
基於RStudio實現隨機變數的概率分佈
一、二項分佈
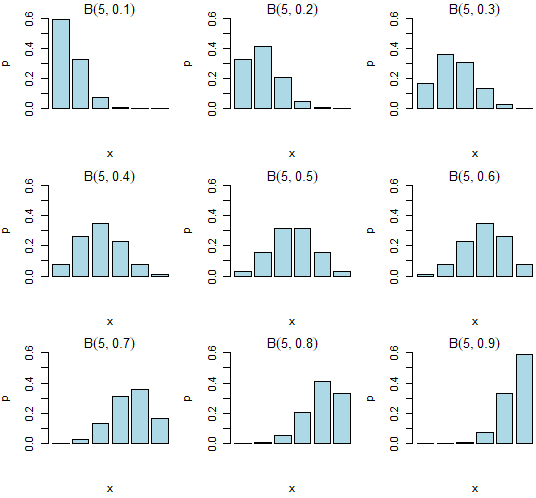
二項分佈Binomial(5,b)圖
> k=seq(0.1,0.9,0.1)
> par(mfrow=c(3,3),mai=c(0.6,0.5,0.2,0.1))
> for (i in 1:9) {
+ barplot(dbinom(0:5,5,k[i]),xlab = "x",ylab = "p",ylim = c(0,.6),main = substitute(B(5,b),list(b=k[i])),col = "lightblue")
+ }
計算二項分佈的概率
# 計算沒有不合格品的概率 > dbinom(0,5,0.06) [1] 0.733904 # 恰好一個不合格品的概率 > dbinom(1,5,0.06) [1] 0.2342247 # 有三個以下不合格品的概率 > pbinom(3,5,0.06) [1] 0.9999383
明天繼續更新。。。
相關推薦
基於RStudio實現隨機變數的概率分佈
一、二項分佈 二項分佈Binomial(5,b)圖 > k=seq(0.1,0.9,0.1) > par(mfrow=c(3,3),mai=c(0.6,0.5,0.2,0.1)) > for (i in 1:9) { + barplot(dbinom(0:5,5,k[i])
隨機變數概率分佈函式彙總-離散型分佈+連續型分佈
2018.08.18-更新 概率分佈用以表達隨機變數取值的概率規律,根據隨機變數所屬型別的不同,概率分佈取不同的表現形式 離散型分佈:二項分佈、多項分佈、伯努利分佈、泊松分佈 連續型分佈:均勻分佈、正態分佈、指數分佈、伽瑪分佈、偏態分佈、貝塔分佈、威布林分佈、卡方分佈、
概率複習 第二章 隨機變數及其分佈
本文用於複習概率論的相關知識點,因為好久不接觸了,忘了不少。這裡撿起來,方便學習其他知識。 總目錄 概率複習 第一章 基本概念 概率複習 第二章 隨機變數及其分佈 本章目錄 隨機變數 離散隨機變數、分佈律 重要離散隨機變數 (0-1)分佈 伯努利試驗 二項分佈
scipy.stats —— 概率、隨機變數與分佈
import numpy as np import scipy.stats as st 機率(odds) p(B)=120p(B)=\frac1{20}p(B)=201:二十場比賽只贏一場 **
基於random實現隨機驗證碼
div print col post -- 驗證碼 隨機驗證碼 code str 1 import random 2 3 i = 0 4 s = ‘‘ 5 while i < 5: 6 7 num = random.randint(0,9)
0基礎統計學學習之路----隨機變數的分佈
隨機變數: 隨機變數分為兩種,第一種是離散型隨機變數,我們可以把離散型隨機變數想象為可數的資料,比如1個氣泡,1個人,5只青蛙,類似這種的屬於離散型隨機變數,非離散型隨機變數也稱為連續性隨機變數,如:一個人的身高是1.72米,一段路長20KM,經過的時間為20分鐘,
基於RStudio 實現資料視覺化之二
1、資料預覽 (資料來源於國家統計局) 2、輪廓圖 > par(mai=c(0.7,0.7,0.1,0.1),cex=0.8) > matplot(t(income[,2:9]),type="b",lty = 1:7,col=1:7,xlab = "消費專案",
關於《損失模型》的一點筆記——第二部分精算模型-1隨機變數與分佈函式
一般的精算模型嘗試表現出未來不確定的支付流,不確定性包括事件是否會發生、發生的時間以及損失量。 一些概念: 1. 現象是指可以觀測到的發生。 2. 試驗是指在一定條件下對某給定現象的一個觀測。 3. 一次試驗的最終觀測稱為結果。 4. 事件是一個或多個
常用隨機變數及其概率分佈
一、常用的離散型隨機變數及其概率分佈 1、(0-1)分佈(伯努利分佈(Bernoulli distribution)、兩點分佈) 如果隨機變數X 只可能取0與1兩個值,其概率分佈為: 或寫成 則稱隨機變數X 服從(0-1)分佈
理論分佈和抽樣分佈------(一)事件、概率和隨機變數(離散、連續)
抽樣分佈:從間斷性變數總體的理論分佈(二項分佈和泊松分佈)和連續性變數總體的理論分佈中抽出的樣本統計數的分佈,即抽樣分佈。 一、事件和事件發生的概率 事件:在自然界中一種事物,常存在幾種可能出現的情況,每一種可能出現的情況稱為事件 事件的概率:每一件事出現的可能性,稱為
常見的離散型和連續型隨機變數的概率分佈
目錄 1 基本概念 4 參考文獻 1 基本概念 在之前的博文中,已經明白了概率分佈函式和概率密度函式。下面來講解一下常見的離散型和連續型隨機變數概率分佈。 在此之前,介紹幾個基本概念: 均值(期望值exp
概率論與數理統計(隨機變數及概率分佈)
隨機變數及概率分佈 一維隨機變數 隨機變數的概念 略 離散型隨機變數 設X為離散型隨機變數,其全部可能值為{a1,a2⋯}則 pi=P(X=ai),i=1,2⋯ 稱為
統計學學習筆記:(三)隨機變數、概率密度、二項分佈、期望值
隨機變數 Random Variable 隨機變數和一般資料上的變數不一樣,通常用大寫字母表示,如X、Y、Z,不是個引數而是function,即函式。例如,下面表示明天是否下雨的隨機變數X,如下。又例如X=每小時經過路口的車輛,隨機變數是個描述,而不是方程中的變數。 隨機變數有兩種,一種是離散的(disc
演算法導論 第五章:概率分析和隨機演算法 筆記(僱傭問題、指示器隨機變數、隨機演算法、概率分析和指示器隨機變數的進一步使用)
僱傭問題: 假設你需要僱用一名新的辦公室助理。你先前的僱傭嘗試都以失敗告終,所以你決定找一個僱用代理。僱用代理每天給你推薦一個應聘者。你會面試這個人,然後決定要不要僱用他。你必須付給僱用代理一小筆費用來面試應聘者。要真正地僱用一個應聘者則要花更多的錢,因為你必須辭掉目前的辦公室助理,還要付一
Keras之DNN:基於Keras(sigmoid+binary_crossentropy+predict_proba)利用DNN實現分類預測概率——DIY二分類資料集&預測新資料點
#Keras之DNN:基於Keras(sigmoid+binary_crossentropy+predict_proba)利用DNN實現分類預測概率——DIY二分類資料集&預測新資料點 輸出結果 實現程式碼 # coding:utf-8 #Ke
基於C#實現的簡單的隨機抽號器
由於老師需要,讓我寫一個隨機抽號器,,就很簡單的寫一個,用C#寫的。主要依靠random來實現一個隨機數以及list可變長陣列實現的。 由於專案難度不大,我就直接放程式碼了。 using System; using System.Collections.Generic; using
如何在Python中實現這五類強大的概率分佈
如何在Python中實現這五類強大的概率分佈 中文譯文原連結,侵刪。 英文出處|How to implement these 5 powerful probability distributions in Python R程式語言已經成為統計分析中的事實標準。但在這篇文
基於特定語料庫生成HMM轉移概率分佈和發射概率分佈用於詞性標註 Python
上篇文章我們以Brown語料庫中的一個特例講解了HMM和Viterbi演算法。 那麼如何使用特定語料庫通過HMM演算法進行詞性標註呢?我們可以從HMM的五元組入手。 大致步驟: 得到語料庫中詞性標註種類和個數==>得到隱序列; 對輸入的句子進行分詞==&
標準正態分佈隨機變數的倒數的分佈
背景 看到有人在問這個問題,拿來算算。 自從有了CSDN-MarkDown之後,寫部落格舒服多了,尤其是數學公式部分。 原理 推薦的參考書是: Schaum’s outline of Probability and Statistics, 3rd
常用概率分佈函式及隨機特徵
常見分佈的隨機特徵離散隨機變數分佈伯努利分佈(二點分佈)伯努利分佈亦稱“零一分佈”、“兩點分佈”。稱隨機變數X有伯努利分佈, 引數為p(0<p<1),如果它分別以概率p和1-p取1和0為值。EX= p,DX=p(1-p)。伯努利試驗成功的次數服從伯努利分佈,引數p