
8086指令流水線及其優化
8086處理器的指令流水線
8086 Architecture Overview
8086處理器的架構整體上非常簡單,大致由兩個主要的單元構成:匯流排介面單元BIU和執行單元EU。
匯流排介面單元負責與外部世界通訊,包括指令的讀取,資料的存取以及各種控制訊號的傳輸等,內部包含了程式設計師可見的段暫存器CS,DS,ES,SS和指令指標IP,以及一個6位元組長的指令佇列,該佇列可以看作是一個簡單的指令快取。
執行單元主要負責執行指令,內部包含了8個通用暫存器AX,BX,CX,DX,SP,BP,SI,DI,標誌暫存器Flags,以及算術邏輯單元ALU。

8086 Instruction Pipeline Details
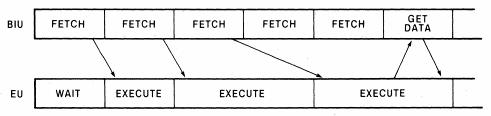
8086處理器有一個超級簡單的指令流水線,只有2級:取指和執行。如下是一個大致的示意圖,BIU負責取指,EU負責指令譯碼,執行和回寫執行結果到相應的IA暫存器堆中(包括通用暫存器和標誌暫存器)或者記憶體中。這兩個單元各自獨立運作,所以可以同時進行取指和指令執行操作。
Optimization Consideration
針對8086流水線沒有什麼需要特別優化的地方。
相關推薦
8086指令流水線及其優化
8086處理器的指令流水線 8086 Architecture Overview 8086處理器的架構整體上非常簡單,大致由兩個主要的單元構成:匯流排介面單元BIU和執行單元EU。 匯流排介面單元負責與外部世界通訊,包括指令的讀取,資料的存取以及各種控制訊號的傳輸等,內部包含了程式設計師
80386指令流水線及其優化
80386 Architecture Overview 80386是Intel的第一代32位x86架構處理器,內部32位的資料通路,外部32位的資料匯流排與地址匯流排,標誌著32位程式設計時代的到來。硬體層面上的特權級指令,多工,32位保護模式,虛擬記憶體管理等機制為32位的多使用者多工作業系統
80286指令流水線及其優化
80286 Architecture Overview 80286處理器的架構相比8086架構略微複雜,除了匯流排介面單元和執行單元以外,新增加的地址單元用於將邏輯地址轉換成實體地址,主要用於支援新增的保護模式,獨立出來的指令單元用於指令的譯碼功能。 從下面的80286內部框圖中我們可
80486指令流水線及其優化
Intel486 Architecture Overview 80486相比80386新增了幾個功能單元,包括快取記憶體單元(即片上的一級快取),邏輯上的兩級譯碼單元,浮點單元也整合到處理器執行核內部。 8K位元組大小的片上一級快取記憶體可以儲存程式碼和資料,快取行大小16位元組,採用
奔騰流水線及其優化
Pentium Architecture Overview Intel在1993年釋出的Pentium是一款先進的超標量處理器。相比起80486,Pentium的功能模組更加複雜: 一級快取記憶體單元從486的合併式變成了Pentium中各自獨立的資料快取記憶體和指令快取記憶體
Pentium Pro流水線及其優化 (3)
Instruction Pipeline 關於Pentium Pro的指令流水線,我從4個來源看到3種不同的說法:11級,12級和14級(沒有13級說,不大吉利吧)。其實大同小異,不用糾結到底是多少級,掌握每級的功能和用途才是學習的重點。分別摘錄如下: 1. Mindshare的Pentiu
Pentium Pro流水線及其優化 (2)
Pentium Pro Instruction Pipeline Details 處於講解指令流水線的需要,接下來我們詳細的講解一下Pentium Pro微架構中的相關單元。上圖是Pentium Pro處理器微架構的功能框圖,從中可以看到一些功能模組和子系統 記憶體子系統 – 系統匯流
Pentium Pro流水線及其優化 (1)
Pentium Pro Architecture Overview Intel在1995年釋出的Pentium Pro是第6代x86架構處理器,基於P6微架構。由於1993年的Pentium使用的超標量架構創造了新的效能標準,Pentium Pro的設計師們面臨著更大的壓力(也是動力):使用與P
SSE影象演算法優化系列二十五:二值影象的Euclidean distance map(EDM)特徵圖計算及其優化。 SSE影象演算法優化系列九:靈活運用SIMD指令16倍提升Sobel邊緣檢測的速度(4000*3000的24點陣圖像時間由480ms降低到30ms)
Euclidean distance map(EDM)這個概念可能聽過的人也很少,其主要是用在二值影象中,作為一個很有效的中間處理手段存在。一般的處理都是將灰度圖處理成二值圖或者一個二值圖處理成另外一個二值圖,而EDM演算法確是由一幅二值圖生成一幅灰度圖。其核心定義如下: The definitio
MySQL的索引及其優化
告訴 出現 緩存 tab 關鍵字 忽略 primary lba lec 前言 索引對查詢的速度有著至關重要的影響,理解索引也是進行數據庫性能調優的起點。考慮如下情況,假設數據庫中一個表有10^6條記錄,DBMS的頁面大小為4K,並存儲100條記錄。如果沒有索引,查詢將對整個
spfa及其優化
name 足夠 其中 truct pat 初始 scrip put () 發現spfa居然也有優化,十分的震驚,現在由我細細道來(#^.^#) Description 給你一個有向且邊權全部非負的圖,輸出1到n的最短路。Input 第一行兩個自然數n(n<
HDU #2191 買米問題 多重背包及其優化
ret -s 初始化 ems 01背包 技術 算法 所有 如何 Description 問題描述以及測試樣例在這:HDU#2191 思路 這道題其實就是多重背包問題,即有 N 種物品和一個容量為 V 的背包,第 i 種物品最多有 n[i] 件可用,每
[總結] 二維ST表及其優化
優化 info http href 線段樹 for efi 技術 sizeof 二維 \(\mathcal{ST}\) 表,可以解決二維 \(\mathcal{RMQ}\) 問題。這裏不能帶修改,如果要修改,就需要二維線段樹解決了。 上一道例題吧 ZOJ2859 類比一維
求100以內素數的5中基本方法及其優化
其他 依然 都是 耗時 基本 for proc rime 數字 求100以內素數的5中基本方法及其優化方法1 基本做法 錯解比較:進入了小循環:有時加pass也可以。錯解:這裏的print也同樣註意不要寫到循環內。 註釋:1.兩種條件運用:為合數。2.以上錯誤點。方法二
7.2 流水線的優化
一道 好的 神奇 連續 流處理 時鐘 http 體系 找到 計算機組成 7 流水線處理器 7.2 流水線的優化 相對於單周期處理器,流水線技術可以提升處理器的性能,但是,如果僅僅按照指令執行的步驟去切分流水線的話,不能夠充分利用流水線這項技術的優勢。那如何才能挖掘流水線技
指令——流水線和吞吐率
執行時間 來源 sdn 版權 tails p s art 運行時 聲明 解析: (1)吞吐率有個公式:指令條數除以流水線時間 (2)流水線時間計算有個公式:一條指令所需時間+(指令條數-1)*時間最長的指令的一段7+(8-1)*3 流水線:流水線是指在程序執行時多條
Javascript的尾遞迴及其優化
在平時的程式碼裡,遞迴是很常見的,然而它可能會帶來的呼叫棧溢位問題有時也令人頭疼:我們知道, js 引擎(包括大部分語言)對於函式呼叫棧的大小是有限制的,如下圖(雖然都是很老的瀏覽器,但還是有參考價值):為了解決遞迴時呼叫棧溢位的問題,除了把遞迴函式改為迭代的形式外,改為尾遞迴的形式也可以解決(雖然目前大部分
瀏覽器核心、引擎、頁面呈現原理及其優化
瀏覽器核心、引擎、頁面呈現原理及其優化 介紹瀏覽器核心、JavaScript 引擎以及頁面呈現原理等基礎知識,同時根據原理提出頁面呈現優化方案。 瀏覽器核心 瀏覽器核心又叫渲染引擎,主要負責 HTML、CSS 的解析,頁面佈局、渲染與複合層合成。瀏覽器核心的不同帶來的主要問題
瀏覽器內核、引擎、頁面呈現原理及其優化
應用 事情 大致 們的 成功 規則 變化 節點 時有 瀏覽器內核、引擎、頁面呈現原理及其優化 介紹瀏覽器內核、JavaScript 引擎以及頁面呈現原理等基礎知識,同時根據原理提出頁面呈現優化方案。 瀏覽器內核 瀏覽器內核又叫渲染引擎,主要負責 HTML、C
菜鷄日記——KMP演算法及其優化與應用
一、什麼是KMP演算法 KMP演算法,全稱Knuth-Morris-Pratt演算法,由三位科學家的名字組合命名,是一種效能高效的字串匹配演算法。假設有主串S與模式串T,KMP演算法可以線上性的時間內匹配出S中的T,甚至還能處理由多個模式串組成的字典的匹配問題。 二、KMP演算法原理及實現