
機器學習筆記(二)吳恩達課程視訊
多元變數線性迴歸
1.多維特徵:
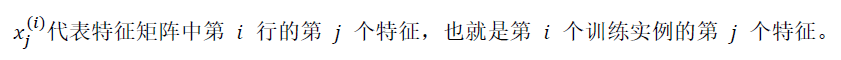
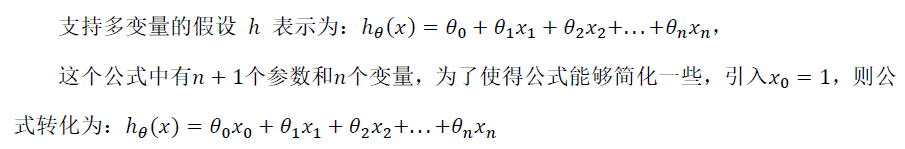
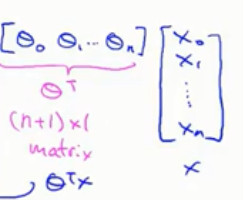

2.多元梯度下降:
代價函式:(目標與單變數一致,要找出使代價函式最小的一系列引數)
![]()
梯度下降演算法:

梯度下降演算法——特徵縮放:
除了固定以外,
的值都要變成[-1,1]範圍左右之間的取值,不僅僅是[-1,1],可以在該範圍內波動,但是不要幅度太大。
![]() (平均值指的是訓練集中不同組別的同一特徵值的平均值)
(平均值指的是訓練集中不同組別的同一特徵值的平均值)
梯度下降演算法——學習率
觀測演算法收斂的現象:可以繪製迭代次數與代價函式的的圖表;也可以將代價函式的變化與某個閾(如0.001)值進行比較。

根據不同的情況,建立不同的模型


3.正規方程

這樣求出來的?向量就是最優解,即該?向量中的n個?值為使得代價函式最小的一系列最優值。

相關推薦
機器學習筆記(二)吳恩達課程視訊
多元變數線性迴歸 1.多維特徵: 2.多元梯度下降: 代價函式:(目標與單變數一致,要找出使代價函式最小的一系列引數) 梯度下降演算法: 梯度下降演算法——特徵縮放: 除了固定以外,的值都要變成[-1,1]範圍左右之間的取值,不僅僅
機器學習筆記(六)-吳恩達視訊課程(神經網路學習 二)
1.代價函式 神經網路層數L,表示L層(最後一層)神經元個數,表示每層的輸出神經元數 二類分類:=1 輸出層有一個神經元,輸出的y是一個實數 y = 0 or 1 表示類別 多類別分類:一共有K類,則=K,輸出層有K個神經元,&nbs
機器學習筆記(八)-吳恩達視訊課程(支援向量機SVM)
1.支援向量機的優化目標 以下是新建的 SVM 的影象,左邊為y=1時,右邊為y=0時 然後進行轉換 2.SVM 被看做大邊界分類器(大間距)的情況 在y=1時, >= 1 代價函式為0 在y=0時, <=-
吳恩達機器學習筆記(二)(附程式設計作業連結)
吳恩達機器學習筆記(二) 標籤: 機器學習 一.邏輯迴歸(logistic regression) 1.邏輯函式&&S型函式(logistic function and sigmoid function) 線性迴歸的假設表示
模式識別與機器學習筆記(二)機器學習的基礎理論
機器學習是一門對數學有很高要求的學科,在正式開始學習之前,我們需要掌握一定的數學理論,主要包括概率論、決策論、資訊理論。 一、極大似然估計(Maximam Likelihood Estimation,MLE ) 在瞭解極大似然估計之前,我們首先要明確什麼是似然函式(likelihoo
機器學習筆記(二)線性迴歸實現
一、向量化 對於大量的求和運算,向量化思想往往能提高計算效率(利用線性代數運算庫),無論我們在使用MATLAB、Java等任何高階語言來編寫程式碼。 運算思想及程式碼對比 的同步更新過程向量化 向量化後的式子表示成為: 其中是一個向量,是一個實數,是一個向量,
機器學習筆記(二):python 模組pandas
1.讀csv檔案資料 import pandas as pd Info = pd.read_csv('titanic_train.csv'); #print(type(Info)) #Info的型別 <class 'pandas.core.frame
機器學習筆記(二):線性模型
線性模型是機器學習常用的眾多模型中最簡單的模型,但卻蘊含著機器學習中一些重要的基本思想。許多功能更為強大的非線性模型可線上性模型的基礎上通過引入層級結構或高維對映得到,因此瞭解線性模型對學習其他機器學習模型具有重要意義。 本文主要介紹機器學習中常用的線性模型,內
機器學習筆記(二)
總結自 《機器學習》周志華 模型評估與選擇 錯誤率=樣本總數/分類錯誤的樣本數 精度=1-錯誤率 誤差:實際預測輸出與樣本真實輸出之間的差異 訓練誤差:學習器在訓練集上的誤差 泛化誤差:學習器在新樣本上的誤差 過擬合:學習能力過於強大,將訓練樣本本身的一些不太一
機器學習筆記(二)——分類器之優缺點分析
原始資料中存在著大量不完整、不一致、有異常的資料,須進行資料清洗。資料清洗主要是刪除原始資料集中的無關資料、重複資料,平滑噪聲資料,篩選掉與挖掘主題無關的資料,處理缺失值、異常值。 一、線性分類器: f=w^T+b / logistic regression 學習方
機器學習筆記(二)矩估計,極大似然估計
1.引數估計:矩估計 樣本統計量 設X1,X2…Xn…為一組樣本,則 - 樣本均值 : X¯¯¯=1n∑i=1nXi - 樣本方差:S2=1n−1∑i=1n(Xi−X¯¯¯
機器學習筆記(二)L1,L2正則化
2.正則化 2.1 什麼是正則化? (截自李航《統計學習方法》) 常用的正則項有L1,L2等,這裡只介紹這兩種。 2.2 L1正則項 L1正則,又稱lasso,其公式為: L1=α∑kj=1|θj| 特點:約束θj的大小,並且可以產
斯坦福Andrew Ng---機器學習筆記(二):Logistic Regression(邏輯迴歸)
內容提要 這篇部落格的主要內容有: - 介紹欠擬合和過擬合的概念 - 從概率的角度解釋上一篇部落格中評價函式J(θ)” role=”presentation” style=”position: relative;”>J(θ)J(θ)為什麼用最
機器學習筆記(二)——廣泛應用於資料降維的PCA演算法實戰
最近在學習的過程當中,經常遇到PCA降維,於是就學習了PCA降維的原理,並用網上下載的iris.txt資料集進行PCA降維的實踐。為了方便以後翻閱,特此記錄下來。本文首先將介紹PCA降維的原理,然後進入實戰,編寫程式對iris.資料集進行降維。一、為什麼要進行資料降維?
機器學習筆記(二)——多變數最小二乘法
在上一節中,我們介紹了最簡單的學習演算法——最小二乘法去預測奧運會男子100米時間。但是可以發現,它的自變數只有一個:年份。通常,我們所面對的資料集往往不是單個特徵,而是有成千上萬個特徵組成。那麼我們就引入特徵的向量來表示,這裡涉及到矩陣的乘法,向量,矩陣求導等
機器學習筆記(二)矩陣和線性代數 例:用Python實現SVD分解進行圖片壓縮
線性代數基本只要是理工科,都是必修的一門課。當時學習的時候總是有一個疑惑,這個東西到底是幹嘛用的?為什麼數學家發明出這麼一套方法呢,感覺除了解方程沒發現有什麼大用啊!但隨著學習的深入,慢慢發現矩陣的應
Andrew Ng 機器學習筆記(二)
監督學習的應用:梯度下降 梯度下降演算法思想: 先選取一個初始點,他可能是0向量,也可能是個隨機點。在這裡選擇圖中這個+點吧。 然後請想象一下:如果把這個三點陣圖當成一個小山公園,而你整站在這個+
吳恩達機器學習筆記(六) —— 支持向量機SVM
次數 括號 圖片 最小 我們 支持向量機svm UNC 意思 strong 主要內容: 一.損失函數 二.決策邊界 三.Kernel 四.使用SVM 一.損失函數 二.決策邊界 對於: 當C非常大時,括號括起來的部分就接近於0,所以就變成了:
吳恩達機器學習筆記(一),含作業及附加題答案連結
吳恩達機器學習筆記(一) 標籤(空格分隔): 機器學習 吳恩達機器學習筆記一 一機器學習簡介 機器學習的定義 監督學習 非監督學習
吳恩達機器學習筆記(5)—— 神經網路
本教程將教大家如何快速簡單的搭起一個自己的部落格,並不會系統的教會你如何建站,但是可以讓掌握建站的基礎對以後web學習有一定的幫助。 購買一個域名 域名就相當於地址,我們就是通過域名來訪問我們的網站,現在萬網和騰訊雲都有廉價域名賣,首年大概1-5元一年吧。