
奔騰流水線及其優化
Pentium Architecture Overview
Intel在1993年釋出的Pentium是一款先進的超標量處理器。相比起80486,Pentium的功能模組更加複雜:
- 一級快取記憶體單元從486的合併式變成了Pentium中各自獨立的資料快取記憶體和指令快取記憶體
- 兩條指令流水線,分別被命名為“u”和“v”。這兩條流水線大致功能相同,但是細節上有所區別,由於本文主要集中在效能方面,對流水線u和v詳細的分析參見其他章節。
- 新增了Control ROM和Control Unit(todo:功能待查)
- 流水線化的浮點單元(todo:作用)


Pentium Instruction Pipeline Details
Pentium處理器擁有兩條通用的整型指令流水線,可以同時執行兩條整型指令,以及一個流水線化的浮點單元。對軟體透明的動態分支預測機制可以將由於分支指令導致的流水線僵死降低至最少。
Cache
片上快取記憶體子系統由獨立的一級資料快取記憶體和指令快取構成,分別是8K位元組大小,快取行大小是32位元組,採用2路組相聯結構,回寫更新機制,和最近最少使用快取行替換演算法。外部資料匯流排介面是8位元組寬。

資料快取記憶體由8個bank在4位元組邊界上交錯組成(見下圖)。只要訪問的bank不相同bank,資料快取可以被兩條流水線同時訪問。The minimum delay for a cache miss is 3 clocks.

Integer Pipelines (x2)
Pentium處理器有2條並行的整型流水線,主流水線U是Inte486流水線的增強版,副流水線V與主流水線U類似,但是V可以執行的指令有限制,隨後的章節會詳細解釋。
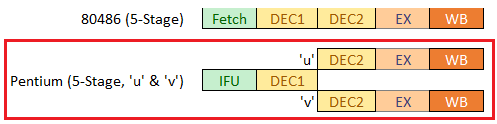
Pentium處理器在每個時鐘週期可以發射2條指令。在這2條指令執行時,後續的2條指令也會被檢查,如果可以同時執行,他們會被髮射到流水線U和V中;如果不能同時執行,則只有下一條指令被髮射到流水線U中,V空閒。
指令在U和V中執行時具有保序性,他們的行為和順序執行一樣。當其中一個流水線僵死的時候,後續指令不允許通過兩條流水線中的任何一個。例如,假設順序指令A、B、C中的A和B分別正在U和V中執行時,如果B指令由於某種原因僵死在V中,即便是A指令已經執行完畢,則隨後的C指令也不允許使用U執行,必須等待B指令在V中執行完畢後,C指令才可以繼續發射執行。
在Pentium處理器的流水線中,譯碼第二階段(D2,即地址生成階段)可以執行多路加法,所以,與486不同,使用索引暫存器定址也不會引發效能損失。
Instruction Prefetcher
指令預取單元有4個快取區,每個區是32位元組大小,共128位元組。指令預取單元可以獲取一條跨快取行的指令且沒有效能損失。由於指令和資料快取記憶體是分開獨立的,所以指令預取再也不會和資料存取衝突了(上一代80486還會有衝突)。
Branch Target Buffer
Pentium採用了動態分支預測機制,分支目標快取區有有一個256個條目(entry,也稱為入口)。如果預測成功,即便發生跳轉,也不會產生效能損失。對於條件分支預測失敗,在流水線U上會有3個時鐘週期的效能損失,在V上是4個時鐘週期。對於call指令或者無條件跳轉指令預測失敗,流水線U和V都是3個週期的效能損失。回憶一下,486沒有分支預測機制,所有的分支跳轉都是2個週期的效能損失。
Pipelined FPU
大多數常用的浮點指令都已經流水線化,因此流水線可以在每一個時鐘週期接收一對新的運算元,於是一個好的程式碼生成器(指彙編程式設計師或者編譯器)可以獲得幾乎每個週期一條指令的吞吐量(當然,這是基於以下的假設:程式具有合理數量的自然並行度)。FXCH指令可以和常用的浮點指令併發執行,由此,程式碼生成器對待浮點棧就好像是使用常規的暫存器組一樣,沒有效能下降。
Optimization Consideration
有了超標量架構,對程式碼生成器非常重要的就是想辦法排程指令流完全充分地利用兩條整型流水線。因為Pentium的整型流水線是由486的流水線增強而來的,所以Pentium指令排程的準則是486(的準則)的超集。