
80486指令流水線及其優化
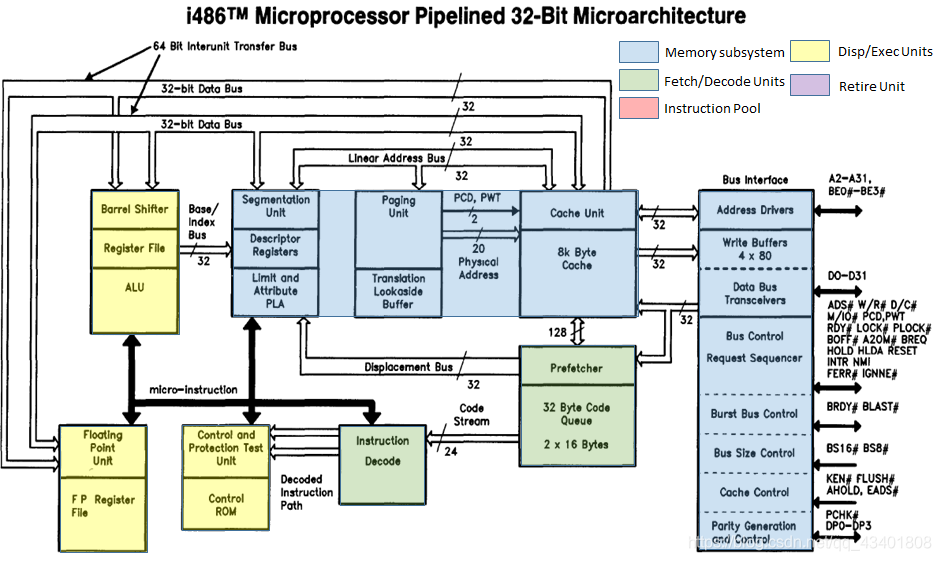
Intel486 Architecture Overview
80486相比80386新增了幾個功能單元,包括快取記憶體單元(即片上的一級快取),邏輯上的兩級譯碼單元,浮點單元也整合到處理器執行核內部。

8K位元組大小的片上一級快取記憶體可以儲存程式碼和資料,快取行大小16位元組,採用4路組相聯結構,偽最近最少使用演算法(pseudo-LRU)快取行替換策略。
8K = 8192 / 4-way / 16 cache line size = 128 (index)

片上的浮點單元藉助整型指令流水線進行資料訪問。從下圖中可以看到兩條32位的內部資料匯流排,在一起協作相當於一條64位的內部單元間的資料匯流排。 在一個時鐘週期內,內部匯流排可以將8位元組的資料從一級快取傳輸到浮點單元。處理器內部浮點計算和整型計算可以併發執行。
Intel486 Instruction Pipeline Details
Intel486™處理器有一條完整的整型指令流水線,理想條件下,峰值處理能力可以達到每個週期執行一條指令。相比80386,486使用了5級流水線:取指,譯碼階段1,譯碼階段2,執行,執行結果回寫。

下面詳細的介紹整型流水線的每一級
5級流水線由以下構成:
- 取指 (PF) – 從一級快取中讀取16位元組指令流(即一個快取行大小),儲存在指令佇列中。這個指令佇列由兩個16位元組的快取構成,共32位元組。取指單元會選擇其中一個快取儲存指令流。
- 第一級譯碼 (D1) – 帶有字首的指令會在D1中停留2個週期
- 第二級譯碼(D2)- 也叫地址生成階段,該階段並行地計算出有效地址和線性地址。
- 執行(E) - 指令的執行階段。對於簡單指令(只需要一次機器計算的指令)可以在1個時鐘週期內完成,這樣可以達到每個週期完成一條指令的吞吐量。複雜的指令必須要消耗多個時鐘週期。
- 回寫(WB) - 回寫階段更新參與運算的暫存器。
注意:執行階段的資料訪問操作比指令預取階段的指令預取操作具有更高的優先順序。換句話,指令預取只有在預取指令佇列有空位,同時執行單元沒有資料訪問請求的時候,才會利用空閒的匯流排週期進行指令預取。
下圖是80486的指令流水線執行示意圖。

注意CPU晶片上有一個特別設計的邏輯電路可以在某些情況下避過回寫階段。例如,如果當前指令在執行階段計算出來的結果會被下一條指令使用的話,則下一條指令不用等待當前指令回寫階段完成就可以直接開始執行。這種情形被稱為回寫旁路writeback bypass。

Optimization Consideration
Addressing operands
對於彙編程式設計師和編譯器開發人員來說,需要注意的是索引定址模式會消耗兩個時鐘週期用於地址計算。其他的定址模式通常可以在一個時鐘週期內完成。
Branching code
同時也要注意分支跳轉(taken branch)會導致2個時鐘週期的效能損失,因為譯碼後的指令(D1和D2階段)會被廢棄(flushed)。是分支指令但沒有發生跳轉則不會影響指令流的執行,因為下一條要執行的指令已經譯碼完畢可以直接進入執行階段。
| 在C語言層面上,如果經常發生exec_2,則應該把exec_2直接寫在if語句下面,即顛倒一下exec_1和exec_2。 If (test_condition) { exec_1; // not-frequently happen } else { exec_2; // frequently happen} |
FPU Instruction Selection
Intel486處理器的執行核被設計為最高效的執行“最常用指令”。因此,精心地選擇指令順序可以獲得更高的執行效能。另外,避免流水線僵死的程式碼也可以提升程式效能。
| Q: 什麼是pipeline stall? A: 根據wikipedia https://en.wikipedia.org/wiki/Pipeline_stall Pipeline stall是為了應對一些可能的危害(hazard), 對下一條要執行的指令進行延遲。 關於hazard,https://en.wikipedia.org/wiki/Hazard_(computer_architecture) |