
查詢演算法 | B+樹詳細分析
阿新 • • 發佈:2018-12-25
B+樹是由B樹變來的,B+樹和B樹有這樣的區別:
- B+樹的非葉子節點不記錄資料本身,只記錄引用的連線,並且結點中僅含有其子樹中的最大(或最小)關鍵字。基於此特點,B+樹在非葉子節點的檔案會非常小;
- B+樹的所有的葉子結點中包含了全部關鍵字的資訊;
- B+樹的每個葉子節點都有指向相鄰的下一個兄弟葉子節點的指標且葉子結點本身依關鍵字的大小自小而大順序連結。基於此特點,B+樹在範圍查詢上的效率比B樹高了很多;
- 這條區別是有爭議的,有人說B+樹的節點中關鍵字和子節點個數相同,也有人說B+樹和B樹一樣關鍵字比子節點少一個。
如果我們認為上述第三條中關鍵字和子節點個數是相同的,那B+樹就是這樣的:
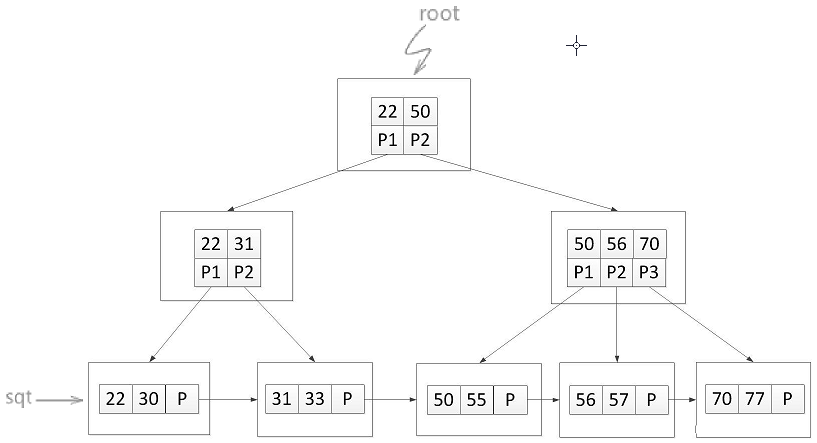
如圖所示,B+樹中含有兩個頭指標,一個指向整棵樹的根結點,另一個指向關鍵字最小的葉子結點。同時所有的葉子結點依據其關鍵字的大小自小而大順序連結,所有的葉子結點構成了一個 sqt 指標為頭指標的連結串列。
所以,B+樹可以進行兩種查詢運算:一種是利用 sqt 連結串列做順序查詢,另一種是從樹的根結點開始,進行類似於二分查詢的查詢方式。
在 B+樹中,所有非葉子節點都相當於是葉子節點的索引,而所有的關鍵字都存放在葉子節點中,所有在從根節點出發做查詢操作時,如果非葉子節點上的關鍵字恰好等於給定值,此時並不算查詢完成,而是要繼續向下直到非葉子節點。
B+樹的查詢操作,無論查詢成功與否,每次查詢操作都是走了一條從根結點到葉子結點的路徑。
向B+樹中新增關鍵字時,也存在節點分裂的情況,在節點分裂時,會生成一個新的節點,把原節點中一半的元素複製到新節點,在父節點中新增指向新節點的關鍵字和指標。