
希爾排序演算法(排序詳解)
希爾排序
基本思想
希爾排序(Shell Sort)是插入排序的一種。也稱縮小增量排序,是直接插入排序演算法的一種更高效的改進版本。希爾排序是非穩定排序演算法。該方法因DL.Shell於1959年提出而得名。希爾排序是記錄按下標的一定增量分組,對每組使用直接插入排序演算法排序;隨著增量逐漸減少,每組包含的關鍵詞越來越多,當增量減至1時,整個檔案恰被分成一組,演算法便終止。
我們分割待排序記錄的目的是減少待排序記錄的個數,並使整個序列向基本有序發展。而如上面這樣分完組後,就各自排序的方法達不到我們的要求。因此,我們需要採取跳躍分割的策略:將相距某個“增量”的記錄組成一個子序列,這樣才能保證在子序列內分別進行直接插入排序後得到的結果是基本有序而不是區域性有序。
操作方法
操作流程圖:
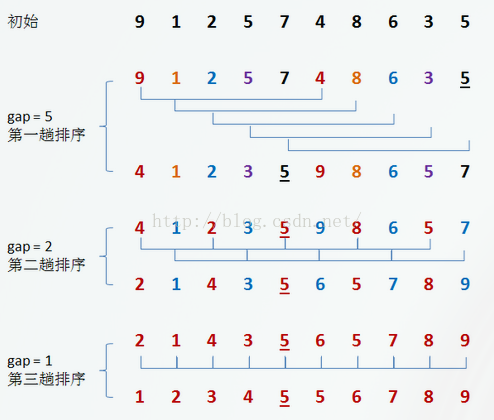
操作步驟:
初始時,有一個大小為 10 的無序序列。
(1)在第一趟排序中,我們不妨設 gap1 = N / 2 = 5,即相隔距離為 5 的元素組成一組,可以分為 5 組。
(2)接下來,按照直接插入排序的方法對每個組進行排序。
在第二趟排序中,我們把上次的 gap 縮小一半,即 gap2 = gap1 / 2 = 2 (取整數)。這樣每相隔距離為 2 的元素組成一組,可以分為 2 組。
(3)按照直接插入排序的方法對每個組進行排序。
(4)在第三趟排序中,再次把 gap 縮小一半,即gap3 = gap2 / 2 = 1。 這樣相隔距離為 1 的元素組成一組,即只有一組。
(5)按照直接插入排序的方法對每個組進行排序。此時,排序已經結束。
演算法實現(Java)
// 希爾排序 public static void shellSort(inta[]) { intd= a.length;//gap的值 while (true){ d = d/ 2;//每次都將gap的值減半 for (int x = 0; x< d; x++) {//對於gap所分的每一個組 for (int i = x+ d; i < a.length; i= i + d) { //進行插入排序 int temp= a[i]; intj; for (j= i - d; j>= 0 && a[j] > temp;j = j - d){ a[j+ d] = a[j]; } a[j+ d] = temp; } } if (d== 1) {//gap==1,跳出迴圈 break; } } }
效率分析
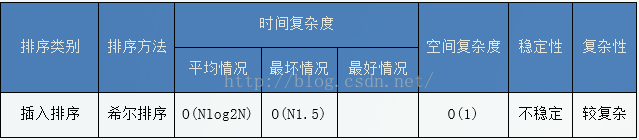
演算法效能:
時間複雜度:
最好情況:由於希爾排序的好壞和步長gap的選擇有很多關係,因此,目前還沒有得出最好的步長如何選擇(現在有些比較好的選擇了,但不確定是否是最好的)。所以,不知道最好的情況下的演算法時間複雜度。
最壞情況下:O(N*logN),最壞的情況下和平均情況下差不多。
已知的最好步長序列是由Sedgewick提出的(1, 5, 19, 41, 109,...)。
這項研究也表明“比較在希爾排序中是最主要的操作,而不是交換。”用這樣步長序列的希爾排序比插入排序和堆排序都要快,甚至在小陣列中比快速排序還快,但是在涉及大量資料時希爾排序還是比快速排序慢。
空間複雜度
由直接插入排序演算法可知,我們在排序過程中,需要一個臨時變數儲存要插入的值,所以空間複雜度為1。
演算法穩定性
希爾排序中相等資料可能會交換位置,所以希爾排序是不穩定的演算法。