
高效能Mysql:B-TREE和B+-TREE
一、索引簡介
資料庫中,索引對於查詢來說至關重要。它就像書籍裡的目錄一樣,能在磁碟頁面中迅速找到所需要的記錄,能夠將查詢效能提高好幾個數量級。所以索引是應對查詢效能最有效的手段。下面從原理的角度分析mysql的集中索引型別。
二、B-TREE和B+-TREE的特點
首先明確一點,mysql中的索引是儲存引擎實現的,而不是在伺服器層實現的,所以每種儲存引擎的索引實現方式可能不同,支援的索引型別也有可能不同。在各大資料庫實現中,使用最多的就是B-TREE索引或者是B*TREE索引。
三、B-TREE索引
這裡的B並不是binary的意思,而是balance(平衡樹又稱平衡多路查詢樹)的意思。
m階的B-tree特性如下:
- 樹種每個節點最多m個孩子,
- 除根節點和葉子節點外,至少兩個孩子。
- 如果根節點不是葉子節點,則至少兩個孩子。
- 所有葉子節點都出現在同一層,葉子節點不包含任何關鍵字資訊
- 每個非終端結點中包含有n個關鍵字資訊: (n,P0,K1,P1,K2,P2,……,Kn,Pn)。其中:
a) Ki (i=1…n)為關鍵字,且關鍵字按順序排序K(i-1)< Ki。
b) Pi為指向子樹根的接點,且指標P(i-1)指向子樹種所有結點的關鍵字均小於Ki,但都大於K(i-1)。
c) 關鍵字的個數n必須滿足: ceil(m / 2)-1 <= n <= m-1。
B-tree中的每個結點根據實際情況可以包含大量的關鍵字資訊和分支(當然是不能超過磁碟塊的大小,根據磁碟驅動(disk drives)的不同,一般塊的大小在1k~4k左右);這樣樹的深度降低了,這就意味著查詢一個元素只要很少結點從外存磁碟中讀入記憶體,很快訪問到要查詢的資料。
下面以一棵5階B-tree例項進行講解(如下圖所示):(重點看以下圖)
其滿足上述條件:除根結點和葉子結點外,其它每個結點至少有ceil(5/2)=3個孩子(至少2個關鍵字);當然最多5個孩子(最多4個關鍵字)。下圖中關鍵字為大寫字母,順序為字母升序。

插入(insert)操作:插入一個元素時,首先在B-tree中是否存在,如果不存在,即在葉子結點處結束,然後在葉子結點中插入該新的元素,注意:如果葉子結點空間足夠,這裡需要向右移動該葉子結點中大於新插入關鍵字的元素,如果空間滿了以致沒有足夠的空間去新增新的元素,則將該結點進行“分裂”,將一半數量的關鍵字元素分裂到新的其相鄰右結點中,中間關鍵字元素上移到父結點中(當然,如果父結點空間滿了,也同樣需要“分裂”操作),而且當結點中關鍵元素向右移動了,相關的指標也需要向右移。如果在根結點插入新元素,空間滿了,則進行分裂操作,這樣原來的根結點中的中間關鍵字元素向上移動到新的根結點中,因此導致樹的高度增加一層。
咱們通過一個例項來逐步講解下。插入以下字元字母到空的5階B-tree中:C N G A H E K Q M F W L T Z D P R X Y S,5序意味著一個結點最多有5個孩子和4個關鍵字,除根結點外其他結點至少有2個關鍵字,首先,結點空間足夠,4個字母插入相同的結點中,如下圖:

當試著插入H時,結點發現空間不夠,以致將其分裂成2個結點,移動中間元素G上移到新的根結點中,在實現過程中,咱們把A和C留在當前結點中,而H和N放置新的其右鄰居結點中。如下圖:

當插入E,K,Q時,則不需要任何分裂操作:

插入M需要一次分裂,注意M恰好是中間關鍵字元素,以致向上移到父節點中:

插入F,W,L,T不需要任何分裂操作:

插入Z時,最右的葉子結點空間滿了,需要進行分裂操作,中間元素T上移到父節點中,注意通過上移中間元素,樹最終還是保持平衡,分裂結果的結點存在2個關鍵字元素。

插入D時,導致最左邊的葉子結點被分裂,D恰好也是中間元素,上移到父節點中,然後字母P,R,X,Y陸續插入不需要任何分裂操作。
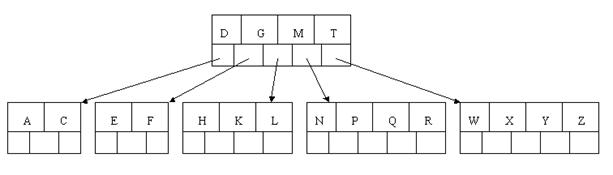
最後,當插入S時,含有N,P,Q,R的結點需要分裂,把中間元素Q上移到父節點中,但是情況來了,父節點中空間已經滿了,所以也要進行分裂,將父節點中的中間元素M上移到新形成的根結點中,注意以前在父節點中的第三個指標在修改後包括D和G節點中。這樣具體插入操作的完成,下面介紹刪除操作,刪除操作相對於插入操作要考慮的情況多點。
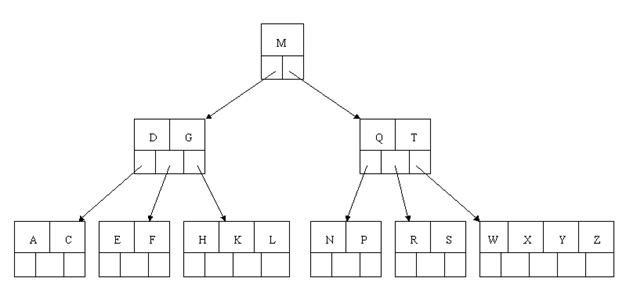
刪除(delete)操作: 首先查詢B-tree中需刪除的元素,如果該元素在B-tree中存在,則將該元素在其結點中進行刪除,如果刪除該元素後,首先判斷該元素是否有左右孩子結點,如果有,則上移孩子結點中的某相近元素到父節點中,然後是移動之後的情況;如果沒有,直接刪除後,移動之後的情況.。
刪除元素,移動相應元素之後,如果某結點中元素數目小於ceil(m/2)-1,則需要看其某相鄰兄弟結點是否豐滿(結點中元素個數大於ceil(m/2)-1),如果豐滿,則向父節點借一個元素來滿足條件;如果其相鄰兄弟都剛脫貧,即借了之後其結點數目小於ceil(m/2)-1,則該結點與其相鄰的某一兄弟結點進行“合併”成一個結點,以此來滿足條件。那咱們通過下面例項來詳細瞭解吧。
以上述插入操作構造的一棵5階B-tree為例,依次刪除H,T,R,E。
首先刪除元素H,當然首先查詢H,H在一個葉子結點中,且該葉子結點元素數目3大於最小元素數目ceil(m/2)-1=2,則操作很簡單,咱們只需要移動K至原來H的位置,移動L至K的位置(也就是結點中刪除元素後面的元素向前移動)

下一步,刪除T,因為T沒有在葉子結點中,而是在中間結點中找到,咱們發現他的繼承者W(字母升序的下個元素),將W上移到T的位置,然後將原包含W的孩子結點中的W進行刪除,這裡恰好刪除W後,該孩子結點中元素個數大於2,無需進行合併操作。
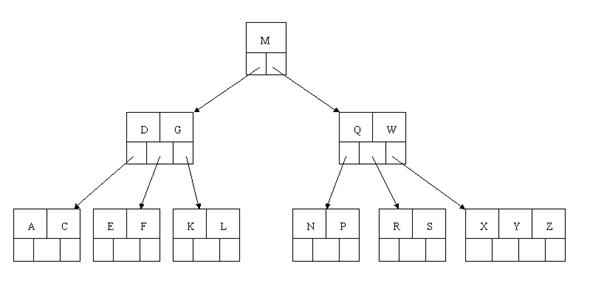
下一步刪除R,R在葉子結點中,但是該結點中元素數目為2,刪除導致只有1個元素,已經小於最小元素數目ceil(5/2)-1=2,如果其某個相鄰兄弟結點中比較豐滿(元素個數大於ceil(5/2)-1=2),則可以向父結點借一個元素,然後將最豐滿的相鄰兄弟結點中上移最後或最前一個元素到父節點中,在這個例項中,右相鄰兄弟結點中比較豐滿(3個元素大於2),所以先向父節點借一個元素W下移到該葉子結點中,代替原來S的位置,S前移;然後X在相鄰右兄弟結點中上移到父結點中,最後在相鄰右兄弟結點中刪除X,後面元素前移。
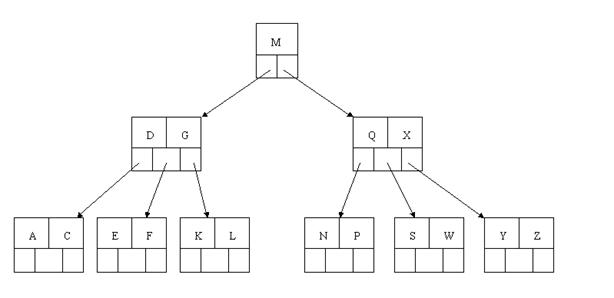
最後一步刪除E,刪除後會導致很多問題,因為E所在的結點數目剛好達標,剛好滿足最小元素個數(ceil(5/2)-1=2),而相鄰的兄弟結點也是同樣的情況,刪除一個元素都不能滿足條件,所以需要該節點與某相鄰兄弟結點進行合併操作;首先移動父結點中的元素(該元素在兩個需要合併的兩個結點元素之間)下移到其子結點中,然後將這兩個結點進行合併成一個結點。所以在該例項中,咱們首先將父節點中的元素D下移到已經刪除E而只有F的結點中,然後將含有D和F的結點和含有A,C的相鄰兄弟結點進行合併成一個結點。
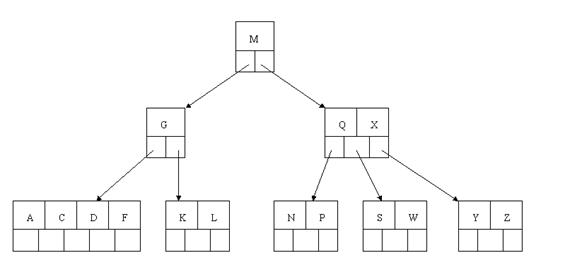
看看上圖,對於這種特殊情況,你立即會發現父節點只包含一個元素G,沒達標,這是不能夠接受的。如果這個問題結點的相鄰兄弟比較豐滿,則可以向父結點借一個元素。假設這時右兄弟結點(含有Q,X)有一個以上的元素(Q右邊還有元素),然後咱們將M下移到元素很少的子結點中,將Q上移到M的位置,這時,Q的左子樹將變成M的右子樹,也就是含有N,P結點被依附在M的右指標上。所以在這個例項中,咱們沒有辦法去借一個元素,只能與兄弟結點進行合併成一個結點,而根結點中的唯一元素M下移到子結點,這樣,樹的高度減少一層。
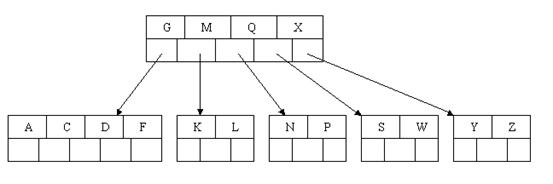
四、B+ -TREE
B-tree索引儲存的是key-data形式,而B+tree儲存的key形式,沒有data
一般資料庫採用的是B+Tree,而且經過了一些優化,比如在葉子節點上增加了順序訪問指標,提高區間查詢效率。比如:查詢首字母為f~t的所有單詞。那麼只需查到f開頭的第一個單詞fabric,然後沿著葉子節點的開始遍歷,直到找到最後一個以t開頭的單詞為止。
B+tree特性:
- 所有關鍵字都出現在葉子結點的連結串列中(稠密索引),且連結串列中的關鍵字恰好是有序的;
- 不可能在非葉子結點命中;(非葉子節點值儲存指向資料的指標,而B-tree中非葉子節點也可以儲存資料)
- 非葉子結點相當於是葉子結點的索引(稀疏索引),葉子結點相當於是儲存(關鍵字)資料的資料層;
- 更適合檔案索引系統;
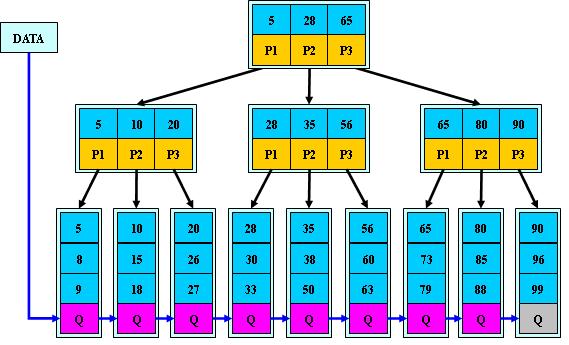
Tips:為什麼更多的都是採用B+-tree,效率高在哪裡?
1.B+-tree內部節點沒有儲存具體data,所以比B-tree小。把同一節點的data放在同一盤塊中,能降低IO讀寫次數。
2.B+-tree查詢效率更加穩定,由於任何關鍵字查詢必須走從根節點到葉子節點,效率會穩定。
3.B+-tree的葉子節點是連結串列有序,在做範圍查詢的時候速度非常快。 例如上圖中如果要查詢key為從18到49的所有資料記錄,當找到18後,只需順著節點和指標順序遍歷就可以一次性訪問到所有資料節點就可以。