
Pentium Pro流水線及其優化 (3)
Instruction Pipeline
關於Pentium Pro的指令流水線,我從4個來源看到3種不同的說法:11級,12級和14級(沒有13級說,不大吉利吧)。其實大同小異,不用糾結到底是多少級,掌握每級的功能和用途才是學習的重點。分別摘錄如下:
1. Mindshare的Pentium Pro and Pentium II System Architecture書中說是11級,並且對每一級進行了非常詳細的講解,很值得參考。

2. Wikepedia中說Pentium Pro是14級流水線,但是對每一級未有說明。
| The Pentium Pro incorporated a new
Pentium Pro處理器集成了一套不同於Pentium架構的全新微架構(注:即P6微架構)。該微架構是一套解耦合的14級超流水線架構,同時還引入了微指令池。 |
3. 在Performance Characterization of the Pentium® Pro Processor論文中,提到了Pentium Pro有14級流水線,同時極簡單的說有序前端是8級,亂序執行核是3級,以及終了邏輯是3級。
| The Pentium Pro processor implements a 14-stage pipeline capable of decoding 3 instructions per clock cycle. The in-order front end has 8 stages. The out-of-order core has 3 stages, and the in-order retirement logic has 3 stages. |
4. Pentium Pro的SDM卷2,第2-5頁中說,Pentium Pro的流水線是12級,未有詳細說明。
| To handle this level of instruction throughput, the Pentium Pro processor uses a decoupled, 12-stage superpipeline that supports out-of-order instruction execution. |
P6微架構的指令流水線使用了動態執行機制,揉合了亂序執行和預測式執行(由硬體級別的暫存器重新命名和分支預測提供支援)。 處理器有一個有序的發射流水線,這個流水線將Intel386格式的x86指令分解(即翻譯,或轉換)成相對簡單的微指令,然後這些微指令會被分發給一個超標量亂序執行核執行。處理器的亂序執行核實現了多個流水線,可以同時處理整型,跳轉,浮點和記憶體訪問操作。若干執行單元也可能會整合在單個流水線中實現,例如整型算術邏輯單元ALU和幾個浮點執行單元(加法器,乘法器和除法器)可以共享某單個流水線。通過交錯機制,資料快取記憶體可以實現偽雙埠(pseudo-dual ported)操作,其中一個埠專用於讀取,另一個埠專用於儲存。大多數簡單運算(整型ALU,浮點加法,甚至浮點乘法)可以流水線化,達到每個時鐘週期1至2運算的吞吐量。浮點數除法無法流水線化。高延遲的操作可以和低延遲的操作併發執行。
![]()
In-order Pipeline
有序流水線執行分支預測,指令地址翻譯,指令預取,指令譯碼,以及暫存器重新命名。程式碼生成器(例如編譯器或者彙編程式設計師)對於這幾個階段都要有效能方面的考量。只要BTB分支預測成功,有序流水線的這幾個階段通常都不會影響程式執行效能。當分支預測失敗時,這幾個階段就可能會產生一些延遲,用來獲取將要執行的新指令。
Out-of-order Core
亂序執行團(OOO Cluster)解決資料依賴,分發微指令到對應的執行單元,快取微指令的執行結果知道該指令之前的所有操作都完成,使得處理器的狀態可以按照x86指令的順序正確地得到更新。
Caches
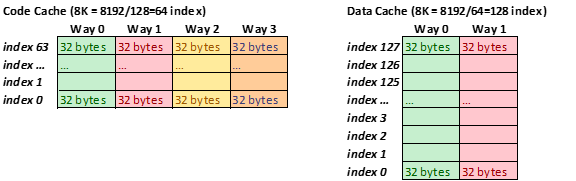
片上的L1 Caches包括了1) 8K位元組,4-way set associative指令cache,和2) 8K位元組,2-way set associative資料cache。Cache Line大小都是32位元組。 L1 Cache miss也未必會招致完全的讀記憶體延遲。L2 cache makes the full latency caused by a L1 cache miss。 L1和L2都miss的最小延遲是14個時鐘週期。
Branch Target Buffer
Pentium Pro處理器使用了一個類似於Pentium的分支預測演算法。通過BTB快取,先前看見過的分支可以動態的被預測。以前未看見過的分支只能使用一個靜態預測演算法來預測。BTB儲存著先前看見過的分支的歷史記錄和對應的目標地址。當遇見一個分支語句時,BTB直接將目標地址交給指令預取單元。一旦分支被執行,BTB將更新成目標地址。
很難確定分支語句消耗的時鐘週期。Pentium Pro有多個級別的分支支援,可以按時鐘週期數來量化:
未跳轉分支(not-taken branch)不會引發效能損失。 未跳轉分支包括以下兩種情形:
- BTB預測不會發生跳轉的分支
- 不在BTB中(預設被預測為不跳轉)的向前分支(forward branch)。
| 注: 由於分支預測失敗,處理器需要獲取正確的跳轉後指令才能繼續執行,因此產生程式的效能損失(penalty)。Intel文件將效能損失分為幾檔
詳細情形見下 |
被BTB正確地預測,且發生跳轉的分支會有1個時鐘週期的效能損失。指令獲取將被掛起1一個時鐘週期。在這1一個週期內,指令譯碼單元沒有指令可以翻譯,因為導致小於4個微指令的分發。這種型別的微效能損失包括先前見過的無條件跳轉分支(即在BTB中)。對於正確預測的跳轉分支,這種小效能損失是1個週期不做指令獲取,再加上跳轉之後沒有微指令發射。這種損失通常會與處理器的其他操作重疊。
預測失敗的分支會引發大效能損失。
分支預測失敗至少導致9個時鐘週期(有序發射流水線的長度)的損失,包括無法獲取指令,加上額外的等待時間,這些時間用於等待the mispredicted branch instruction to become the oldest instruction in the machine and retire。這種效能損失是不可預測的,主要依賴於執行環境,但是實驗表明會有大約10-15週期的損失。
Decoder Shortstop
沒有在BTB中的分支,但是如果被decoder shortstop branch predication機制正確地預測了,會發生小效能損失(大約5-6週期)。這類情形包括以前沒有出現過(沒有在BTB中)的無條件直接分支。譯碼器總是可以正確的預測這種分支。
負偏移的條件分支(conditional branches w/ negative displacement),例如閉迴圈分支(loop-closing branch),會被shortstop機制預測為發生跳轉(taken)。這種分支的第一次跳轉會是小效能損失,隨後的第二次跳轉則是微效能損失,由BTB正確地預測。
不再BTB中但是由譯碼器正確預測的分支導致的小損失大約是5個週期,相比之下,預測失敗的分支或者根本沒有預測的分支會導致10-15個週期的大損失。
Instruction Prefetcher
指令預取單元會激進地按直線順序預取指令。很明顯,如果設計程式碼沒有迴圈分支而是順序執行能充分利用這種優勢。而且,將不常執行的程式碼隔離到過程的底部或者程式的結尾處,這樣也可以避免不必要的預取而提升指令預取的效率。
注意指令預取總是以16位元組對齊。就像Intel486處理器一樣,Pentium Pro對齊在16位元組邊界處預取指令。因此,如果一條分支指令的目標地址(例如彙編程式中某個標籤的地址)等於14 mod 16處,在第一個週期內只會有2個位元組的指令被預取到。
目標地址佈局示例圖。 Target address % 16 = 14,即target address = n * 16 + 14。

要獲得最佳效能,可以把JUMP/CALL/RET指令的目標地址對齊在16位元組處。但是這樣可能會增大程式碼段的長度,而且會花額外的週期數來譯碼NOP指令,處理cache miss等。對於分支跳轉對齊與程式碼長度的折中考慮是很敏感的,只有“重要的分支目標”才需要對齊。有效能剖析和反饋能力的編譯器可以提供分支指令的動態頻率,這樣可以更好的指導目標地址的對齊策略。