
ToneNet : A Musical Style Transfer
ToneNet : A Musical Style Transfer
By: Team Vesta, University of Southern California.
CSCI:599 Deep Learning and Its Applications
Suraj Jayakumar ([email protected]), Rakesh Ramesh ([email protected]), Pradeep Thalasta ([email protected])
Introduction:
The recent success of Generative Adversarial Networks (GANs) in vision domain such as style transfer inspired us to experiment with these techniques in musical domain. Music generation mainly delves on two most important things: composition and performance. Composition focuses on building blocks of the song like the notations, tone, pitch and chords. And performance which focuses on how the notes are played by the performer. This uniqueness defines the style of music.
Dataset and Pre-Processing:
We have about 200 piano-only songs (MIDI files) classified as Jazz and Classical with average length of training data about 4 minutes.
Firstly, we quantize each MIDI file to align to the particular time interval thereby eliminating imprecisions of the performer. Secondly, we encode the input MIDI file into a T ×P matrix where T is the number of time steps in the song and P is the number of pitches in the instrument (Example, for piano with 88 keys we have 88 pitches). Further, in each value of the matrix we encode the information regarding note using a 2-D vector i.e., [1 1] note articulated, [0 1] note sustained and [0 0] note off.
Similarly, we generate an output matrix of the shape T ×P but here we encode velocities of the song i.e., the volume (scaled 1–127) of the next key that is played rather than the note information.
Dataset Link : Piano Dataset [Note: The Piano Dataset is distributed with a CC-BY 4.0 license. If you use this dataset, please reference this
Architectural Design
Sequence-to-Sequence
Sequence-to-sequence models are proven to work very well in past over various domain for style transfer especially in language (Machine Translation)
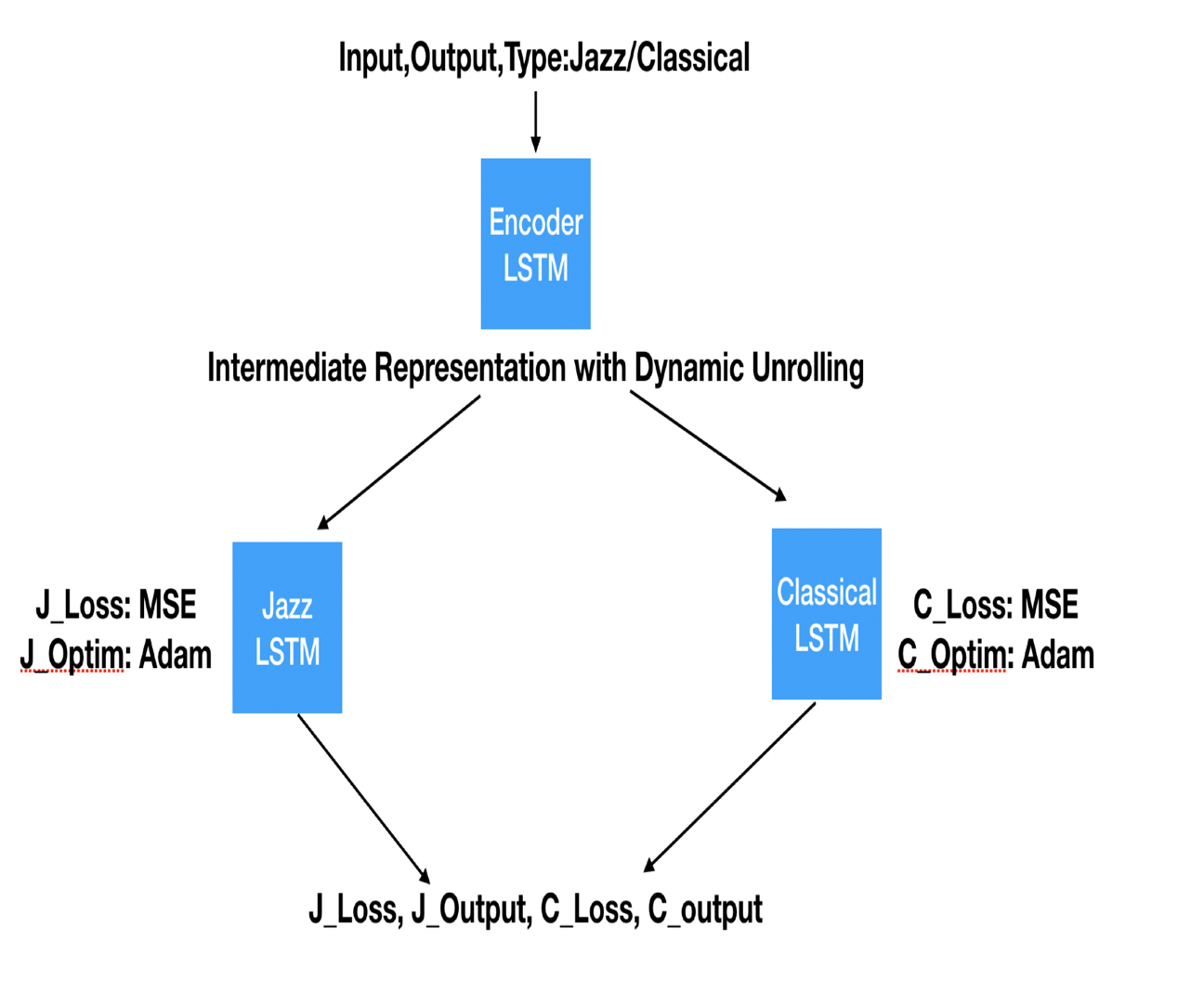
Baseline — seq2seq
Note: The baseline architecture is substantially borrowed from this paper. Please reference the same. Also check out StyleNet by Iman Malik for more information regarding the baseline musical style transfer
The pre-processed MIDI file of the song is passed on to an Encoder LSTM with dynamic RNN unrolling to handle different time steps in different songs and to keep consistency. The intermediate output from the encoder is passed on to the LSTM corresponding to its style which learns the internal dynamics of music genre.
The input song is fed-on to opposite genre LSTM. During style transfer the output is decoded back into a MIDI file which would represent the style-transferred MIDI file.
Attention based seq2seq
This architecture is further tweaked to make use of Attention Mechanism so that we can we can weigh in portions of the song which we want the network to pay more importance to, especially the mid-riffs.
The outputs from the encoder LSTM is passed on through Attention Mechanism (Luong’s Version). The output from this wrapper is passed on to the decoder cell.
The attention computation happens at every decoder time step where in we compute attention weights that is associated with each context vector which is used to calculate the attention vector which then is finally used to calculate the score.
Working and Post-Processing
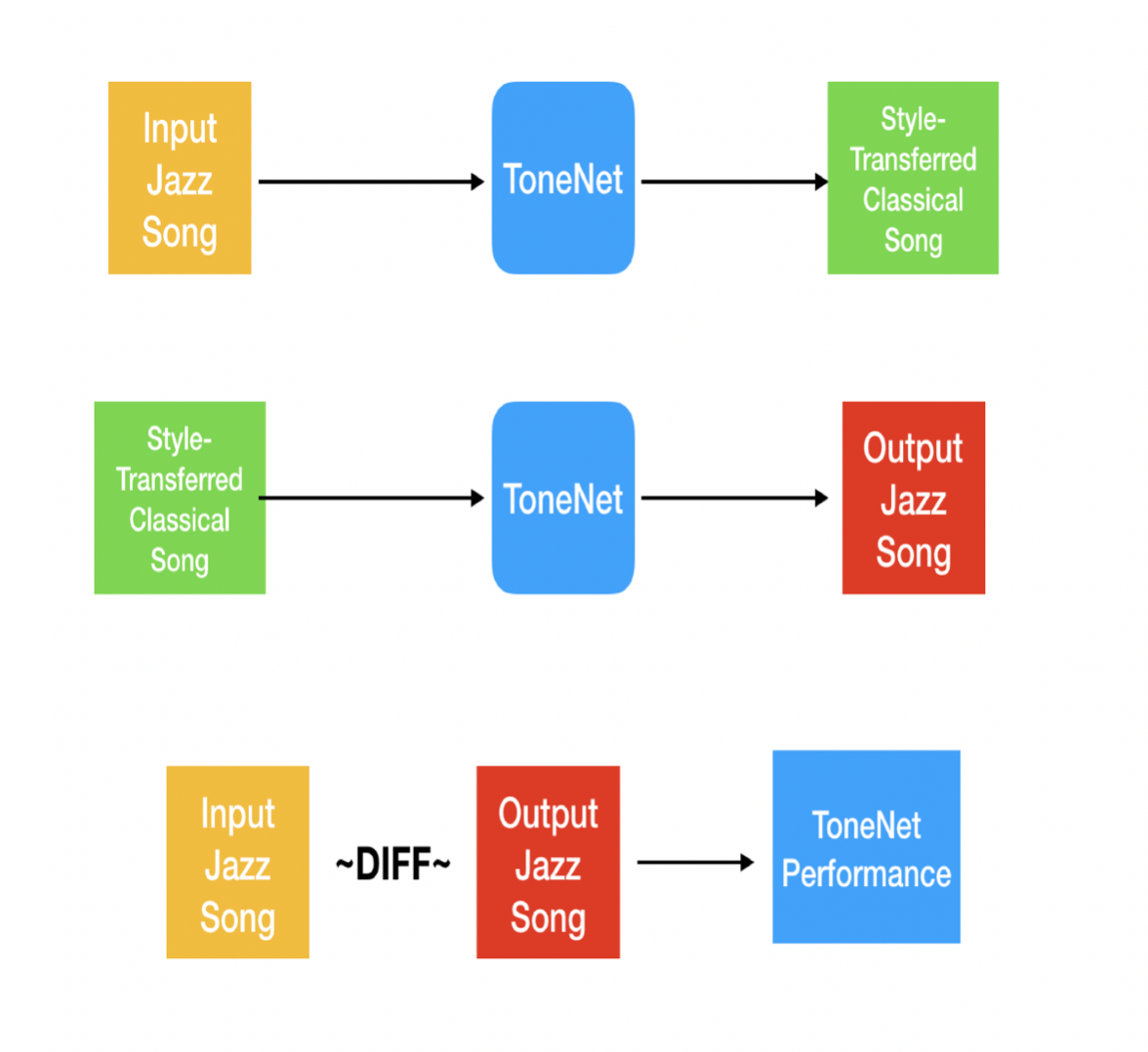
The song (say jazz song) that is to be style transferred is passed through the encoder to the opposite genre (classical) and we collect the output (classical output) and use this information to super impose on the original song but with the classical velocities that are generated by the ToneNet.
Model Evaluation
To evaluate the overall performance of the ToneNet we pass an input sample jazz song onto ToneNet and get the style-transferred classical song. This output is looped back into the network and we try to re-generate the input song back into jazz genre and compare with the original song. This numerical MSE comparison between original and regenerated song would determine the performance of ToneNet.
VAE-GAN
Architecture:
The Architecture being proposed is that of VAE-GAN (Variational Auto-encoder Generative Adversarial Network). By combining a variational auto-encoder with a generative adversarial network we can use learned feature representations in the GAN discriminator as basis for the VAE reconstruction objective. This makes the training process significantly more stable as Generator has information regarding the real-world entities it is trying to generate rather than guessing what the real-world entity should be at each iteration. In addition, the Encoder learns the mapping of images to Latent space which is very useful.

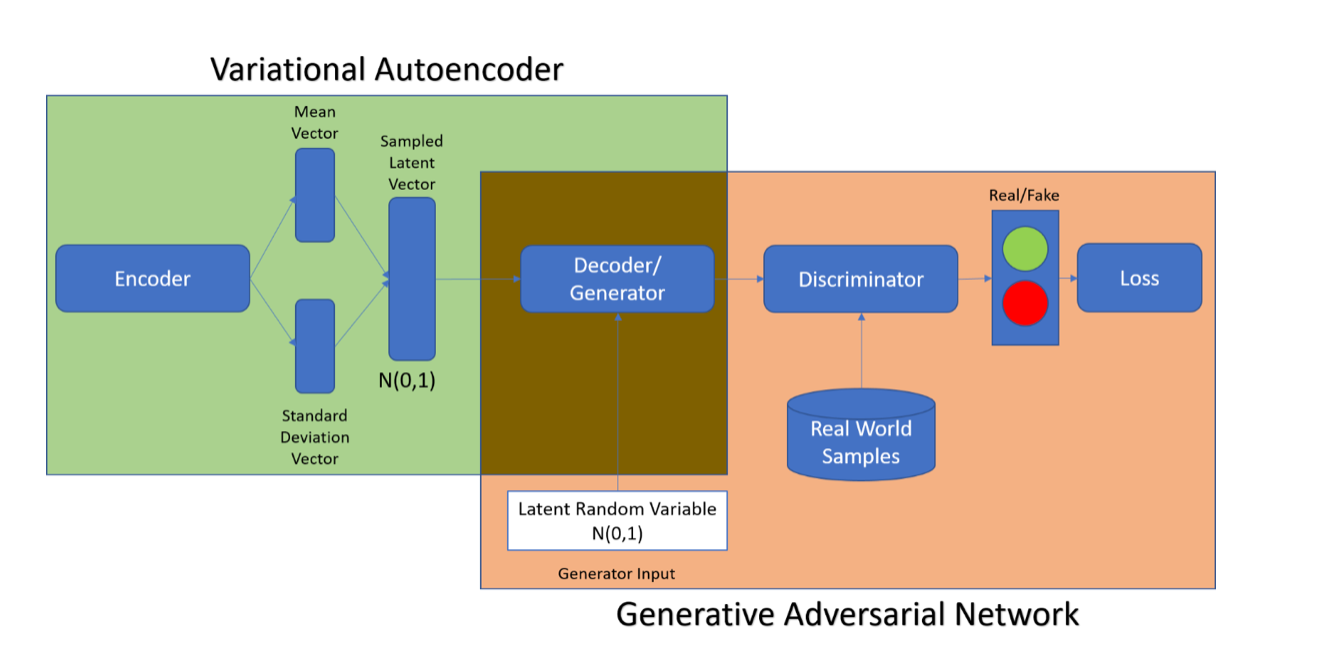
Variational Auto-encoder
VAE consists of two networks that encode a data sample x to a latent representation z and decode the latent representation back to the data sample.
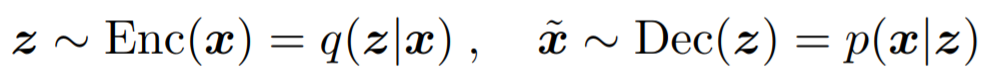
VAE Loss is minus the sum of expected log likelihood (Reconstruction Error) and a prior regularization term
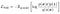
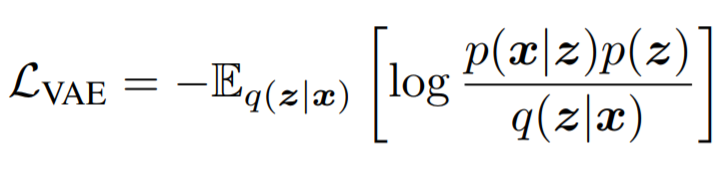
Generative Adversarial Network
A GAN consists of two networks: the generator network Gen(z) maps latents z to data space while the discriminator network assigns probability y = Dis(x) ∈ [0, 1] that x is an actual training sample and probability 1 − y that x is generated by our model through x = Gen(z) with z ∼ p(z).
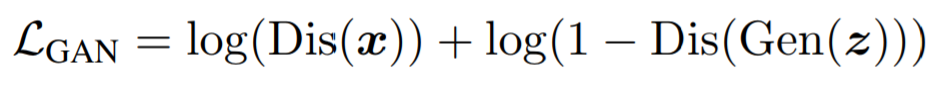
In our design, we are representing the midi file (Piano track) in terms of multiple 88(number of time steps) X 88 (number of notes) images where each pixel value is the corresponding volume of a given note for a timestep.

Why VAE-GAN?
This was implemented as an offshoot of the problem statement wherein we wanted to create covers corresponding to different genres. This required us to have the ability to generate complete songs from scratch. Further extension of this would be implementing a Cycle GAN wherein this architecture can be used as the building block leading to music style transfer. Simple GAN is unstable to train and we lose out on the mapping between the latent space and the generated song. Hence, we use VAE-GAN architecture. Midi files are converted to images so that it would be easier to deal with as convolutional neural network based GAN’s are significantly more stable and easier to train.
Post Processing
Here, the output contains 88X88 images which correspond to quantized timesteps, notes and volumes of the generated music. We need to convert the images to corresponding song representation. We are building a new midi file with the quantization interval same as what we had set during preprocessing and notes and volumes corresponding to the information obtained from the generated image.
Results

VAE-Reconstruction

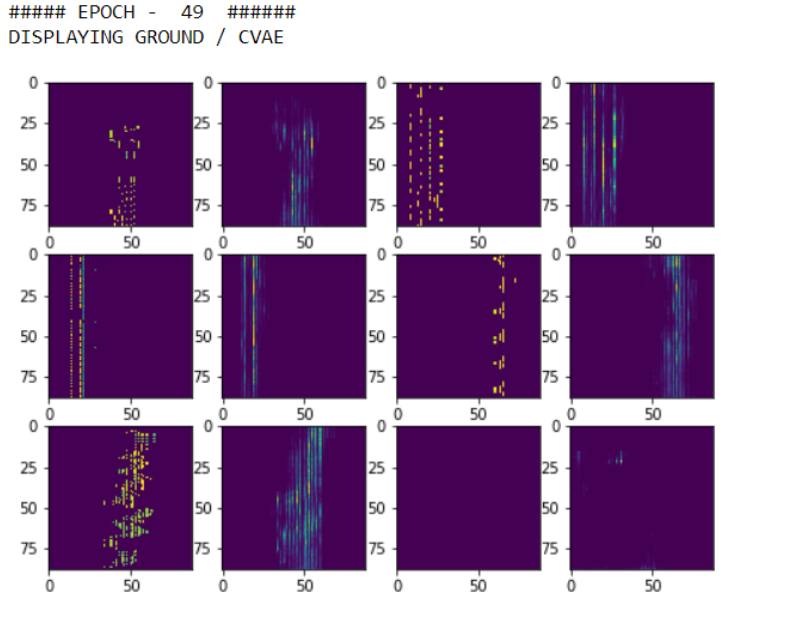
Generation using Noise

Thoughts
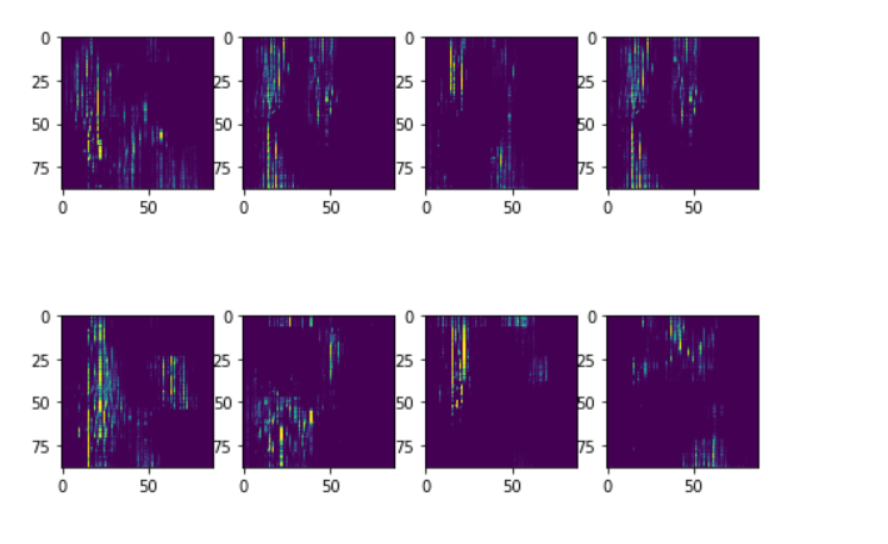
Why Architecture Didn’t work:- We believe the reason it didn’t work well is because of the simple assumption we made with regard to expressing the song in terms of just timesteps, notes and volume. There are other key components missing such as the note start and end time. Because of quantization, every note is represented as a separate stroke in the input. This introduces harshness into the generated music. From the results it is evident that the model is learning how to recreate the input in a relatively good manner and the generated music is pretty similar in structure to the input song representation. For instance, majority of the notes are set to 0 volume and an average of 2–3 notes are active at a time which is indicative of normal piano music. Notes close to one another are often played together, repeated pattern information is captured. This indicates that the model is performing well and that fault here lies with the world assumption rather than the Architecture used for accomplishing this task.
Findings
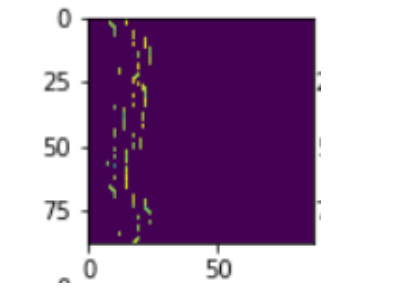
VAE-GAN is significantly more stable than GAN. Many of our simple GAN implementations resulted in generator converging to patterns such as this

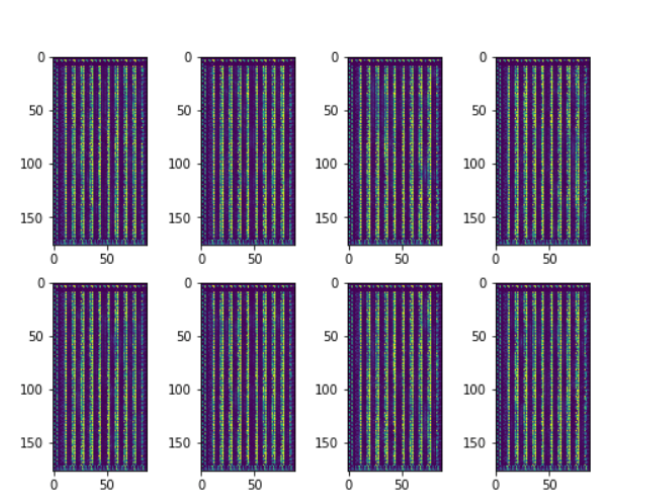
Generator would not improve regardless of how many epochs we train after this point. Such a scenario never occurred when using VAE-GAN.
Dynamically adjusting Learning Rate helped immensely when training the model. Here is the exact code which was implemented to readjust learning rates. This ensured that both Generator and Discriminator improve at a steady pace and neither surpass another. Here, learning_rate is a constant value which starts out at 4e-4 and decays by 0.99 every epoch.
generator_learning_rate = max(learning_rate, min(learning_rate * (training_loss_gan_g_loss / training_loss_gan_d_loss), gen_learning_rate*20))
discriminator_learning_rate = min(learning_rate, learning_rate * (training_loss_gan_d_loss/training_loss_gan_g_loss))
Future Prospects
Better input and output representation, bigger size for latent space, more training examples, run for a larger number of epochs. We still believe that this architecture can be used for undertaking music generation, however certain limitations are present such as information about extended sequences are not retained unlike how they would be had we used LSTM based models. Extending this to CycleGAN.
Seq-GAN

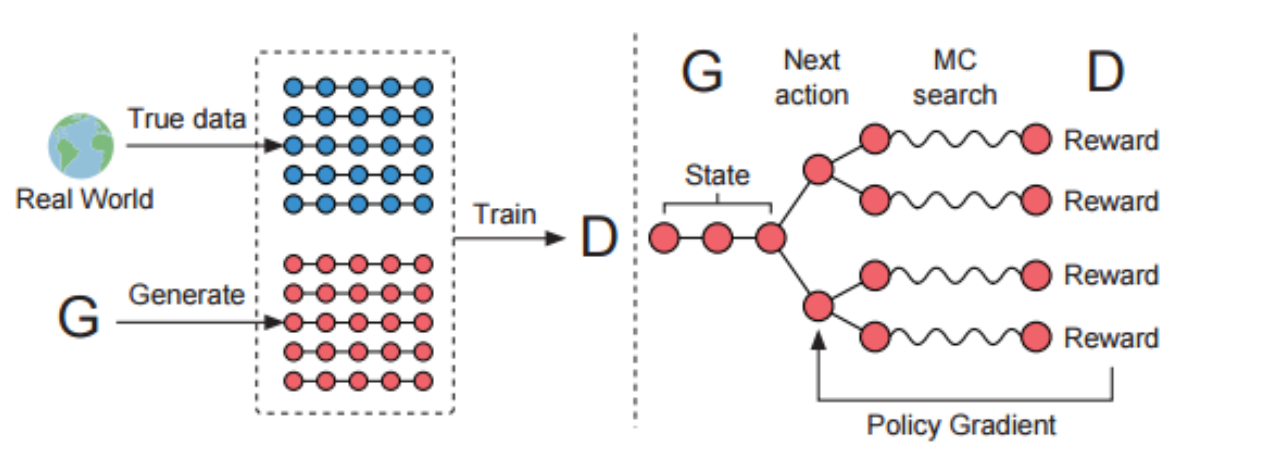
The architecture being used here is the SeqGAN. The following steps were used to implement the the SeqGAN for the purpose of music generation:
- Build a recurrent generator model which samples from its softmax outputs at each timestep.
- Pass sampled sequences to a recurrent discriminator model which distinguishes between sampled sequences and real-data sequences.
- Train the discriminator under the standard GAN loss.
- Train the generator with a REINFORCE (policy gradient) objective, where each trajectory is assigned a single episodic reward: the score assigned to the generated sequence by the discriminator.
The Generative Model
An LSTM based RNN model was used to model the generator that maps the input embedding representations x1, . . . , xT of the sequence x1, . . . , xT into a sequence of hidden states h1,…,hT by using the update function g recursively.
ht =g(ht−1,xt)
softmax output layer z maps the hidden states into the output token distribution.
p(yt|x1, . . . , xt) = z(ht) = softmax(c + V ht), (10)
where the parameters are a bias vector c and a weight matrix V.
The Discriminative Model
We used a CNN based discriminator as CNNs have recently great effectiveness in classifying the token sequences more accurately.
We first represent an input sequence x1,…,xT as:
E[1:T] =x1 ⊕x2 ⊕…⊕xT
where xt ∈ Rk is the k-dimensional token embedding and ⊕ is the concatenation operator to build the matrix E[1:T] ∈ T×k. Then a kernel w ∈ l×k applies a convolutional operation to a window size of l token to produce a new feature map:
ci = ρ(w ⊗ E[i:i+l−1] + b),
where ⊗ operator is the summation of element-wise production, b is a bias term and ρ is a non-linear function. We use relu as the non-linear function in our model for the discriminator and a CNN with following configuration strides=[1, 1, 1, 1], padding=“VALID”.
Finally we apply a max-over-time pooling operation over the feature maps
c ̃= max{c1,…,cT−l+1}
Finally we apply the highway architecture which is based on the pooled feature maps to enhance the performance before the fully connected layer with the sigmoid activation giving the probability of the sequence generated being real.
Discriminator cross entropy loss function:

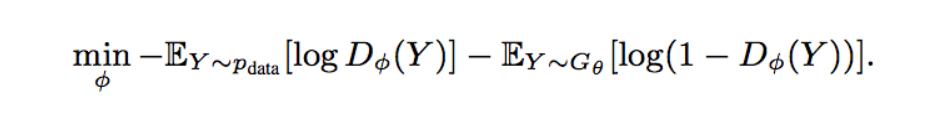
Why Seq-GAN
As of the same reason as of the usage of VAE-GAN, we tried Seq GAN to create covers corresponding to different genres. This required us to have the ability to generate complete songs from scratch. Further extension of this would be implementing a Cycle GAN wherein this architecture can be used as the building block leading to music style transfer. Simple GAN is unstable to train and we lose out on the mapping between the latent space and the generated song. Hence, we used Seq-GAN architecture that can provide the feedback like in RNNs.
Preprocessing:
The given stream of music was separated into musical notes and chords. Musical notes were processed as per our standard preprocessing used with other models
Postprocessing:
The generated track was mapped back to their respective musical notation form and a constant velocity of 80 was used for the regeneration.
Thoughts:
SeqGANs work well due to the fact of the feedback mechanism used from the discriminator to the LSTMs in generators. This helps in the sequences generation giving it a look into the past generated sequence. Though the sequence generation worked well for random new musical output, it cannot be used to control the output generation for style transfer as the the latent vector representation used from the encoder cannot direct the generation as per our input music.
Model Evaluation:
We used BLEU as the evaluation metric to model the discrete piano key patterns and Mean Squared error for the continuous pitch data patterns.
Training and Setup

