
常見的神經網路模型大總結
由於新的神經網路架構無時無刻不在湧現,想要記錄所有的神經網路是很困難的事情。要把所有這些縮略語指代的網路(DCIGN,IiLSTM,DCGAN等)都弄清,一開始估計還無從下手。
下表包含了大部分常用的模型(大部分是神經網路還有一些其他的模型)。雖然這些架構都是新奇獨特的,但當我開始把它們的結果畫下來的時候,每種架構的底層關係就會清晰。

顯然這些節點圖並不能顯示各個模型的內部工作過程。例如變分自動編碼器(VAE)和自動編碼器(AE)節點圖看起來一樣,但是二者的訓練過程實際上是完全不同的,訓練後模型的使用場景更加不同。VAE是生成器,用於在樣本中插入噪聲。而 AE 則僅僅是將它們得到的輸入對映到它們“記憶”中最近的訓練樣本!本文不詳細介紹每個不同構架內部如何工作。
雖然大多數縮寫已經被普遍接受,但也會出現一些衝突。例如RNN通常指復發神經網路,有時也指遞迴神經網路,甚至在許多地方只是泛指各種復發架構(包括LSTM,GRU甚至雙向變體)。AE也一樣,VAE和DAE等都被簡單的稱為AE。此外,同一個模型的縮寫也會出現字尾N的個數不同的問題。同一個模型可以將其稱為卷積神經網路也可稱作卷積網路,對應的縮寫就成了CNN或CN
將本文作為完整的神經網路列表幾乎是不可能的,因為新的架構一直被髮明,即使新架構釋出了,想要找到他們也是困難的。因此本文可能會為您提供一些對AI世界的見解,但絕對不是所有; 特別是您在這篇文章發表很久之後才看到。
對於上圖中描繪的每個架構,本文做了非常簡短的描述。如果您對某些架構非常熟悉,您可能會發現其中一些有用。

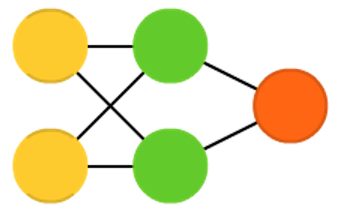
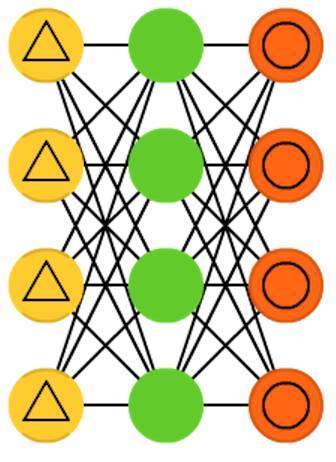
感知器(P左圖)和前饋神經網路(FF或FFNN右圖)非常直觀,它們將資訊從前端輸入,再從後端輸出。神經網路通常被描述為具有層(輸入,隱藏或輸出層),其中每層由並行的單元組成。通常同一層不具有連線、兩個相鄰層完全連線(每一層的每一個神經元到另一層的每個神經元)。最簡單的實用網路有兩個輸入單元和一個輸出單元,可用於建立邏輯模型( 用做判斷是否)。通常通過反向傳播方法來訓練FFNN,資料集由配對的輸入和輸出結果組成(這被稱為監督學習)。我們只給它輸入,讓網路填充輸出。反向傳播的誤差通常是填充輸出和實際輸出之間差異的一些變化(如MSE或僅僅線性差異)。鑑於網路具有足夠的隱藏神經元,理論上可以總是對輸入和輸出之間的關係建模。實際上它們的應用是很有限的,通常將它們與其他網路結合形成新的網路。
徑向基函式(RBF)網路就是以徑向基函式作為啟用函式的FFNN網路。但是RBFNN有其區別於FFNN的使用場景(由於發明時間問題大多數具有其他啟用功能的FFNN都沒有自己的名字)。
Hopfield網路(HN)的每個神經元被連線到其他神經元; 它的結構像一盤完全糾纏的義大利麵板。每個節點在訓練前輸入,然後在訓練期間隱藏並輸出。通過將神經元的值設定為期望的模式來訓練網路,此後權重不變。一旦訓練了一個或多個模式,網路將總是會收斂到其中一個學習模式,因為網路在這個狀態中是穩定的。需要注意的是,HN 不會總是與理想的狀態保持一致。網路穩定的部分原因在於總的“能量”或“溫度”在訓練過程中逐漸縮小。每個神經元都有一個被啟用的閾值,隨溫度發生變化,一旦超過輸入的總合,就會導致神經元變成兩個狀態中的一個(通常是 -1 或 1,有時候是 0 或 1)。更新網路可以同步進行,也可以依次輪流進行,後者更為常見。當輪流更新網路時,一個公平的隨機序列會被生成,每個單元會按照規定的次序進行更新。因此,當每個單元都經過更新而且不再發生變化時,你就能判斷出網路是穩定的(不再收斂)。這些網路也被稱為聯儲存器,因為它們會收斂到與輸入最相似的狀態;當人類看到半張桌子的時候,我們會想象出桌子的另一半,如果輸入一半噪音、一半桌子,HN 將收斂成一張桌子。
馬可夫鏈(MC或離散時間馬爾可夫鏈,DTMC)是BM和HN的前身。它可以這樣理解:從我現在的這個節點,我去任何一個鄰居節點的機率是無記,這意味著你最終選擇的節點完全取決於當前的所處的節點,l與過去所處的節點無關。這雖然不是真正的神經網路,但類似於神經網路,並且構成了BM和HNs的理論基礎。就像BM、RBM和HN一樣,MC並不總是被認為是神經網路。此外,馬爾科夫鏈也並不總是完全連線。
波爾茲曼機(BM)很像HN,區別在於只有一些神經元被標記為輸入神經元,而其他神經元保持“隱藏”。輸入神經元在完整的網路更新結束時成為輸出神經元。它以隨機權重開始,並通過反向傳播學習或通過對比分歧(一種馬爾科夫鏈用於確定兩個資訊增益之間的梯度)訓練模型。與HN相比,BM的神經元大多具有二元啟用模式。由於被MC訓練,BM是隨機網路。BM的訓練和執行過程與HN非常相似:將輸入神經元設定為某些鉗位值,從而釋放網路。雖然釋放節點可以獲得任何值,但這樣導致在輸入和隱藏層之間多次反覆。啟用由全域性閾值控制。這種全域性誤差逐漸降的過程導致網路最終達到平衡。
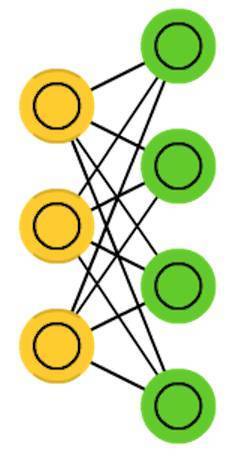
限制玻爾茲曼機(RBM)與BM非常相似,也與HN類似。BM和RBM之間的最大區別是,RBM有更好的可用性,因為它受到更多的限制。RBM不會將每個神經元連線到每個其他神經元,但只將每個神經元組連線到每個其他組,因此沒有輸入神經元直接連線到其他輸入神經元,也不會有隱藏層直接連線到隱藏層。RBM可以像FFNN一樣進行訓練,而不是將資料向前傳播然後反向傳播。
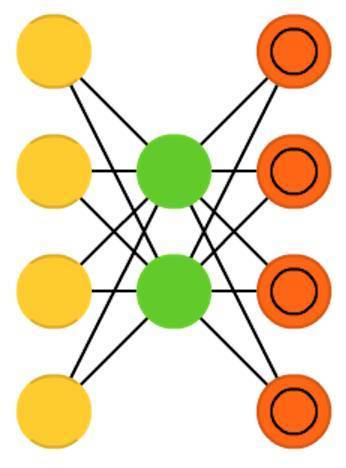
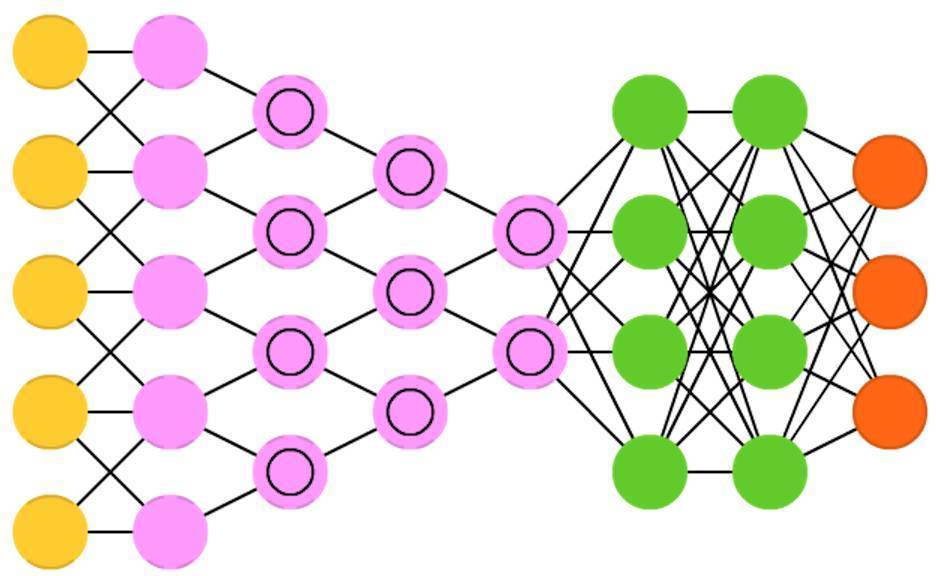
自編碼器(Autoencoders, AE)與前饋神經網路(FFNN)有點相似。與其說它是一個完全不同的網路結構,不如說它是前饋神經網路的不同應用。自編碼器的基本思想是:自動編碼資訊(如壓縮,而非加密)。由此,而得名。整個網路在形狀上像一個漏斗:它的隱藏層單元總是比輸入層和輸出層少。自編碼器總是關於中央層對稱(中央層是一個還是兩個取決於網路的層數:如果是奇數,關於最中間一層對稱;如果是偶數,關於最中間的兩層對稱)。最小的隱藏層總是處在中央層,這也是資訊最壓縮的地方(被稱為網路的阻塞點)。從輸入層到中央層叫做編碼部分,從中央層到輸出層叫做解碼部分,中央層叫做編碼(code)。可以使用反向傳播演算法來訓練自編碼器,將資料輸入網路,將誤差設定為輸入資料與網路輸出資料之間的差異。自編碼器的權重也是對稱的,即編碼權重和解碼權重是一樣的。
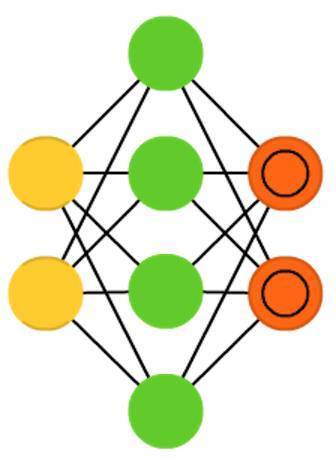
稀疏自編碼器(Sparse autoencoders, SAE)在某種程度上與自編碼器相反。不同於我們訓練一個網路在更低維的空間和結點上去表徵一堆資訊,在這裡我們嘗試著在更高維的空間上編碼資訊。所以在中央層,網路不是收斂的,而是擴張的。這種型別的網路可以用於提取資料集的特徵。如果我們用訓練自編碼器的方法來訓練稀疏自編碼,幾乎在所有的情況下,會得到一個完全無用的恆等網路(即,輸入什麼,網路就會輸出什麼,沒有任何轉換或者分解)。為了避免這種情況,在反饋輸入的過程中會加上一個稀疏驅動。這個稀疏驅動可以採用閾值過濾的形式,即只有特定的誤差可以逆傳播並被訓練,其他誤差被視為訓練無關的並被設定為零。某種程度上,這和脈衝神經網路相似:並非所有的神經元在每個時刻都會被啟用(這在生物學上有一定的合理性)
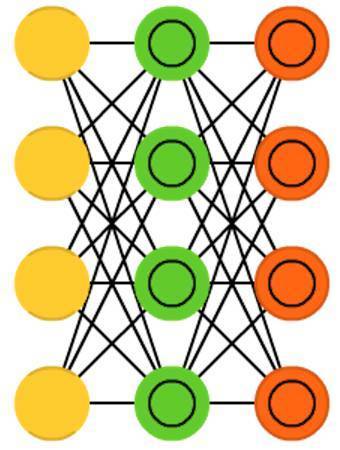
變分自編碼器(Variational autoencoders, VAE)和自編碼器有相同的網路結構,但是模型學到的一些其他的東西:輸入樣本的近似概率分佈。這一點和玻爾茲曼機(BM)、受限玻爾茲曼機(RBM)更相似。然而,他們依賴於貝葉斯數學,這涉及到概率推斷和獨立性,以及再引數化(reparametrisation)技巧以獲得不同的表徵。概率推斷和獨立性部分有直觀的意義,但是他們依賴於複雜的數學知識。基本原理如下:將影響考慮進去。如果一件事在一個地方發生,而另一件事在其他地方發生,那麼它們未必是相關的。如果它們不相關,那麼誤差逆傳播的過程中應該考慮這個。這種方法是有用的,因為神經網路是大型圖(在某種程度上),所以當進入更深的網路層時,你可以排除一些結點對於其他結點的影響。
去噪自編碼器(Denoising autoencoders, DAE)是一種自編碼器。在去噪自編碼器中,我們不是輸入原始資料,而是輸入帶噪聲的資料(好比讓影象更加的顆粒化)。但是我們用和之前一樣的方法計算誤差。所以網路的輸出是和沒有噪音的原始輸入資料相比較的。這鼓勵網路不僅僅學習細節,而且學習到更廣的特徵。因為特徵可能隨著噪音而不斷變化,所以一般網路學習到的特徵通常地錯誤的。
深度信念網路(Deep belief networks, DBN)是受限玻爾茲曼機或者變分自編碼器的堆疊結構。這些網路已經被證明是可有效訓練的。其中,每個自編碼器或者玻爾茲曼機只需要學習對之前的網路進行編碼。這種技術也被稱為貪婪訓練。貪婪是指在下降的過程中只求解區域性最優解,這個區域性最優解可能並非全域性最優解。深度信念網路能夠通過對比散度(contrastive divergence)或者反向傳播來訓練,並像常規的受限玻爾茲曼機或變分自編碼器那樣,學習將資料表示成概率模型。一旦模型通過無監督學習被訓練或收斂到一個(更)穩定的狀態,它可以被用作生成新資料。如果使用對比散度訓練,它甚至可以對現有資料進行分類,因為神經元被教導尋找不同的特徵。
卷積神經網路(Convolutional neural networks, CNN, or Deep convolutional neural networks, DCNN)和大多數其他網路完全不同。它們主要用於影象處理,但也可用於其他型別的輸入,如音訊。卷積神經網路的一個典型應用是:將圖片輸入網路,網路將對圖片進行分類。例如,如果你輸入一張貓的圖片,它將輸出“貓”;如果你輸入一張狗的圖片,它將輸出“狗”。卷積神經網路傾向於使用一個輸入“掃描器”,而不是一次性解析所有的訓練資料。舉個例子,為了輸入一張200 x 200畫素的圖片,你不需要使用一個有40000個結點的輸入層。相反,你只要建立一個掃描層,這個輸入層只有20 x 20個結點,你可以輸入圖片最開始的20 x 20畫素(通常從圖片的左上角開始)。一旦你傳遞了這20 x 20畫素資料(可能使用它進行了訓練),你又可以輸入下一個20 x 20畫素:將“掃描器”向右移動一個畫素。注意,不要移動超過20個畫素(或者其他“掃描器”寬度)。你不是將影象解剖為20 x 20的塊,而是在一點點移動“掃描器“。然後,這些輸入資料前饋到卷積層而非普通層。卷積層的結點並不是全連線的。每個結點只和它鄰近的節點(cell)相關聯(多靠近取決於應用實現,但是通常不會超過幾個)。這些卷積層隨著網路的加深會逐漸收縮,通常卷積層數是輸入的因子。(所以,如果輸入是20,可能接下來的卷積層是10,再接下來是5)。2的冪是經常被使用的,因為它們能夠被整除:32,16,8,4,2,1。除了卷積層,還有特徵池化層。池化是一種過濾細節的方法:最常用的池化技術是最大池化(max pooling)。比如,使用2 x 2畫素,取這四個畫素中數值最大的那個。為了將卷積神經網路應用到音訊,逐段輸入剪輯長度的輸入音訊波。卷積神經網路在真實世界的應用通常會在最後加入一個前饋神經網路(FFNN)以進一步處理資料,這允許了高度非線性特徵對映。這些網路被稱為DCNN,但是這些名字和縮寫通常是可以交換使用的。
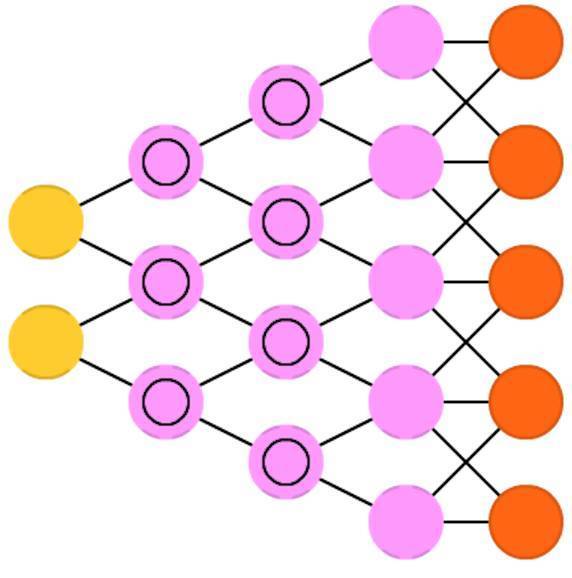
反捲積神經網路(Deconvolutional networks, DN),也叫做逆向圖網路(inverse graphics networks, IGN)。它是反向卷積神經網路。想象一下,將一個單詞”貓“輸入神經網路,並通過比較網路輸出和真實貓的圖片之間的差異來訓練網路模型,最終產生一個看上去像貓的圖片。反捲積神經網路可以像常規的卷積神經網路一樣結合前饋神經網路使用,但是這可能涉及到新的名字縮寫。它們可能是深度反捲積神經網路,但是你可能傾向於:當你在反捲積神經網路前面或者後面加上前饋神經網路,它們可能是新的網路結構而應該取新的名字。值得注意的事,在真實的應用中,你不可能直接把文字輸入網路,而應該輸入一個二分類向量。如,<0,1>是貓,<1,0>是狗,而<1,1>是貓和狗。在卷積神經網路中有池化層,在這裡通常被相似的反向操作替代,通常是有偏的插補或者外推(比如,如果池化層使用最大池化,當反向操作時,可以產生其他更低的新資料來填充)
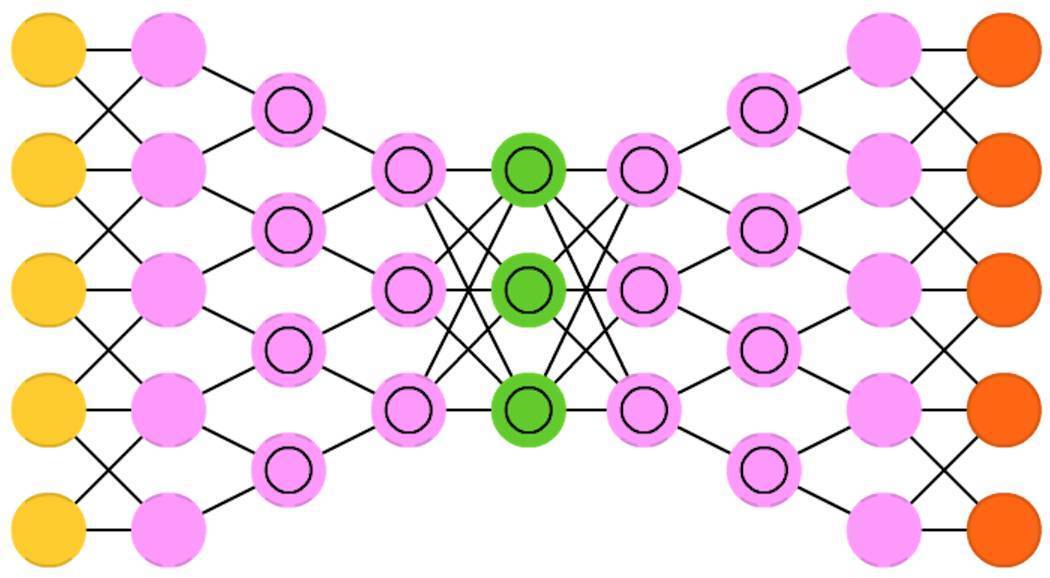
深度卷積逆向圖網路(Deep convolutional inverse graphics networks , DCIGN),這個名字具有一定的誤導性,因為事實上它們是變分自編碼器(VAE),只是在編碼器和解碼器中分別有卷積神經網路(CNN)和反捲積神經網路(DNN)。這些網路嘗試在編碼的過程中對“特徵“進行概率建模,這樣一來,你只要用貓和狗的獨照,就能讓網路學會生成一張貓和狗的合照。同樣的,你可以輸入一張貓的照片,如果貓的旁邊有一隻惱人的鄰居家的狗,你可以讓網路將狗去掉。實驗顯示,這些網路也可以用來學習對影象進行復雜轉換,比如,改變3D物體的光源或者對物體進行旋轉操作。這些網路通常用反向傳播進行訓練。
生成式對抗網路(Generative adversarial networks , GAN)是一種新的網路。網路是成對出現的:兩個網路一起工作。生成式對抗網路可以由任何兩個網路構成(儘管通常情況下是前饋神經網路和卷積神經網路配對),其中一個網路負責生成內容,另外一個負責對內容進行判別。判別網路同時接收訓練資料和生成網路生成的資料。判別網路能夠正確地預測資料來源,然後被用作生成網路的誤差部分。這形成了一種對抗:判別器在辨識真實資料和生成資料方面做得越來越好,而生成器努力地生成判別器難以辨識的資料。這種網路取得了比較好的效果,部分原因是:即使是很複雜的噪音模式最終也是可以預測的,但生成與輸入資料相似的特徵的內容更難辨別。生成式對抗網路很難訓練,因為你不僅僅要訓練兩個網路(它們中的任意一個都有自己的問題),而且還要考慮兩個網路的動態平衡。如果預測或者生成部分變得比另一個好,那麼網路最終不會收斂。
迴圈神經網路(Recurrent neural networks , RNN)是考慮時間的前饋神經網路:它們並不是無狀態的;通道與通道之間通過時間存在這一定聯絡。神經元不僅接收來上一層神經網路的資訊,還接收上一通道的資訊。這就意味著你輸入神經網路以及用來訓練網路的資料的順序很重要:輸入”牛奶“、”餅乾“和輸入”餅乾“、”牛奶“會產生不一樣的結果。迴圈神經網路最大的問題是梯度消失(或者梯度爆炸),這取決於使用的啟用函式。在這種情況下,隨著時間資訊會快速消失,正如隨著前饋神經網路的深度增加,資訊會丟失。直觀上,這並不是一個大問題,因為它們只是權重而非神經元狀態。但是隨著時間,權重已經儲存了過去的資訊。如果權重達到了0或者1000000,先前的狀態就變得沒有資訊價值了。卷積神經網路可以應用到很多領域,大部分形式的資料並沒有真正的時間軸(不像聲音、視訊),但是可以表示為序列形式。對於一張圖片或者是一段文字的字串,可以在每個時間點一次輸入一個畫素或者一個字元。所以,依賴於時間的權重能夠用於表示序列前一秒的資訊,而不是幾秒前的資訊。通常,對於預測未來資訊或者補全資訊,迴圈神經網路是一個好的選擇,比如自動補全功能。
長短時記憶網路(Long / short term memory , LSTM)通過引入門結構(gate)和一個明確定義的記憶單元(memory cell)來嘗試克服梯度消失或者梯度爆炸的問題。這一思想大部分是從電路學中獲得的啟發,而不是從生物學。每個神經元有一個記憶單元和是三個門結構:輸入、輸出和忘記。這些門結構的功能是通過禁止或允許資訊的流動來保護資訊。輸入門結構決定了有多少來自上一層的資訊被儲存當前記憶單元。輸出門結構承擔了另一端的工作,決定下一層可以瞭解到多少這一層的資訊。忘記門結構初看很奇怪,但是有時候忘記是必要的:
如果網路正在學習一本書,並開始了新的章節,那麼忘記前一章的一些人物角色是有必要的。
長短時記憶網路被證明能夠學習複雜的序列,比如:像莎士比亞一樣寫作,或者合成簡單的音樂。值得注意的是,這些門結構中的每一個都對前一個神經元中的記憶單元賦有權重,所以一般需要更多的資源來執行。
門控迴圈單元(Gated recurrent units , GRU)是長短時記憶網路的一種變體。不同之處在於,沒有輸入門、輸出門、忘記門,它只有一個更新門。該更新門確定了從上一個狀態保留多少資訊以及有多少來自上一層的資訊得以保留。 這個復位門的功能很像LSTM的忘記門,但它的位置略有不同。 它總是發出全部狀態,但是沒有輸出門。 在大多數情況下,它們與LSTM的功能非常相似,最大的區別在於GRU稍快,執行容易(但表達能力更差)。 在實踐中,這些往往會相互抵消,因為當你需要一個更大的網路來獲得更強的表現力時,往往會抵消效能優勢。在不需要額外表現力的情況下,GRU可能優於LSTM。
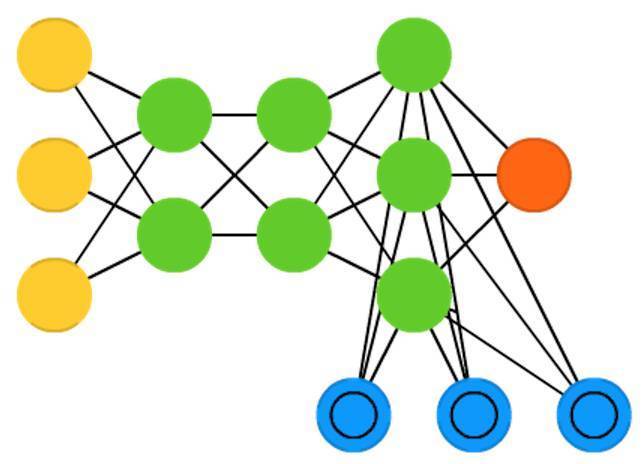
神經圖靈機(Neural Turing machines , NTM)可以被理解為LSTM的抽象,它試圖去黑箱化(使我們能夠洞察到發生了什麼)。神經圖靈機並非直接編碼記憶單元到神經元中,它的記憶單元是分離的。它試圖將常規數字儲存的效率和永久性以及神經網路的效率和表達力結合起來。這種想法基於有一個內容定址的記憶庫,神經網路可以從中讀寫。神經圖靈機中的”圖靈“(Turing)來自於圖靈完備(Turing complete):基於它所讀取的內容讀、寫和改變狀態的能力,這意味著它能表達一個通用圖靈機可表達的一切事情。
雙向迴圈神經網路、雙向長短時記憶網路、雙向門控迴圈單元(Bidirectional recurrent neural networks, BiRNN; bidirectional long / short term memory networks, BiLSTM; bidirectional gated recurrent units, BiGRU)在表中沒有展示出來,因為它們看起來和相應的單向網路是一樣的。不同之處在於這些網路不僅聯絡過去,還與未來相關聯。比如,單向長短時記憶網路被用來預測單詞”fish“的訓練過程是這樣的:逐個字母地輸入單詞“fish”, 在這裡迴圈連線隨時間記住最後的值。而雙向長短時記憶網路為了提供未來的資訊,會在反向通道中會輸入下一個字母。這種方法訓練網路以填補空白而非預測未來資訊,比如,在影象處理中,它並非擴充套件影象的邊界,而是可以填補一張圖片中的缺失。
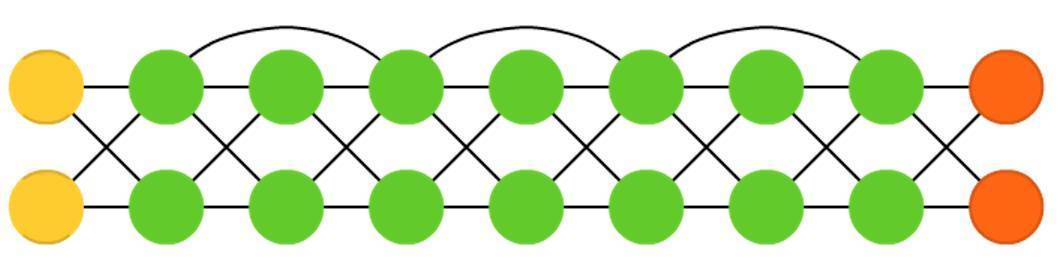
深度殘差網路(Deep residual networks , DRN)是具有非常深度的前饋神經網路,除了鄰近層之間有連線,它可以將輸入從一層傳到後面幾層(通常是2到5層)。深度殘差網路並非將一些輸入(比如通過一個5層網路)對映到輸出,而是學習將一些輸入對映到一些輸出+輸入上。基本上,它增加了一個恆等函式,將舊的輸入作為後面層的新輸入。結果顯示,當達到150 層,這些網路對於模式學習是非常有效的,這要比常規的2到5層多得多。然而,有結果證明這些網路本質上是沒有基於具體時間建造的迴圈神經網路(RNN),它們總是與沒有門結構的長短時記憶網路(LSTM)作比較。
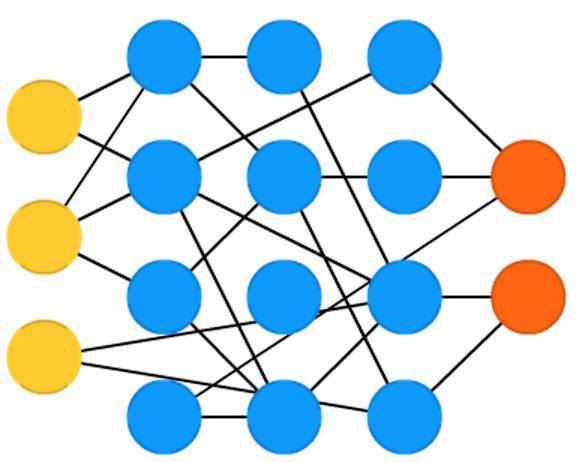
回聲狀態網路(Echo state networks , ESN)是另外一種不同型別的(迴圈)網路。它的不同之處在於:神經元之間隨機地連線(即,層與層之間沒有統一的連線形式),而它們的訓練方式也不一樣。不同於輸入資料,然後反向傳播誤差,回聲狀態網路先輸入資料,前饋,然後暫時更新神經元。它的輸入層和輸出層在這裡扮演了稍微不同於常規的角色:輸入層用來主導網路,輸出層作為隨時間展開的啟用模式的觀測。在訓練過程中,只有觀測和隱藏單元之間連線會被改變。
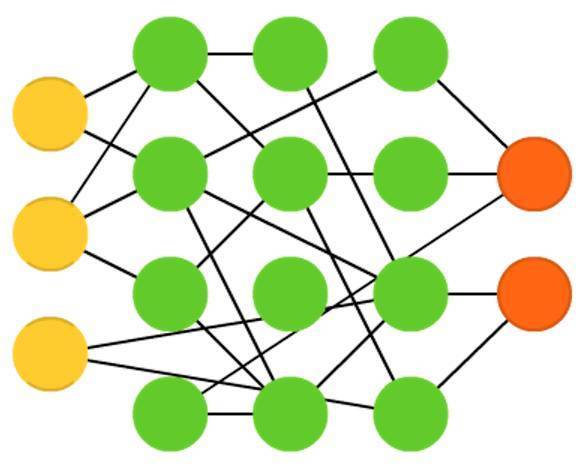
極限學習機(Extreme learning machines , ELM)本質上是有隨機連線的前饋神經網路。他看上去和液體狀態機(LSM)和回聲狀態網路(ESN)很相似,但是它即沒有脈衝,也沒有迴圈。它們並不使用反向傳播。相反,它們隨機初始化權重,並通過最小二乘擬合一步訓練權重(所有函式中的最小誤差)。這使得模型具有稍弱的表現力,但是在速度上比反向傳播快很多。
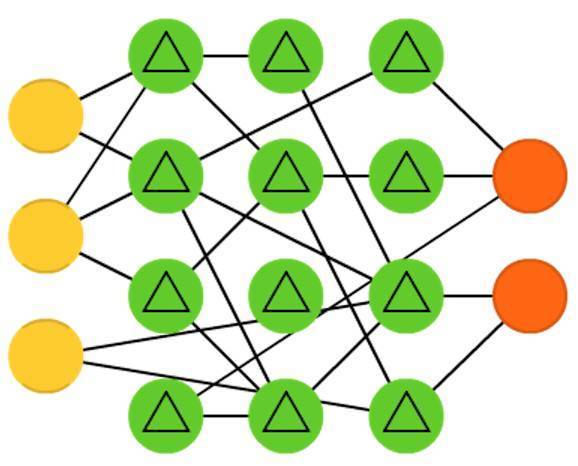
液體狀態機(Liquid state machines ,LSM)看上去和回聲狀態網路(ESN)很像。真正的不同之處在於,液體狀態機是一種脈衝神經網路:sigmoid啟用函式被閾值函式所取代,每個神經元是一個累積記憶單元(memory cell)。所以當更新神經元的時候,其值不是鄰近神經元的累加,而是它自身的累加。一旦達到閾值,它會將其能量傳遞到其他神經元。這就產生一種類似脈衝的模式:在突然達到閾值之前什麼也不會發生。
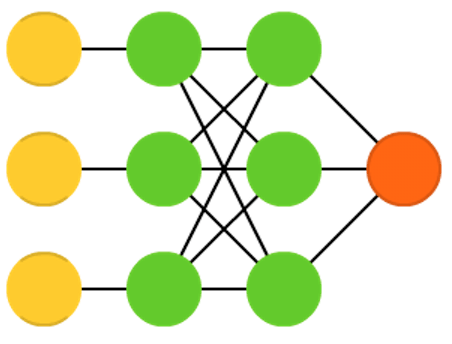
支援向量機(Support vector machines , SVM)發現了分類問題的最佳解決方式。傳統的SVM一般是處理線性可分資料。比如,發現哪張圖片是加菲貓,哪張圖片是史努比,而不可能是其他結果。在訓練過程中,支援向量機可以想象成在(二維)圖上畫出所有的資料點(加菲貓和史努比),然後找出如何畫一條直線將這些資料點區分開來。這條直線將資料分成兩部分,所有加菲貓在直線的一邊,而史努比在另一邊。最佳的分割直線是,兩邊的點和直線之間的間隔最大化。當需要將新的資料分類時,我們將在圖上畫出這個新資料點,然後簡單地看它屬於直線的那一邊。使用核技巧,它們可以被訓練用來分類n維資料。這需要在3D圖上畫出點,然後可以區分史努比、加菲貓和西蒙貓,甚至更多的卡通形象。支援向量機並不總是被視為神經網路。
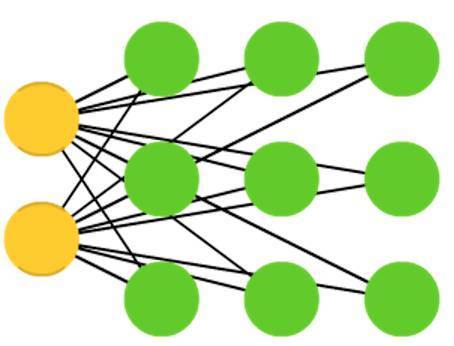
Kohonen網路(Kohonen networks , KN; 也被稱為自組織(特徵)對映, SOM, SOFM))利用競爭性學習對資料進行分類,無需監督。 將資料輸入網路,之後網路評估其中哪個神經元最匹配那個輸入。 然後調整這些神經元以使更好地匹配輸入。在該過程中移動相鄰神經元。 相鄰神經元被移動多少取決於它們到最佳匹配單位的距離。 有時候,Kohonen網路也不被認為是神經網路。