
HashMap集合底層實現原理
Java集合:HashMap底層實現和原理(原始碼解析)
Note:文章的內容基於JDK1.7進行分析。1.8做的改動文章末尾進行講解。
一、先來熟悉一下我們常用的HashMap:
1、概述
HashMap基於Map介面實現,元素以鍵值對的方式儲存,並且允許使用null 建和null 值, 因為key不允許重複,因此只能有一個鍵為null,另外HashMap不能保證放入元素的順序,它是無序的,和放入的順序並不能相同。HashMap是執行緒不安全的。
2、繼承關係
public class HashMap<K,V>extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
3、基本屬性
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; //預設初始化大小 16
static final float DEFAULT_LOAD_FACTOR = 0.75f; //負載因子0.75
static final Entry<?,?>[] EMPTY_TABLE = {}; //初始化的預設陣列
transient int size; //HashMap中元素的數量
int threshold; //判斷是否需要調整HashMap的容量 Note:HashMap的擴容操作是一項很耗時的任務,所以如果能估算Map的容量,最好給它一個預設初始值,避免進行多次擴容。HashMap的執行緒是不安全的,多執行緒環境中推薦是ConcurrentHashMap。
二、常被問到的HashMap和Hashtable的區別
1、執行緒安全
兩者最主要的區別在於Hashtable是執行緒安全,而HashMap則非執行緒安全。
Hashtable的實現方法裡面都添加了synchronized關鍵字來確保執行緒同步,因此相對而言HashMap效能會高一些,我們平時使用時若無特殊需求建議使用HashMap,在多執行緒環境下若使用HashMap需要使用Collections.synchronizedMap()方法來獲取一個執行緒安全的集合。
Note:
Collections.synchronizedMap()實現原理是Collections定義了一個SynchronizedMap的內部類,這個類實現了Map介面,在呼叫方法時使用synchronized來保證執行緒同步,當然了實際上操作的還是我們傳入的HashMap例項,簡單的說就是Collections.synchronizedMap()方法幫我們在操作HashMap時自動添加了synchronized來實現執行緒同步,類似的其它Collections.synchronizedXX方法也是類似原理。
2、針對null的不同
HashMap可以使用null作為key,而Hashtable則不允許null作為key
雖說HashMap支援null值作為key,不過建議還是儘量避免這樣使用,因為一旦不小心使用了,若因此引發一些問題,排查起來很是費事。
Note:HashMap以null作為key時,總是儲存在table陣列的第一個節點上。
3、繼承結構
HashMap是對Map介面的實現,HashTable實現了Map介面和Dictionary抽象類。
4、初始容量與擴容
HashMap的初始容量為16,Hashtable初始容量為11,兩者的填充因子預設都是0.75。
HashMap擴容時是當前容量翻倍即:capacity*2,Hashtable擴容時是容量翻倍+1即:capacity*2+1。
5、兩者計算hash的方法不同
Hashtable計算hash是直接使用key的hashcode對table陣列的長度直接進行取模
int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length;
HashMap計算hash對key的hashcode進行了二次hash,以獲得更好的雜湊值,然後對table陣列長度取摸。
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
static int indexFor(int h, int length) {
return h & (length-1);
三、HashMap的資料儲存結構
1、HashMap由陣列和連結串列來實現對資料的儲存
HashMap採用Entry陣列來儲存key-value對,每一個鍵值對組成了一個Entry實體,Entry類實際上是一個單向的連結串列結構,它具有Next指標,可以連線下一個Entry實體,以此來解決Hash衝突的問題。
陣列儲存區間是連續的,佔用記憶體嚴重,故空間複雜的很大。但陣列的二分查詢時間複雜度小,為O(1);陣列的特點是:定址容易,插入和刪除困難;
連結串列儲存區間離散,佔用記憶體比較寬鬆,故空間複雜度很小,但時間複雜度很大,達O(N)。連結串列的特點是:定址困難,插入和刪除容易。

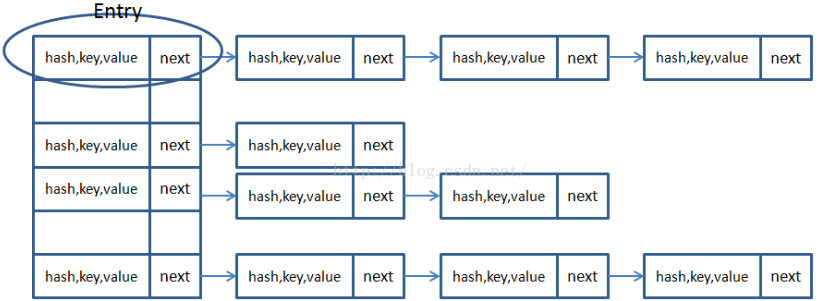
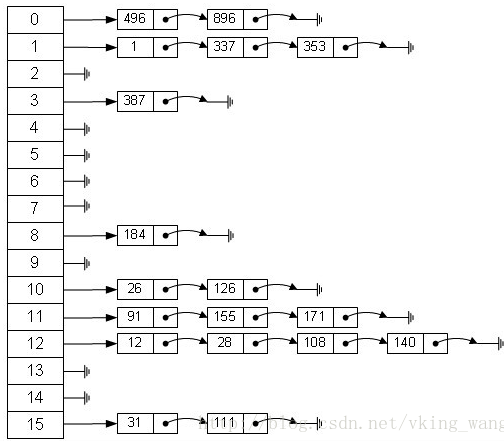
從上圖我們可以發現數據結構由陣列+連結串列組成,一個長度為16的陣列中,每個元素儲存的是一個連結串列的頭結點。那麼這些元素是按照什麼樣的規則儲存到陣列中呢。一般情況是通過hash(key.hashCode())%len獲得,也就是元素的key的雜湊值對陣列長度取模得到。比如上述雜湊表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都儲存在陣列下標為12的位置。
HashMap裡面實現一個靜態內部類Entry,其重要的屬性有 hash,key,value,next。
HashMap裡面用到鏈式資料結構的一個概念。上面我們提到過Entry類裡面有一個next屬性,作用是指向下一個Entry。打個比方, 第一個鍵值對A進來,通過計算其key的hash得到的index=0,記做:Entry[0] = A。一會後又進來一個鍵值對B,通過計算其index也等於0,現在怎麼辦?HashMap會這樣做:B.next = A,Entry[0] = B,如果又進來C,index也等於0,那麼C.next = B,Entry[0] = C;這樣我們發現index=0的地方其實存取了A,B,C三個鍵值對,他們通過next這個屬性連結在一起。所以疑問不用擔心。也就是說陣列中儲存的是最後插入的元素。到這裡為止,HashMap的大致實現,我們應該已經清楚了。
public V put(K key, V value) {
if (key == null)
return putForNullKey(value); //null總是放在陣列的第一個連結串列中
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
//遍歷連結串列
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//如果key在連結串列中已存在,則替換為新value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e); //引數e, 是Entry.next
//如果size超過threshold,則擴充table大小。再雜湊
if (size++ >= threshold)
resize(2 * table.length);
}
四、重要方法深度解析
1、構造方法
HashMap() //無參構造方法 HashMap(int initialCapacity) //指定初始容量的構造方法 HashMap(int initialCapacity, float loadFactor) //指定初始容量和負載因子 HashMap(Map<? extends K,? extends V> m) //指定集合,轉化為HashMap
HashMap提供了四個構造方法,構造方法中 ,依靠第三個方法來執行的,但是前三個方法都沒有進行陣列的初始化操作,即使呼叫了構造方法此時存放HaspMap中陣列元素的table表長度依舊為0 。在第四個構造方法中呼叫了inflateTable()方法完成了table的初始化操作,並將m中的元素新增到HashMap中。
2、新增方法
public V put(K key, V value) {
if (table == EMPTY_TABLE) { //是否初始化
inflateTable(threshold);
}
if (key == null) //放置在0號位置
return putForNullKey(value);
int hash = hash(key); //計算hash值
int i = indexFor(hash, table.length); //計算在Entry[]中的儲存位置
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i); //新增到Map中
return null;
}
在該方法中,新增鍵值對時,首先進行table是否初始化的判斷,如果沒有進行初始化(分配空間,Entry[]陣列的長度)。然後進行key是否為null的判斷,如果key==null ,放置在Entry[]的0號位置。計算在Entry[]陣列的儲存位置,判斷該位置上是否已有元素,如果已經有元素存在,則遍歷該Entry[]陣列位置上的單鏈表。判斷key是否存在,如果key已經存在,則用新的value值,替換點舊的value值,並將舊的value值返回。如果key不存在於HashMap中,程式繼續向下執行。將key-vlaue, 生成Entry實體,新增到HashMap中的Entry[]陣列中。
3、addEntry()
/*
* hash hash值
* key 鍵值
* value value值
* bucketIndex Entry[]陣列中的儲存索引
* /
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length); //擴容操作,將資料元素重新計算位置後放入newTable中,連結串列的順序與之前的順序相反
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
新增到方法的具體操作,在新增之前先進行容量的判斷,如果當前容量達到了閾值,並且需要儲存到Entry[]陣列中,先進性擴容操作,空充的容量為table長度的2倍。重新計算hash值,和陣列儲存的位置,擴容後的連結串列順序與擴容前的連結串列順序相反。然後將新新增的Entry實體存放到當前Entry[]位置連結串列的頭部。在1.8之前,新插入的元素都是放在了連結串列的頭部位置,但是這種操作在高併發的環境下容易導致死鎖,所以1.8之後,新插入的元素都放在了連結串列的尾部。
4、獲取方法:get
public V get(Object key) {
if (key == null)
//返回table[0] 的value值
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
在get方法中,首先計算hash值,然後呼叫indexFor()方法得到該key在table中的儲存位置,得到該位置的單鏈表,遍歷列表找到key和指定key內容相等的Entry,返回entry.value值。
5、刪除方法
public V remove(Object key) {
Entry<K,V> e = removeEntryForKey(key);
return (e == null ? null : e.value);
}
final Entry<K,V> removeEntryForKey(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);
Entry<K,V> prev = table[i];
Entry<K,V> e = prev;
while (e != null) {
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
modCount++;
size--;
if (prev == e)
table[i] = next;
else
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}
刪除操作,先計算指定key的hash值,然後計算出table中的儲存位置,判斷當前位置是否Entry實體存在,如果沒有直接返回,若當前位置有Entry實體存在,則開始遍歷列表。定義了三個Entry引用,分別為pre, e ,next。 在迴圈遍歷的過程中,首先判斷pre 和 e 是否相等,若相等表明,table的當前位置只有一個元素,直接將table[i] = next = null 。若形成了pre -> e -> next 的連線關係,判斷e的key是否和指定的key 相等,若相等則讓pre -> next ,e 失去引用。
6、containsKey
public boolean containsKey(Object key) {
return getEntry(key) != null;
}
final Entry<K,V> getEntry(Object key) {
int hash = (key == null) ? 0 : hash(key.hashCode());
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
containsKey方法是先計算hash然後使用hash和table.length取摸得到index值,遍歷table[index]元素查詢是否包含key相同的值。
7、containsValue
public boolean containsValue(Object value) {
if (value == null)
return containsNullValue();
Entry[] tab = table;
for (int i = 0; i < tab.length ; i++)
for (Entry e = tab[i] ; e != null ; e = e.next)
if (value.equals(e.value))
return true;
return false;
}
containsValue方法就比較粗暴了,就是直接遍歷所有元素直到找到value,由此可見HashMap的containsValue方法本質上和普通陣列和list的contains方法沒什麼區別,你別指望它會像containsKey那麼高效。
五、JDK 1.8的 改變
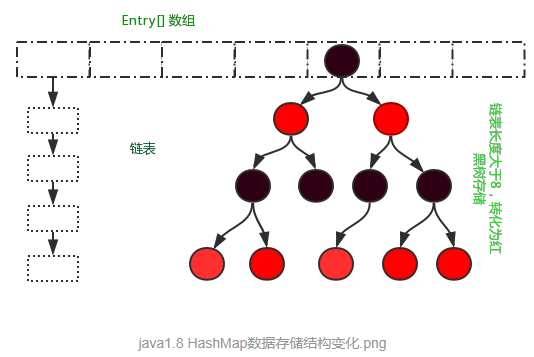
1、HashMap採用陣列+連結串列+紅黑樹實現。
在Jdk1.8中HashMap的實現方式做了一些改變,但是基本思想還是沒有變得,只是在一些地方做了優化,下面來看一下這些改變的地方,資料結構的儲存由陣列+連結串列的方式,變化為陣列+連結串列+紅黑樹的儲存方式,當連結串列長度超過閾值(8)時,將連結串列轉換為紅黑樹。在效能上進一步得到提升。
2、put方法簡單解析:
public V put(K key, V value) {
//呼叫putVal()方法完成
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//判斷table是否初始化,否則初始化操作
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//計算儲存的索引位置,如果沒有元素,直接賦值
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
//節點若已經存在,執行賦值操作
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//判斷連結串列是否是紅黑樹
else if (p instanceof TreeNode)
//紅黑樹物件操作
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//為連結串列,
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//連結串列長度8,將連結串列轉化為紅黑樹儲存
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//key存在,直接覆蓋
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
//記錄修改次數
++modCount;
//判斷是否需要擴容
if (++size > threshold)
resize();
//空操作
afterNodeInsertion(evict);
return null;
}