
機器學習筆記(二)線性迴歸實現
一、向量化
對於大量的求和運算,向量化思想往往能提高計算效率(利用線性代數運算庫),無論我們在使用MATLAB、Java等任何高階語言來編寫程式碼。
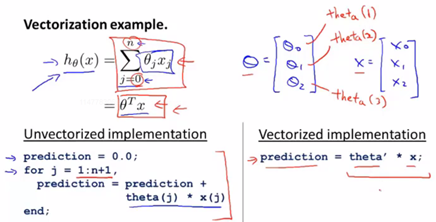
運算思想及程式碼對比

![]() 的同步更新過程向量化
的同步更新過程向量化
向量化後的式子表示成為:
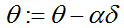
其中![]() 是一個向量,
是一個向量,![]() 是一個實數,
是一個實數,![]() 是一個向量,所以在這裡是做一個向量的減法。在將計算向量化的同時,這種運算方式使我們很好地實現了
是一個向量,所以在這裡是做一個向量的減法。在將計算向量化的同時,這種運算方式使我們很好地實現了![]() 的同步更新,我自行推導了一下,體會運算過程中的同步更新是如何實現。
的同步更新,我自行推導了一下,體會運算過程中的同步更新是如何實現。
二、 簡單一元線性迴歸實現
資料:是房子的大小(平方英尺)和房價(美元)之間的對應關係。
練習:Matlab實現
%簡單一元線性迴歸練習 theta_0 = 0; theta_1 = 0; alpha = 0.000001; x = [150; 200; 250; 300; 350; 400; 600]; y = [6450; 7450; 8450; 9450; 11450; 15450; 18450]; %畫出點 plot(x, y, 'r*', 'MarkerSize', 8); % 5控制*的大小 hold on; counter = 50; [theta_0, theta_1] = gradientDescent_LOW(x, y, theta_0, theta_1, alpha, counter); b = theta_0 + theta_1 * x; %畫出擬合直線 plot(x, b, 'b-', 'Linewidth',2); % 5控制*的大小 hold on; xlabel('面積/平方英尺'); ylabel('房價/美元'); title('一元線性迴歸');
function [theta_0, theta_1] = gradientDescent_LOW(x, y, theta_0, theta_1, alpha, counter)
%此處x為向量
m = length(y); %樣本數量
for iter = 1:counter
H = theta_0 + theta_1 * x; %線性假設函式
%計算代價函式輸出
res = 0;
for i = 1:m
res = res + (H(i)-y(i))^2;
end
Jtheta = res/(2*m)
%更新theta_0
sum = [0;0]; %記錄兩個偏導部分(求和過程)
for i = 1:m
sum(1,1) = sum(1,1) + (H(i)-y(i));
end
theta_0 = theta_0 - alpha * sum(1,1)/m;
%更新theta_1
for i = 1:m
sum(2,1) = sum(2,1) + (H(i)-y(i)) * x(i);
end
theta_1 = theta_1 - alpha* sum(2,1)/ m ;
end
得到擬合影象:
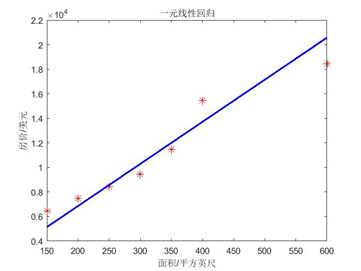
提出問題:
1. 使alpha、counter取值規範
加入特徵縮放後,alpha取0.03,counter = 1500。能夠達到較好的擬合效果。
%特徵縮放
for i = 1:length(y)
x(i) = (x(i)-min(x))/(max(x)-min(x))
y(i) = (y(i)-min(y))/(max(y)-min(y))
end

擬合影象
2. 梯度下降迭代結束標誌
a) 定義一個合理的閾值,當兩次迭代之間的差值小於該閾值時,迭代結束。
b) 設定一個大概的迭代步數,比如1000或500。
三、多元線性迴歸實現
1. 梯度下降法
資料:波士頓房價資料集(經個別剔除)共419條資料
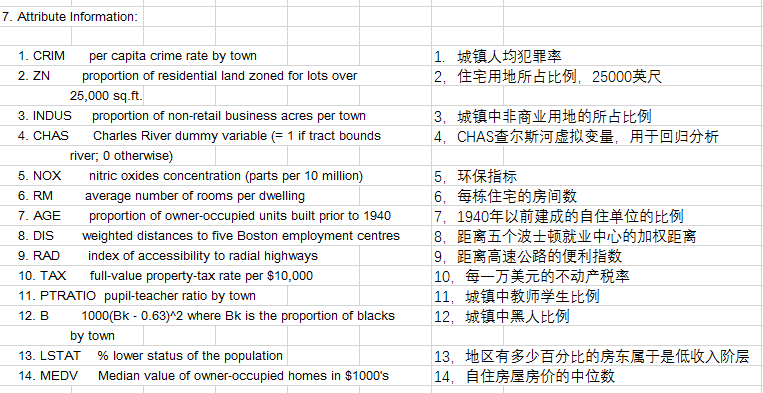
(理論推導見上一篇筆記,直接上程式碼)
%test2.m
[Data] = xlsread('Boston house prise.xlsx',1,'A1:M419');
[y] = xlsread('Boston house prise.xlsx',1,'N1:N419');
[m,n] = size(Data); % m樣本數量 n特徵數
Data = featureScaling(Data);
y = featureScaling(y);
x0 = ones(m,1);
X = ([x0,Data])';
Theta = zeros(n+1,1);
alpha = 0.009;
counter = 1500;
Theta = gradientDescent(X, y, Theta, alpha, counter);
plot(1:m, y, 'r-', 'Linewidth',1); % 5控制*的大小
hold on;
plot(1:m, Theta'*X, 'b-', 'Linewidth',1); % 5控制*的大小
hold on;
xlabel('樣例序號');
ylabel('房價');
title('梯度下降-波士頓房價預測');
legend('真實值','預測值');
%梯度下降(向量化)
function [Theta] = gradientDescent(X, y, Theta, alpha, counter)
% X Theta 均為矩陣
[m,n] = size(X); % m樣本數量 n特徵數
J_history = zeros(counter, 1);
for iter = 1:counter
H = Theta' * X; %線性假設函式
Delta = 1/m * X *(H'-y);
Theta = Theta - alpha * Delta;
% 儲存下所有J,可以檢視收斂情況
res = 0;
for i = 1:m
res = res + (H(i)-y(i))^2;
end
J_history(iter) = res/(2*m);
end
J_history
end
%特徵放縮
function [X] = featureScaling(X)
%X 為矩陣,每一列為一組特徵值
[m,n] = size(X);
for j = 1:n
for i = 1:m
X(i,j) = (X(i,j)-min(X(:,j)))*1/(max(X(:,j))-min(X(:,j)));
end
end
2. 正規方程法
(理論部分見上一篇筆記)
[X] = xlsread('Boston house prise.xlsx',1,'A1:M419');
[y] = xlsread('Boston house prise.xlsx',1,'N1:N419');
theta = pinv(X'* X)* X'*y
[m,n] = size(X); % m樣本數量 n特徵數
plot(1:m, y, 'r-', 'Linewidth',1);
plot(1:m, theta'*X', 'b-', 'Linewidth',1);
輸出結果:
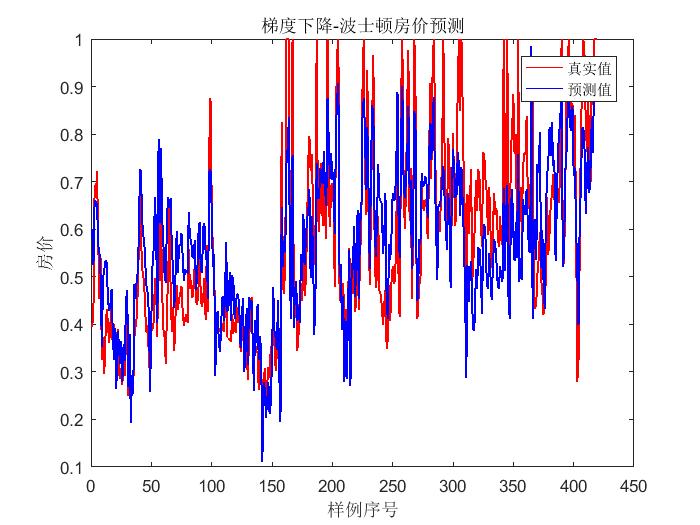
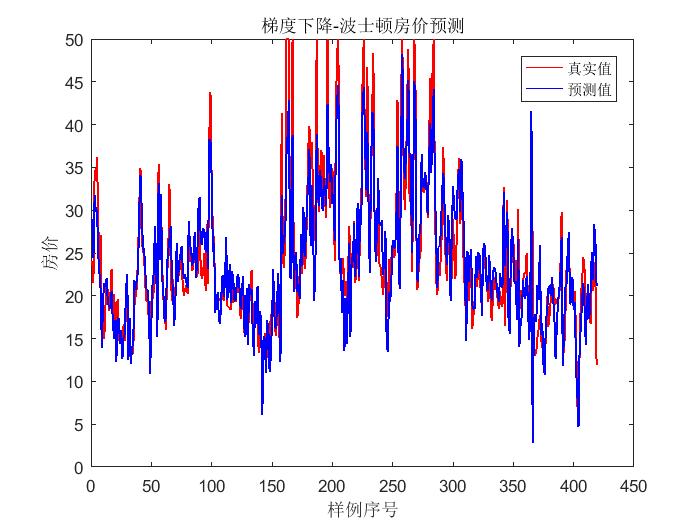
梯度下降法 正規方程法
總結:
1. 在運算中多用向量化的思想。
2. 在多元線性迴歸的實現中,隨著引數的增多,愈加體現出在梯度下降法當中,引數和初始值選擇對結果是有很大影響的。
3. 在本次用波士頓房價資料進行實驗的過程中,正規方程法的擬合效果優於梯度下降法。