的屬性。對於特徵屬性為連續值,可以如此使用ID3演算法:
先將D中元素按照特徵屬性排序,則每兩個相鄰元素的中間點可以看做潛在分裂點,從第一個潛在分裂點開始,分裂D並計算兩個集合的期望資訊,具有最小期望資訊的點稱為這個屬性的最佳分裂點,其資訊期望作為此屬性的資訊期望。
1.2.2、C4.5演算法
ID3演算法存在一個問題,就是偏向於多值屬性,例如,如果存在唯一標識屬性ID,則ID3會選擇它作為分裂屬性,這樣雖然使得劃分充分純淨,但這種劃分對分類幾乎毫無用處。ID3的後繼演算法C4.5使用增益率(gain ratio)的資訊增益擴充,試圖克服這個偏倚。
C4.5演算法首先定義了“分裂資訊”,其定義可以表示成:
其中各符號意義與ID3演算法相同,然後,增益率被定義為:
C4.5選擇具有最大增益率的屬性作為分裂屬性,其具體應用與ID3類似,不再贅述。
1.3、關於決策樹的幾點補充說明
1.3.1、如果屬性用完了怎麼辦
在決策樹構造過程中可能會出現這種情況:所有屬性都作為分裂屬性用光了,但有的子集還不是純淨集,即集合內的元素不屬於同一類別。在這種情況下,由於沒有更多資訊可以使用了,一般對這些子集進行“多數表決”,即使用此子集中出現次數最多的類別作為此節點類別,然後將此節點作為葉子節點。
1.3.2、關於剪枝
在實際構造決策樹時,通常要進行剪枝,這時為了處理由於資料中的噪聲和離群點導致的過分擬合問題。剪枝有兩種:
先剪枝——在構造過程中,當某個節點滿足剪枝條件,則直接停止此分支的構造。
後剪枝——先構造完成完整的決策樹,再通過某些條件遍歷樹進行剪枝。
關於剪枝的具體演算法這裡不再詳述,有興趣的可以參考相關文獻。
相關推薦
演算法雜貨鋪——分類演算法之決策樹(Decision tree)
http://www.cnblogs.com/leoo2sk/archive/2010/09/19/decision-tree.html 3.1、摘要 在前面兩篇文章中,分別介紹和討論了樸素貝葉斯分類與貝葉斯網路兩種分類演算法。這兩種演算法都以貝葉斯定
分類演算法之決策樹(Decision tree)
1.1、決策樹引導 通俗來說,決策樹分類的思想類似於找物件。現想象一個女孩的母親要給這個女孩介紹男朋友,於是有了下面的對話: 女兒:多大年紀了? 母親:26。 女兒:長的帥不帥? 母親:挺帥的。 女兒:
機器學習之決策樹 Decision Tree(三)scikit-learn演算法庫
1、scikit-learn決策樹演算法類庫介紹 scikit-learn決策樹演算法類庫內部實現是使用了調優過的CART樹演算法,既可以做分類,又可以做迴歸。分類決策樹的類對應的是DecisionTreeClassifier,而回歸決策樹的類對應的是D
分類演算法之決策樹ID3詳解
回顧決策樹的基本知識,其構建過程主要有下述三個重要的問題: (1)資料是怎麼分裂的 (2)如何選擇分類的屬性 (3)什麼時候停止分裂 從上述三個問題出發,以實際的例子對ID3演算法進行闡述。 先上問題吧,我們統計了14天的氣象資料(指
【機器學習演算法-python實現】決策樹-Decision tree(1) 資訊熵劃分資料集
1.背景 決策書演算法是一種逼近離散數值的分類演算法,思路比較簡單,而且準確率較高。國際權威的學術組織,資料探勘國際會議ICDM (the IEEE International Con
機器學習入門 - 1. 介紹與決策樹(decision tree)
recursion machine learning programmming 機器學習(Machine Learning) 介紹與決策樹(Decision Tree)機器學習入門系列 是 個人學習過程中的一些記錄與心得。其主要以要點形式呈現,簡潔明了。1.什麽是機器學習?一個比較概括的理解是:
機器學習十大演算法之決策樹(詳細)
什麼是決策樹? 如何構建決策樹? ID3 C4.5 CART 決策樹的優缺點及改進 什麼是決策樹? 決策樹是運用於分類的一種樹結構,其本質是一顆由多個判斷節點組成的樹,其中的每個內部節點代表對某一屬性的一次測試,每條邊代表一個測試結果,而葉節點代表某個類或類的分佈。 屬於有監督學習 核心思想:
決策樹 ( decision tree)詳解
決策樹演算法的基本流程 決策樹顧名思義就是基於樹對問題的決策和判別的過程,是人類在面對決策問題時一種很自然的處理機制,下面有個例子 通過決策樹得出最終的結果。 &nb
決策樹(Decision Tree) | 繪製決策樹
01 起 在這篇文章中,我們講解了如何訓練決策樹,然後我們得到了一個字典巢狀格式的決策樹結果,這個結果不太直觀,不能一眼看著這顆“樹”的形狀、分支、屬性值等,怎麼辦呢? 本文就上文得到的決策樹,給出決策樹繪製函式,讓我們對我們訓練出的決策樹一目瞭然。 在繪製決
決策樹 (decision tree)
通過訓練,我們可以從樣本中學習到決策樹,作為預測模型來預測其它樣本。兩個問題: 我們說要訓練/學習,訓練/學習什麼? 為什麼決策樹可以用來預測?或者說它的泛化能力的來源是哪? #什麼是決策樹? 一棵“樹”,目的和作用是“決策”。一般來說,每個節點上都儲存了一個切分,輸入資料通過切分繼續訪問子節點,直到葉
機器學習十大經典演算法之決策樹(學習筆記整理)
一、決策樹概述 決策樹是一種樹形結構,其中每個內部節點表示一個屬性上的測試,每個分支代表一個測試輸出,每個葉節點代表一種類別。決策樹是一個預測模型,代表的是物件屬性與物件值之間的一種對映關係。 最初的節點稱為根節點(如圖中的"顏色"),有分支的節點稱為中間節點
決策樹 Decision Tree 簡介
決策樹(Decision Tree)及其變種是另一類將輸入空間分成不同的區域,每個區域有獨立引數的演算法。決策樹分類演算法是一種基於例項的歸納學習方法,它能從給定的無序的訓練樣本中,提煉出樹型的分類模型。樹中的每個非葉子節點記錄了使用哪個特徵來進行類別的判斷,每個葉子節點則代表
機器學習方法(四):決策樹Decision Tree原理與實現技巧
歡迎轉載,轉載請註明:本文出自Bin的專欄blog.csdn.net/xbinworld。 技術交流QQ群:433250724,歡迎對演算法、技術、應用感興趣的同學加入。 前面三篇寫了線性迴歸,lasso,和LARS的一些內容,這篇寫一下決策樹這個經典的分
機器學習---決策樹decision tree的應用
1.Python 2.Python機器學習的庫:scikit-learn 2.1 特性: 簡單高效的資料探勘和機器學習分析 對所有使用者開放,根據不同需求高度可重用性 基於Numpy,SciPy和matplotlib 開源的,且可達到商用級別,獲
4 決策樹(Decision Tree)
決策樹是一種基本的分類與迴歸方法 以下內容討論用於分類的決策樹,是由訓練資料集估計條件概率的模型 在學習時,利用訓練資料,根據損失函式最小化的原則建立決策樹,模型 在預測時,對新的資料,利用決策樹模型
資料探勘十大演算法之決策樹詳解(1)
在2006年12月召開的 IEEE 資料探勘國際會議上(ICDM, International Conference on Data Mining),與會的各位專家選出了當時的十大資料探勘演算法( top 10 data mining algorithms ),
決策樹(decision tree)的自我理解 (上)
最近在看周志華的《機器學習》,剛好看完決策樹這一章,因此結合網上的一些參考資料寫一下自己的理解。 何為決策樹? 決策樹是一種常見機器學習方法中的一種分類器。它通過訓練資料構建一種類似於流程圖的樹結構,
OpenCV3.3中決策樹(Decision Tree)介面簡介及使用
OpenCV 3.3中給出了決策樹Decision Tres演算法的實現,即cv::ml::DTrees類,此類的宣告在include/opencv2/ml.hpp檔案中,實現在modules/ml/src/tree.cpp檔案中。其中:(1)、cv::ml::DTrees類
決策樹decision tree分析
本文目的 最近一段時間在Coursera上學習Data Analysis,裡面有個assignment涉及到了決策樹,所以參考了一些決策樹方面的資料,現在將學習過程的筆記整理記錄於此,作為備忘。 演算法原理 決策樹(Decision Tree)是一種簡單但是廣泛使
決策樹(decision tree)的自我理解 (下) 關於剪枝和連續值缺失值處理
對剪枝的粗淺理解 剪枝分預剪枝和後剪枝,顧名思義,預剪枝就是在樹還沒完成之前,預先剪去樹的部分分支,後剪枝就是在整棵樹完成了之後對樹剪去部分分支,從而完成了對樹的精簡操作,避免了因屬性太多而造成的過擬合。 預剪枝(prepruning):在決策樹生成過程中,對每個結點在劃分