
From Scratch: AI Balancing Act in 50 Lines of Python
RL Crash Course
If this is your first time in machine learning or reinforcement learning, I’ll cover some basics here so you’ll have grounding on the terms we’ll be using here :). If this isn’t your first time, you can go on and hop down to developing our policy!
Reinforcement Learning
Reinforcement learning (RL) is the field of study delving in teaching agents (our algorithm/machine) to perform certain tasks/actions without explicitly telling it how to do so. Think of it as a baby, moving it’s legs in a random fashion; by luck if the baby stands upright, we hand it a candy/reward. Similarly the agent’s goal will be to maximise the total reward over its lifetime, and we will decide the rewards which align with the tasks we want to accomplish. For the standing up example, a reward of 1 when standing upright and 0 otherwise.
An example of an RL agent would be AlphaGo, where the agent has learned how to play the game of Go to maximize its reward (winning games). In this tutorial, we’ll be creating an agent that can solve the problem of balancing a pole on a cart, by pushing the cart left or right.
State


A state is what the game looks like at the moment. We typically deal with numerical representation of games. In the game of pong, it might be the vertical position of each paddle and the x, y coordinate of the ball. In the case of cart pole, our state is composed of 4 numbers: the position of the cart, the speed of the cart, the position of the pole (as an angle) and the angular velocity of the pole. These 4 numbers are given to us as an array (or vector). This is important; understanding the state is an array of numbers means we can do some mathematical operations on it to decide what action we want to take according to the state.
Policy
A policy is a function that can take the state of the game (ex. position of board pieces, or where the cart and pole are) and output the action the agent should take in the position (ex. move the knight, or push the cart to the left). After the agent takes the action we chose, the game will update with the next state, which we’ll feed into the policy again to make a decision. This continues on until the game ends in some way. The policy is very important and is what we’re looking for, as it is the decision making ability behind an agent.
Dot Products
A dot product between two arrays (vectors) is simply multiplying each element of the first array by the corresponding element of the second array, and summing all of it together. Say we wanted to find the dot product of array A and B, it’ll simply be A[0]*B[0] + A[1]*B[1]… We’ll be using this operation to multiply the state (which is an array) by another array (which will be our policy). We’ll see this in action in the next section.
Developing our Policy
To solve our game of cart pole, we’ll want to let our machine learn a strategy or a policy to win the game or maximize our rewards.
For the agent we’ll develop today, we’ll be representing our policy as an array of 4 numbers that represent how “important” each component of the state is (the cart position, pole position, etc.) and then we’ll dot product the policy array with the state to output a single number. Depending on if the number is positive or negative, we’ll push the cart left or right.
If this sounds a bit abstract, let’s pick a concrete example and see what will happen.
Let’s say the cart is centered in the game and stationary, and the pole is tilted to the right and is also falling towards the right. It’ll look something like this:


And the associated state might look like this:

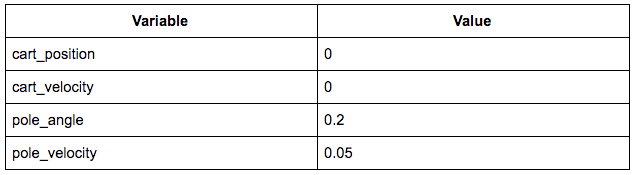
The state array would then be [0, 0, 0.2, 0.05].
Now intuitively, we’ll want to straighten the pole back up by pushing the cart to the right. I’ve taken a good policy from one of my training runs and its policy array reads: [-0.116, 0.332, 0.207 0.352]. Let’s do the math real quick by hand and see what this policy will output as an action for this state.
Here we’ll dot product the state array [0, 0, 0.2, 0.05] and the policy array (pasted above). If the number is positive, we push the cart to the right, if the number is negative, we push left.


The result is positive, which means the policy also would’ve pushed the cart to the right in this situation, exactly how we’d want it to behave.
Now this is all fine and dandy, and clearly all we need are 4 magic numbers like the one above to help solve this problem. Now, how do we get those numbers? What if we just totally picked them at random? How well would it work? Let’s find out and start digging into the code!
Start Your Editor!
Let’s pop open a Python instance on repl.it. Repl.it allows you to quickly bring up cloud instances of a ton of different programming environments, and edit code within a powerful cloud IDE that is accessible anywhere!


Install the Packages
We’ll start off by installing the two packages we need for this project: numpy to help with numerical calculations, and OpenAI Gym to serve as our simulator for our agent.
Simply type gym and numpy into the package search tool on the left hand side of the editor and click the plus button to install the packages.
Laying Down the Foundations
Let’s first import the two dependencies we just installed into our main.py script and set up a new gym environment:
Next we’ll define a function called “play”, that will be given an environment and a policy array, and will play the policy array in the environment and return the score, and a snapshot (observation) of the game at each timestep. We’ll use the score to tell us how well the policy played and the snapshots for us to watch how the policy did in a single game. This way we can test different policies and see how well they do in the game!
Let’s start off with the function definition, and resetting the game to a starting state.
Next we’ll initialize some variables to keep track if the game is over yet, the total score of the policy, and the snapshots (observations) of each step during the game.
Now we’ll simply just play the game for a lot of time steps, until the gym tells us the game is done.
The bulk of the code above is mainly just in playing the game and recording the outcome. The actual code that is our policy is simply these two lines:
All we’re doing here is the dot product operation between the policy array and the state (observation) array like we’ve shown in the concrete example earlier. Then we either choose an action of 1 or 0 (left or right) depending if the outcome is positive or negative.
So far our main.py should look like this:
Now we’ll want to start playing some games and find our optimal policy!
Playing the First Game
Now that we have a function to play the game and tell how good our policy is, we’ll want to start generating some policies and see how well they do.
What if we just tried to plug in some random policies at first? How far can we go? Let’s use numpy to generate our policy, which is a 4 element array or a 4x1 matrix. It’ll pick 4 numbers between 0 and 1 to use as our policy.
With that policy in place, and the environment we created above, we can plug them into play and get a score.
Simply hit run to run our script. It should output the score our policy got.
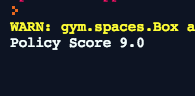
The max score for this game is 500, chances are is that your policy didn’t fare so well. If yours did, congrats! It must be your lucky day! Just seeing a number though isn’t very rewarding, it’d be great if we could visualize how our agent plays the game, and in the next step we’ll be setting that up!
Watching our Agent
To watch our agent, we’ll use Flask to set up a lightweight server so we can see our agent’s performance in our browser. Flask is a light Python HTTP server framework that can serve our HTML UI and data. I’ll keep this part brief as the details behind rendering and HTTP servers isn’t critical to training our agent.
We’ll first want to install Flask as a Python package, just like how we installed gym and numpy in the previous sections.
Next, at the bottom of our script, we’ll create a flask server. It’ll expose the recording of each frame of the game on the /data endpoint and host the UI on /.
Additionally we’ll need to add two files. One will be a blank Python file to the project. This is a technicality of how repl.it detects if the repl is either in eval mode or project mode. Simply use the new file button to add a blank Python script.
After that we also want to create an index.html that will host the rendering UI. I won’t dive into details here, but simply upload this index.html to your repl.it project.
You now should have a project directory that looks like this:

Now with these two new files, when we run the repl, it should now also play back how our policy did. With this in place, let’s try to find an optimal policy!


Policy Search
In our first pass, we simply randomly picked one policy, but what if we picked a handful of policies, and only kept the one that did the best?
Let’s go back to the part where we play the policy, and instead of just generating one, let’s write a loop to generate a few and keep track of how well each policy did, and save only the best policy.
We’ll first create a tuple called max that will store the score, observations, and policy array of the best policy we’ve seen so far.
Next we’ll generate and evaluate 10 policies, and save the best policy in max.
We’ll also have to tell our /data endpoint to return the replay of the best policy.
This endpoint:
should be changed to:
Your main.py should look something like this now:
If we run the repl now, we should get a max score of 500, if not, try running the repl one more time! We can also watch the policy balance the pole perfectly fine! Wow that was easy!
Not So Fast
Or maybe it isn’t. We cheated a bit in the first part in a couple of ways. First of all we only randomly created policy arrays between the range of 0 to 1. This just happens to work, but if we flipped the greater than operator around, we’ll see that the agent will fail pretty catastrophically. To try it yourself change action = 1 if outcome > 0 else 0 to action = 1 if outcome < 0 else 0.
This doesn’t seem very robust, in that if we just happened to pick less than instead of greater than, we could never find a policy that could solve the game. To alleviate this, we actually should generate policies with negative numbers as well. This will make it more difficult to find a good policy (as a lot of the negative ones aren’t good), but we’re no longer “cheating” by fitting our specific algorithm to this specific game. If we tried to do this on other environments in the OpenAI gym, our algorithm would definitely fail.
To do this instead of having policy = np.random.rand(1,4), we’ll change to policy = np.random.rand(1,4) - 0.5. This way each number in our policy will be between -0.5 and 0.5 instead of 0 to 1. But because this is more difficult, we’d also want to search through more policies. In the for loop above, instead of iterating through 10 policies, let’s try 100 policies by changing the code to read for _ in range(100):. I also encourage you to try to just iterate through 10 policies first, to see how hard it is to get good policies now with negative numbers.
Now our main.py should look like this:
If you run the repl now, no matter if we’re using greater than or less than, we can still find a good policy for the game.
Not So Fast Pt. 2
But wait, there’s more! Even though our policy might be able to achieve the max score of 500 on a single run, can it do it every time? When we’ve generated 100 policies, and pick the policy that did best on its single run, the policy might’ve just gotten very lucky, and in it could be a very bad policy that just happened to have a very good run. This is because the game itself has an element of randomness to it (the starting position is different every time), so a policy could be good at just one starting position, but not others.
So to fix this, we’d want to evaluate how well a policy did on multiple trials. For now, let’s take the best policy we found from before, and see how well it’ll do on 100 trials.
Here we’re playing the best policy (index 2 of max) 100 times, and recording the score each time. We then use numpy to calculate the average score and print it to our terminal. There’s no hard published definition of “solved”, but it should be only a few points shy of 500. You might notice that the best policy might actually be subpar sometimes. However, I’ll leave the fix up to you to decide!