
卷積神經網路大總結
大家都清楚神經網路在上個世紀七八十年代是著實火過一回的,尤其是後向傳播BP演算法出來之後,但90年代後被SVM之類搶了風頭,再後來大家更熟悉的是SVM、AdaBoost、隨機森林、GBDT、LR、FTRL這些概念。究其原因,主要是神經網路很難解決訓練的問題,比如梯度消失。當時的神經網路研究進入一個低潮期,不過Hinton老人家堅持下來了。
功夫不負有心人,2006年Hinton和學生髮表了利用RBM編碼的深層神經網路的Science Paper:Reducing the Dimensionality of Data with Neural Networks,不過回頭來看,這篇paper在當今的實用性並不強,它的更大作用是把神經網路又推回到大家視線中,利用單層的RBM自編碼預訓練使得深層的神經網路訓練變得可能,但那時候Deep learning依然爭議很多,最終真正爆發是2012年的ImageNet的奪冠,這是後話。
如圖中所示,這篇paper的主要思想是使用受限RBM先分層訓練,受限的意思是不包含層內的相互連線邊(比如vi*vj或hi*hj)。每一層RBM訓練時的目標是使得能量最小:
能量最小其實就是P(v, h)聯合概率最大,而其他v’相關的p(v’, h)較小,後面這個是歸一化因子相關。這塊如果理解有問題的,需要補一下RBM相關知識,目前網上資料不少了。
大致的過程為,從輸入層開始,不斷進行降維,比如左圖中的2000維降到1000維, 降維時保證能量最小,也就是輸出h和輸入v比較一致,而和其他輸入v’不一致,換句話說,輸出儘量保證輸入的資訊量。降維從目標上比較類似於PCA,但Hinton在文章說這種方法比PCA效果會好很多,尤其是經過多層壓縮的時候(比如784個畫素壓縮到6個實數),從原理應該也是這樣的,RBM每一層都儘量保留了輸入的資訊。
預訓練結束後,就會展開得到中間的解碼器,這是一個疊加的過程,也就是下一層RBM的輸出作為上一層RBM的輸入。
最後再利用真實資料進行引數細調,目標是輸入圖片經過編碼解碼後儘量保持原圖資訊,用的Loss函式是負Log Likelihood:
這篇在今天看來實用性不太大,難度也不大,但在當時這篇文章看起來還是晦澀的,很多原理沒有細講。為何能中Science?個人認為,畢竟Hinton是神經網路的泰斗,換個人名不見經傳的人估計中不了,另外這篇文章也確實使得以前不可能的深層神經網路變得可能了,在今天依然有很多可以借鑑的地方,細心的同學會發現上百或上千層的ResNet的思想在一定程度上和這篇論文是神似的。ResNet也是意識到深層(152層)不好直接訓練,那就在單層上想辦法,將原來直接優化H(x)改為優化殘差F(x) = H(x)-x,其中H(X)是某一層原始的的期望對映輸出,x是輸入,相當於輸入x有個直通車到達該層輸出,從而使得單層的訓練更加容易。
參考部落格:http://www.cnblogs.com/52machinelearning/p/5821587.html
參考資料:
CNN的發展史
上一篇回顧講的是2006年Hinton他們的Science Paper,當時提到,2006年雖然Deep Learning的概念被提出來了,但是學術界的大家還是表示不服。當時有流傳的段子是Hinton的學生在臺上講paper時,臺下的機器學習大牛們不屑一顧,質問你們的東西有理論推導嗎?有數學基礎嗎?搞得過SVM之類嗎?回頭來看,就算是真的,大牛們也確實不算無理取鬧,是騾子是馬拉出來遛遛,不要光提個概念。
時間終於到了2012年,Hinton的學生Alex Krizhevsky在寢室用GPU死磕了一個Deep Learning模型,一舉摘下了視覺領域競賽ILSVRC 2012的桂冠,在百萬量級的ImageNet資料集合上,效果大幅度超過傳統的方法,從傳統的70%多提升到80%多。個人覺得,當時最符合Hinton他們心境的歌非《我不做大哥好多年》莫屬。
這個Deep Learning模型就是後來大名鼎鼎的AlexNet模型。這從天而降的AlexNet為何能耐如此之大?有三個很重要的原因:
- 大量資料,Deep Learning領域應該感謝李飛飛團隊搞出來如此大的標註資料集合ImageNet;
- GPU,這種高度並行的計算神器確實助了洪荒之力,沒有神器在手,Alex估計不敢搞太複雜的模型;
- 演算法的改進,包括網路變深、資料增強、ReLU、Dropout等,這個後面後詳細介紹。
從此,Deep Learning一發不可收拾,ILSVRC每年都不斷被Deep Learning刷榜,如圖1所示,隨著模型變得越來越深,Top-5的錯誤率也越來越低,目前降到了3.5%附近,而在同樣的ImageNet資料集合上,人眼的辨識錯誤率大概在5.1%,也就是目前的Deep Learning模型的識別能力已經超過了人眼。而圖1中的這些模型,也是Deep Learning視覺發展的里程碑式代表。
圖1. ILSVRC歷年的Top-5錯誤率
在仔細分析圖1中各模型結構之前我們先需要了解一下深度學習三駕馬車之一————LeCun的LeNet網路結構。為何要提LeCun和LeNet,因為現在視覺上這些神器都是基於卷積神經網路(CNN)的,而LeCun是CNN的祖師爺,LeNet是LeCun打造的CNN經典之作。
LeNet以其作者名字LeCun命名,這種命名方式類似的還有AlexNet,後來又出現了以機構命名的網路結構GoogLeNet、VGG,以核心演算法命名的ResNet。LeNet有時也被稱作LeNet5或者LeNet-5,其中的5代表五層模型。不過別急,LeNet之前其實還有一個更古老的CNN模型。
最古老的CNN模型
1985年,Rumelhart和Hinton等人提出了後向傳播(Back Propagation,BP)演算法[1](也有說1986年的,指的是他們另一篇paper:Learning representations by back-propagating errors),使得神經網路的訓練變得簡單可行,這篇文章在Google Scholar上的引用次數達到了19000多次,目前還是比Cortes和Vapnic的Support-Vector Networks稍落後一點,不過以Deep Learning最近的發展勁頭來看,超越指日可待。
幾年後,LeCun利用BP演算法來訓練多層神經網路用於識別手寫郵政編碼[2],這個工作就是CNN的開山之作,如圖2所示,多處用到了5*5的卷積核,但在這篇文章中LeCun只是說把5*5的相鄰區域作為感受野,並未提及卷積或卷積神經網路。關於CNN最原始的雛形感興趣的讀者也可以關注一下文獻[10]。
圖2. 最古老的CNN網路結構圖
LeNet
1998年的LeNet5[4]標註著CNN的真正面世,但是這個模型在後來的一段時間並未能火起來,主要原因是費機器(當時苦逼的沒有GPU啊),而且其他的演算法(SVM,老實說是你乾的吧?)也能達到類似的效果甚至超過。
圖3. LeNet網路結構
初學者也可以參考一下Caffe中的配置檔案:
https://github.com/BVLC/caffe/blob/master/examples/mnist/lenet.prototxt
AlexNet、VGG、GoogLeNet、ResNet對比
LeNet主要是用於識別10個手寫數字的,當然,只要稍加改造也能用在ImageNet資料集上,但效果較差。而本文要介紹的後續模型都是ILSVRC競賽歷年的佼佼者,這裡具體比較AlexNet、VGG、GoogLeNet、ResNet四個模型。如表1所示。
| 模型名 | AlexNet | VGG | GoogLeNet | ResNet |
|---|---|---|---|---|
| 初入江湖 | 2012 | 2014 | 2014 | 2015 |
| 層數 | 8 | 19 | 22 | 152 |
| Top-5錯誤 | 16.4% | 7.3% | 6.7% | 3.57% |
| Data Augmentation | + | + | + | + |
| Inception(NIN) | – | – | + | – |
| 卷積層數 | 5 | 16 | 21 | 151 |
| 卷積核大小 | 11,5,3 | 3 | 7,1,3,5 | 7,1,3,5 |
| 全連線層數 | 3 | 3 | 1 | 1 |
| 全連線層大小 | 4096,4096,1000 | 4096,4096,1000 | 1000 | 1000 |
| Dropout | + | + | + | + |
| Local Response Normalization | + | – | + | – |
| Batch Normalization | – | – | – | + |
AlexNet
接下里直接上圖即可,AlexNet結構圖如下:
圖4. AlexNet網路結構
換個視角:
圖5. AlexNet網路結構精簡版
AlexNet相比傳統的CNN(比如LeNet)有哪些重要改動呢:
(1) Data Augmentation
資料增強,這個參考李飛飛老師的cs231課程是最好了。常用的資料增強方法有:
- 水平翻轉
- 隨機裁剪、平移變換
- 顏色、光照變換
(2) Dropout
Dropout方法和資料增強一樣,都是防止過擬合的。Dropout應該算是AlexNet中一個很大的創新,以至於Hinton在後來很長一段時間裡的Talk都拿Dropout說事,後來還出來了一些變種,比如DropConnect等。
(3) ReLU啟用函式
用ReLU代替了傳統的Tanh或者Logistic。好處有:
- ReLU本質上是分段線性模型,前向計算非常簡單,無需指數之類操作;
- ReLU的偏導也很簡單,反向傳播梯度,無需指數或者除法之類操作;
- ReLU不容易發生梯度發散問題,Tanh和Logistic啟用函式在兩端的時候導數容易趨近於零,多級連乘後梯度更加約等於0;
- ReLU關閉了右邊,從而會使得很多的隱層輸出為0,即網路變得稀疏,起到了類似L1的正則化作用,可以在一定程度上緩解過擬合。
當然,ReLU也是有缺點的,比如左邊全部關了很容易導致某些隱藏節點永無翻身之日,所以後來又出現pReLU、random ReLU等改進,而且ReLU會很容易改變資料的分佈,因此ReLU後加Batch Normalization也是常用的改進的方法。
(4) Local Response Normalization
Local Response Normalization要硬翻譯的話是區域性響應歸一化,簡稱LRN,實際就是利用臨近的資料做歸一化。這個策略貢獻了1.2%的Top-5錯誤率。
(5) Overlapping Pooling
Overlapping的意思是有重疊,即Pooling的步長比Pooling Kernel的對應邊要小。這個策略貢獻了0.3%的Top-5錯誤率。
(6) 多GPU並行
這個不多說,比一臂之力還大的洪荒之力。
VGG
VGG結構圖
圖6. VGG系列網路結構
換個視角看看VGG-19:
圖7. VGG-19網路結構精簡版
VGG很好地繼承了AlexNet的衣鉢,一個字:深,兩個字:更深。
GoogLeNet

圖8. GoogLeNet網路結構
GoogLeNet依然是:沒有最深,只有更深。
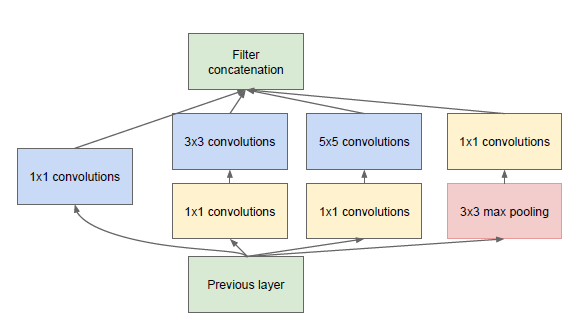
主要的創新在於他的Inception,這是一種網中網(Network In Network)的結構,即原來的結點也是一個網路。Inception一直在不斷髮展,目前已經V2、V3、V4了,感興趣的同學可以查閱相關資料。Inception的結構如圖9所示,其中1*1卷積主要用來降維,用了Inception之後整個網路結構的寬度和深度都可擴大,能夠帶來2-3倍的效能提升。
圖9. Inception結構
ResNet
網路結構如圖10所示。
圖10. ResNet網路結構
ResNet依然是:沒有最深,只有更深(152層)。聽說目前層數已突破一千。
主要的創新在殘差網路,如圖11所示,其實這個網路的提出本質上還是要解決層次比較深的時候無法訓練的問題。這種借鑑了Highway Network思想的網路相當於旁邊專門開個通道使得輸入可以直達輸出,而優化的目標由原來的擬合輸出H(x)變成輸出和輸入的差H(x)-x,其中H(X)是某一層原始的的期望對映輸出,x是輸入。
圖11. ResNet網路結構
總結
Deep Learning一路走來,大家也慢慢意識到模型本身結構是Deep Learning研究的重中之重,而本文回顧的LeNet、AlexNet、GoogLeNet、VGG、ResNet又是經典中的經典。
隨著2012年AlexNet的一舉成名,CNN成了計算機視覺應用中的不二選擇。目前,CNN又有了很多其他花樣,比如R-CNN系列。
參考部落格:http://www.cnblogs.com/52machinelearning/p/5821591.html
[參考文獻]
[1] DE Rumelhart, GE Hinton, RJ Williams, Learning internal representations by error propagation. 1985 – DTIC Document.
[2] Y. LeCun , B. Boser , J. S. Denker , D. Henderson , R. E. Howard , W. Hubbard and L. D. Jackel, “Backpropagation applied to handwritten zip code recognition”, Neural Computation, vol.
1, no. 4, pp. 541-551, 1989.
[3] Kaiming He, Deep Residual Learning, http://image-net.org/challenges/talks/ilsvrc2015_deep_residual_learning_kaiminghe.pdf
[4] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998.
[5] A. Krizhevsky, I. Sutskever, and G. Hinton. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems 25, pages 1106–1114,
2012.
[6] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott E. Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich: Going deeper with convolutions. CVPR
2015: 1-9
[7] Karen Simonyan, Andrew Zisserman: Very Deep Convolutional Networks for Large-Scale Image Recognition. CoRR abs/1409.1556 (2014)
[8] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep Residual Learning for Image Recognition. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016
[9] 一些對應的caffe實現或預訓練好的模型: https://github.com/BVLC/caffe https://github.com/BVLC/caffe/wiki/Model-Zoo
[10] K. Fukushima. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biological Cybernetics, 36(4): 93-202, 1980.
關於卷積神經網路CNN,網路和文獻中有非常多的資料,我在工作/研究中也用了好一段時間各種常見的model了,就想著簡單整理一下,以備查閱之需。如果讀者是初接觸CNN,建議可以先看一看“Deep Learning(深度學習)學習筆記整理系列”中關於CNN的介紹[1],是介紹我們常說的Lenet為例,相信會對初學者有幫助。
- Lenet,1986年
- Alexnet,2012年
- GoogleNet,2014年
- VGG,2014年
- Deep Residual Learning,2015年
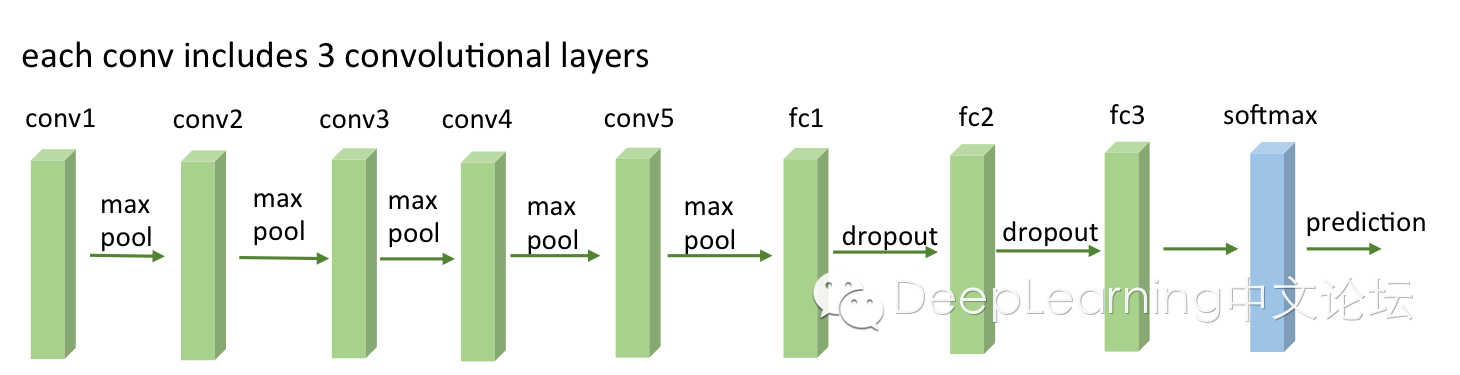
Lenet
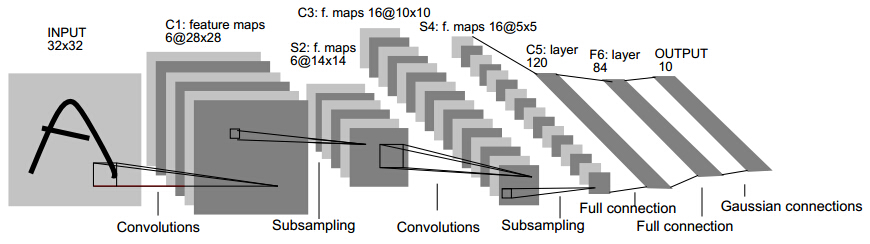
就從Lenet說起,可以看下caffe中lenet的配置檔案(點我),可以試著理解每一層的大小,和各種引數。由兩個卷積層,兩個池化層,以及兩個全連線層組成。 卷積都是5*5的模板,stride=1,池化都是MAX。下圖是一個類似的結構,可以幫助理解層次結構(和caffe不完全一致,不過基本上差不多)
Alexnet
2012年,Imagenet比賽冠軍的model——Alexnet [2](以第一作者alex命名)。caffe的model檔案在這裡。說實話,這個model的意義比後面那些model都大很多,首先它證明了CNN在複雜模型下的有效性,然後GPU實現使得訓練在可接受的時間範圍內得到結果,確實讓CNN和GPU都大火了一把,順便推動了有監督DL的發展。
模型結構見下圖,別看只有寥寥八層(不算input層),但是它有60M以上的引數總量,事實上在引數量上比後面的網路都大。
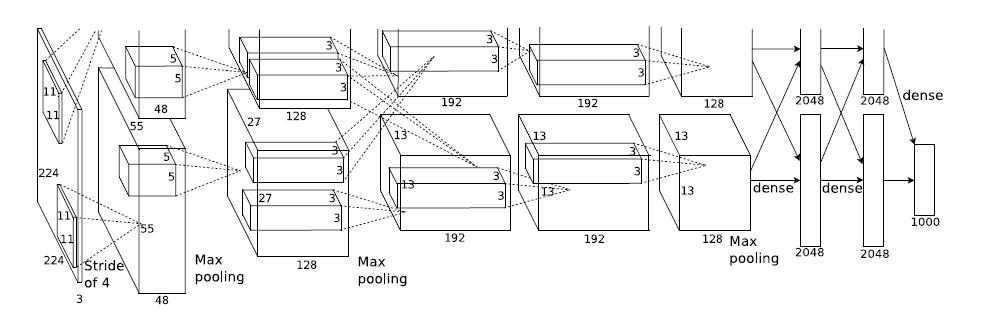
這個圖有點點特殊的地方是卷積部分都是畫成上下兩塊,意思是說吧這一層計算出來的feature map分開,但是前一層用到的資料要看連線的虛線,如圖中input層之後的第一層第二層之間的虛線是分開的,是說二層上面的128map是由一層上面的48map計算的,下面同理;而第三層前面的虛線是完全交叉的,就是說每一個192map都是由前面的128+128=256map同時計算得到的。
Alexnet有一個特殊的計算層,LRN層,做的事是對當前層的輸出結果做平滑處理。下面是我畫的示意圖:
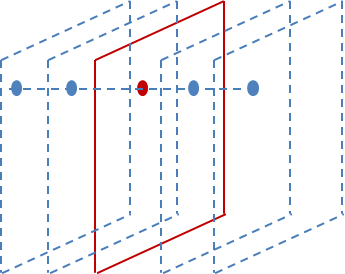
前後幾層(對應位置的點)對中間這一層做一下平滑約束,計算方法是:
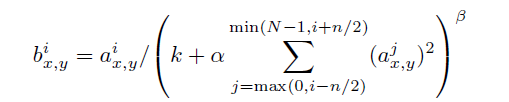
具體開啟Alexnet的每一階段(含一次卷積主要計算)來看[2][3]:
(1)con - relu - pooling - LRN

具體計算都在圖裡面寫了,要注意的是input層是227*227,而不是paper裡面的224*224,這裡可以算一下,主要是227可以整除後面的conv1計算,224不整除。如果一定要用224可以通過自動補邊實現,不過在input就補邊感覺沒有意義,補得也是0。
(2)conv - relu - pool - LRN
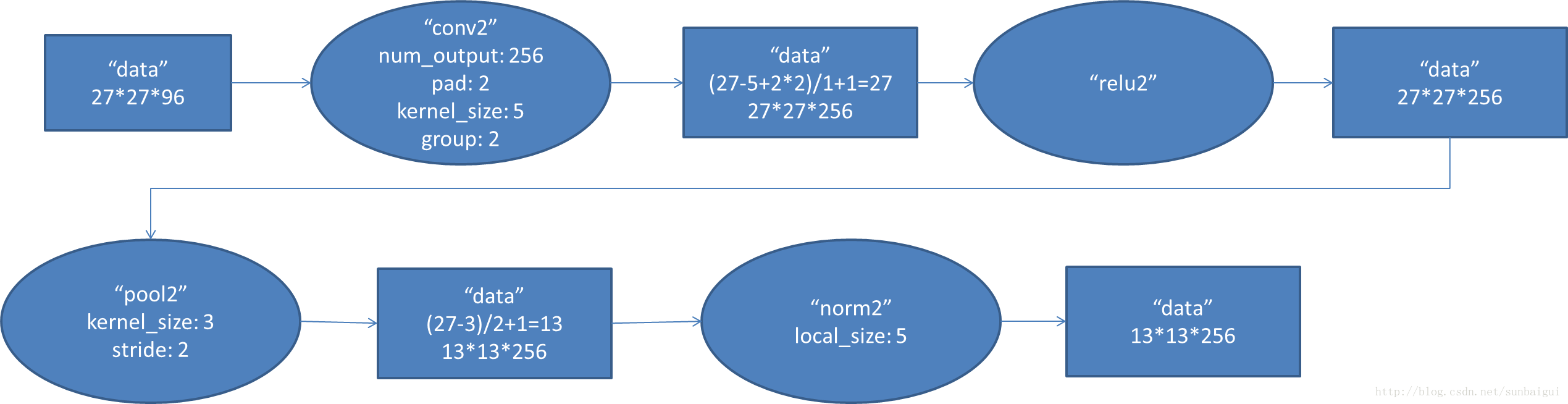
和上面基本一樣,唯獨需要注意的是group=2,這個屬性強行把前面結果的feature map分開,卷積部分分成兩部分做。
(3)conv - relu

(4)conv-relu

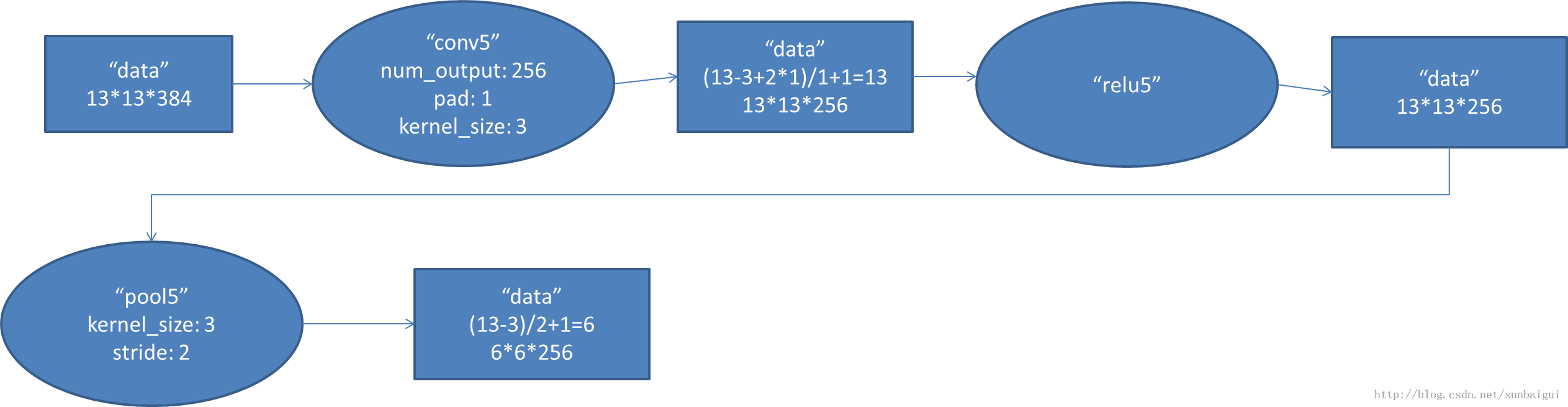
(5)conv - relu - pool
(6)fc - relu - dropout
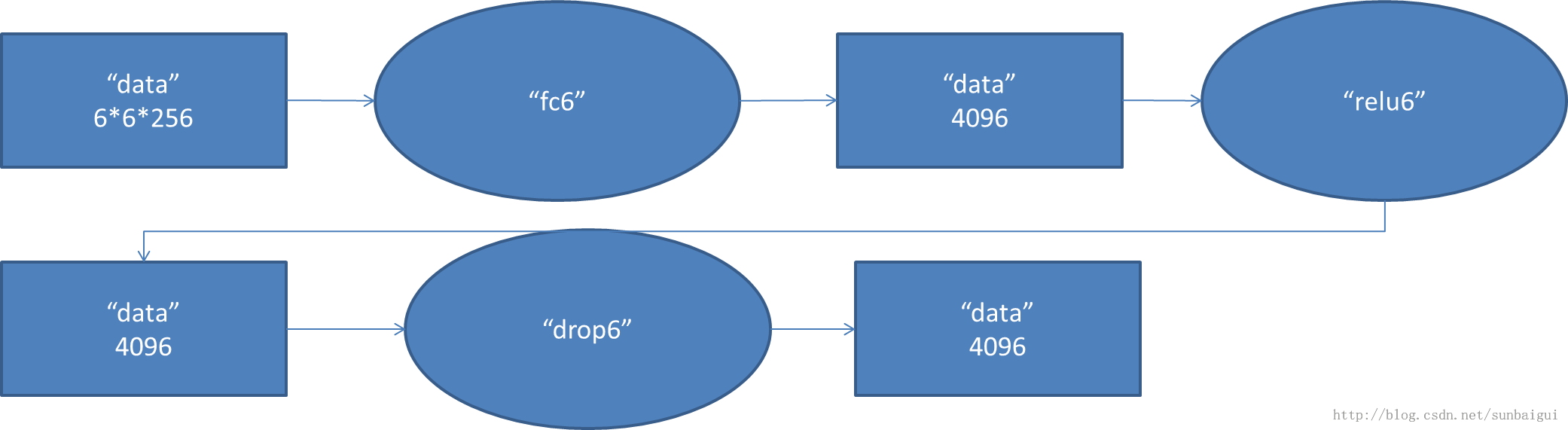
這裡有一層特殊的dropout層,在alexnet中是說在訓練的以1/2概率使得隱藏層的某些neuron的輸出為0,這樣就丟到了一半節點的輸出,BP的時候也不更新這些節點。
(7)
fc - relu - dropout
(8)fc - softmax
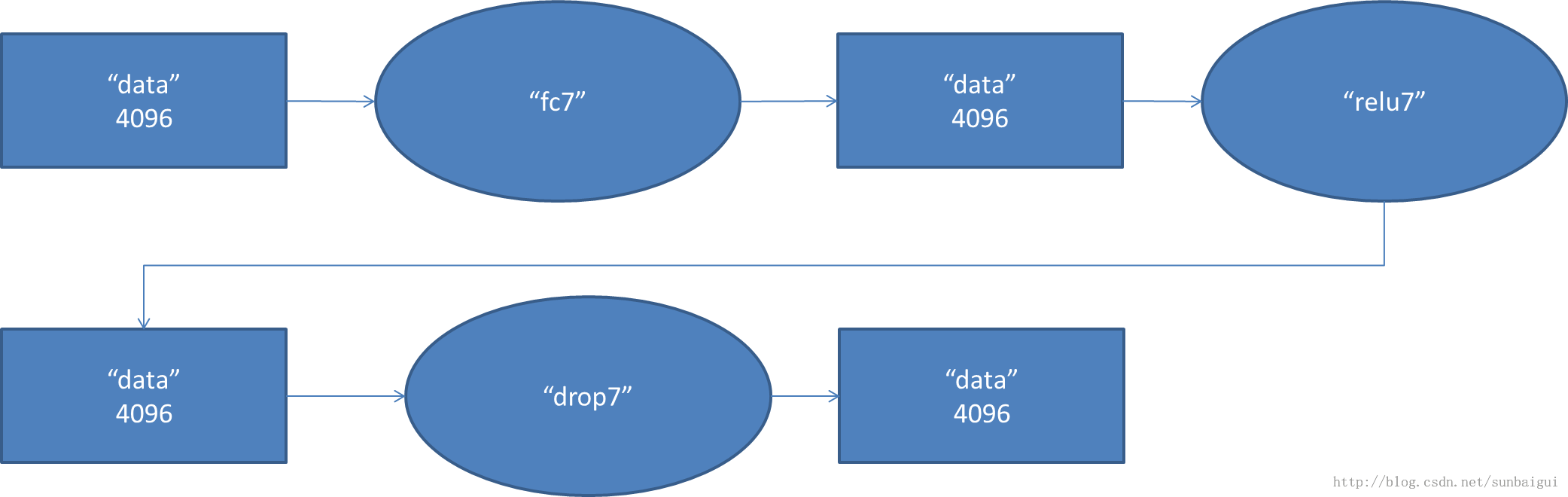

以上圖借用[3],感謝。
GoogleNet
googlenet[4][5],14年比賽冠軍的model,這個model證明了一件事:用更多的卷積,更深的層次可以得到更好的結構。(當然,它並沒有證明淺的層次不能達到這樣的效果)
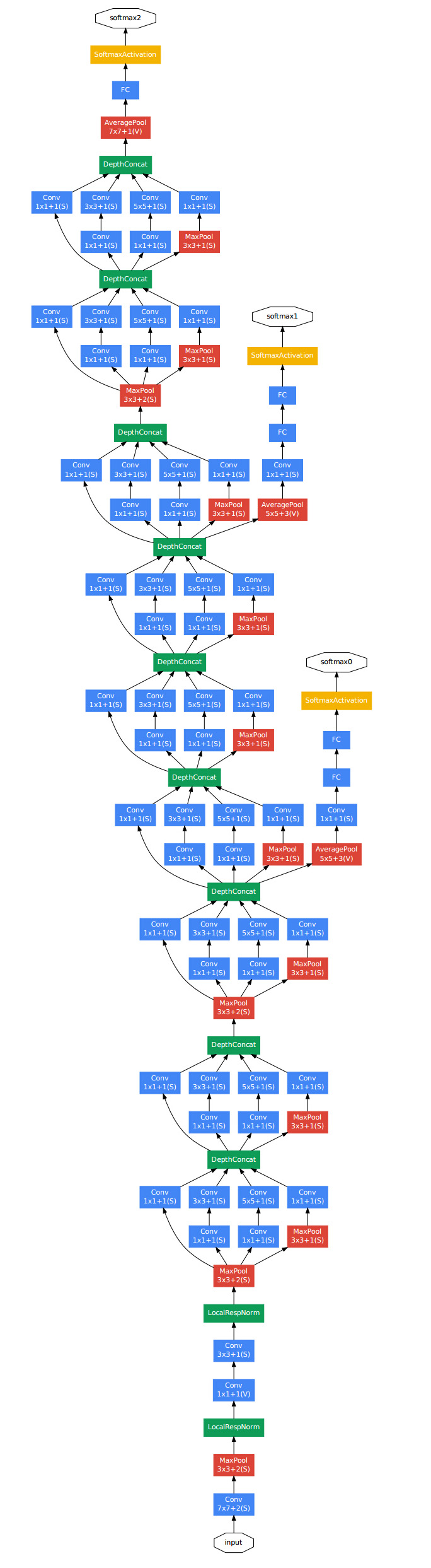
這個model基本上構成部件和alexnet差不多,不過中間有好幾個inception的結構:
是說一分四,然後做一些不同大小的卷積,之後再堆疊feature map。
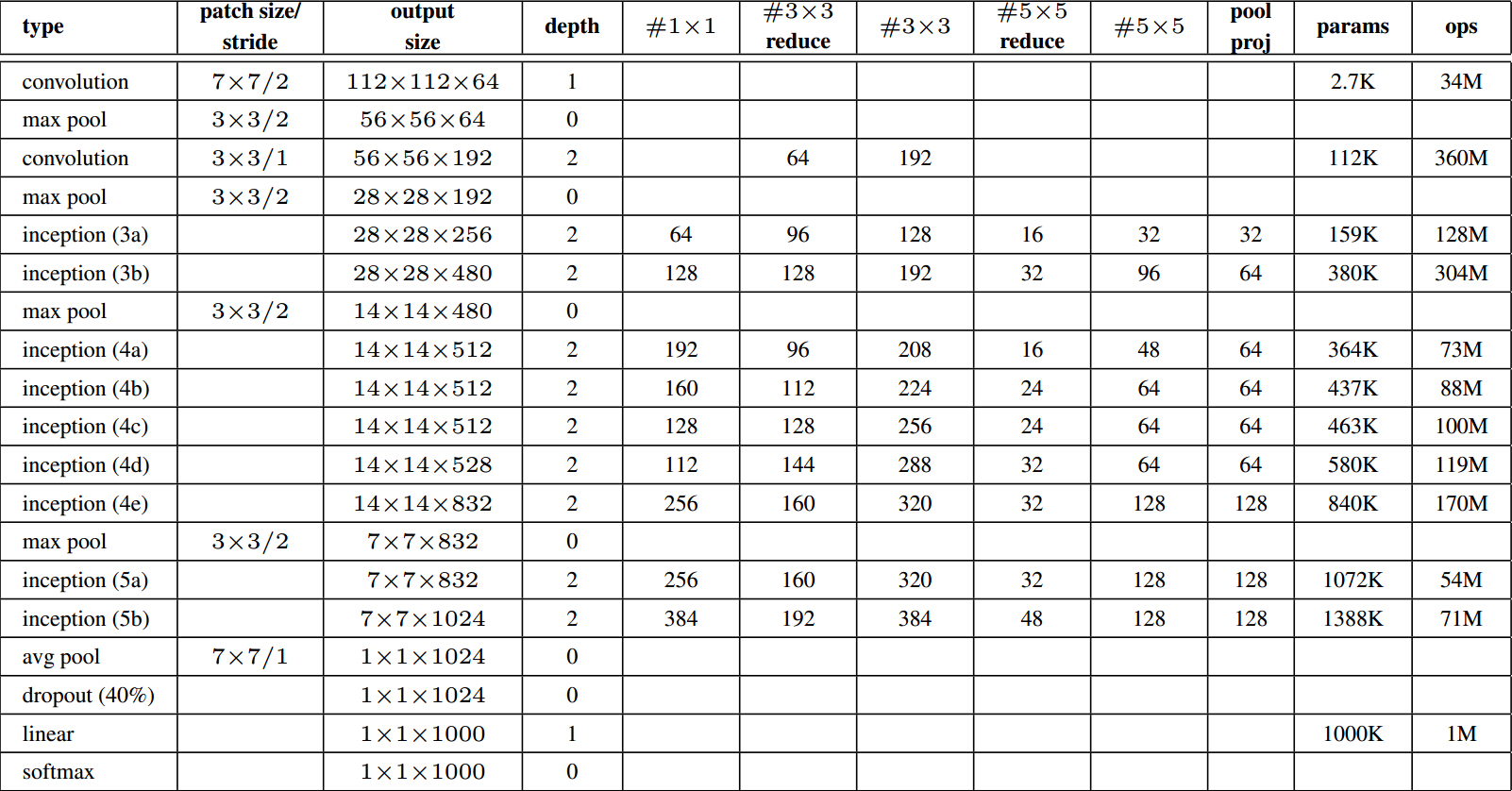
計算量如下圖,可以看到引數總量並不大,但是計算次數是非常大的。
VGG
VGG有很多個版本,也算是比較穩定和經典的model。它的特點也是連續conv多,計算量巨大(比前面幾個都大很多)。具體的model結構可以參考[6],這裡給一個簡圖。基本上組成構建就是前面alexnet用到的。
下面是幾個model的具體結構,可以查閱,很容易看懂。
Deep Residual Learning
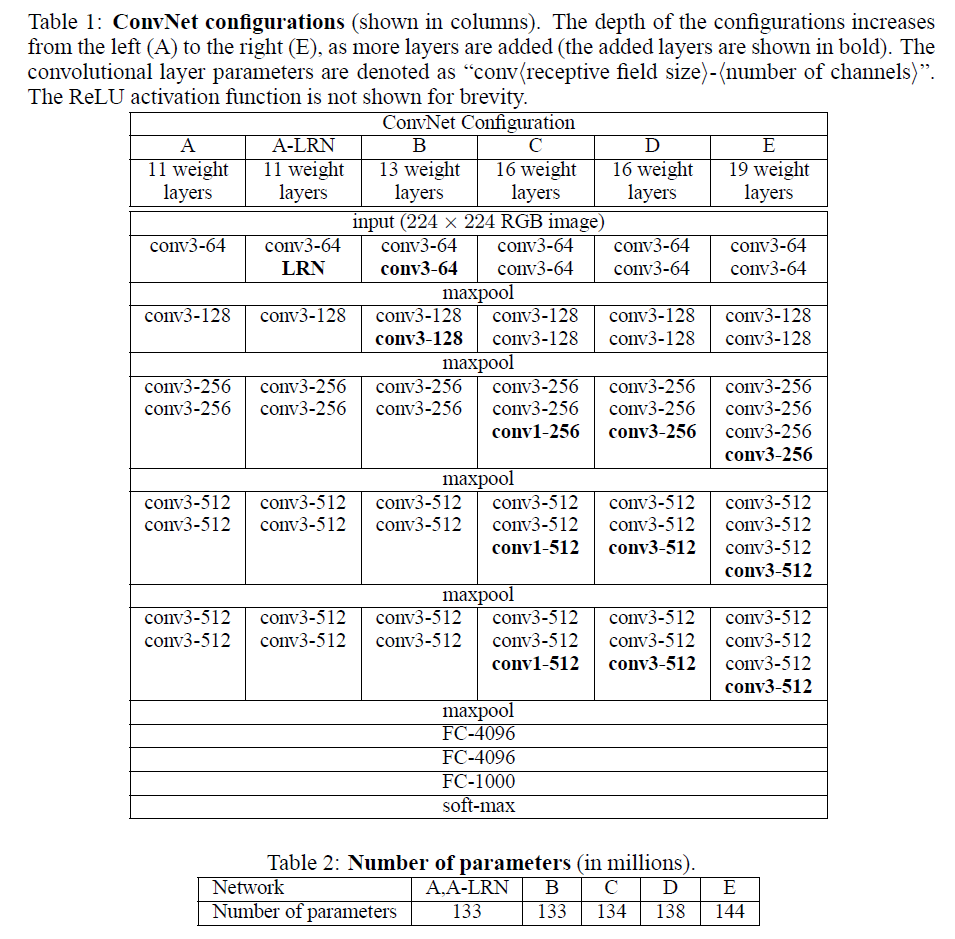
這個model是2015年底最新給出的,也是15年的imagenet比賽冠軍。可以說是進一步將conv進行到底,其特殊之處在於設計了“bottleneck”形式的block(有跨越幾層的直連)。最深的model採用的152層!!下面是一個34層的例子,更深的model見表格。 
其實這個model構成上更加簡單,連LRN這樣的layer都沒有了。
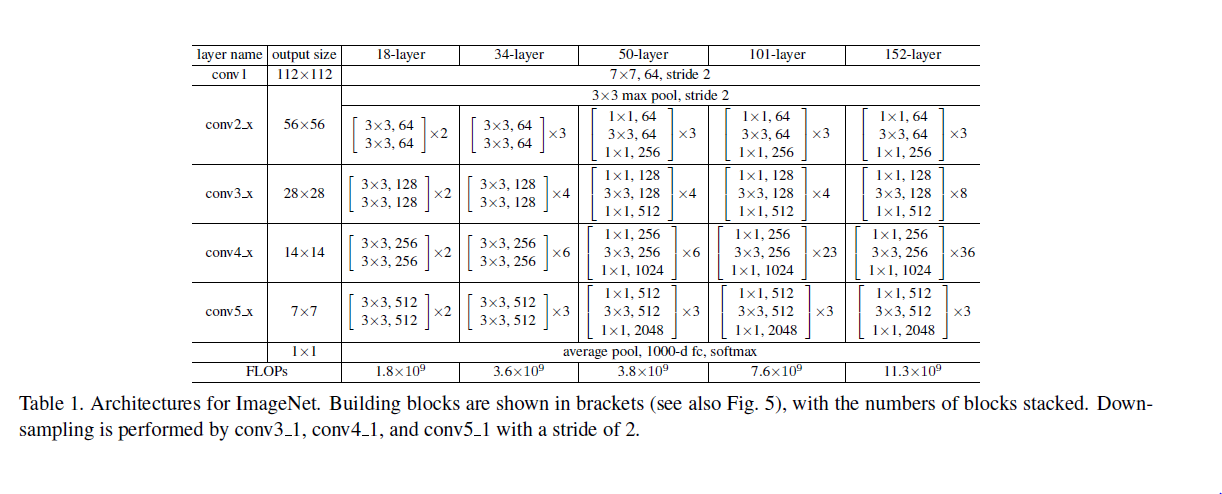
block的構成見下圖:
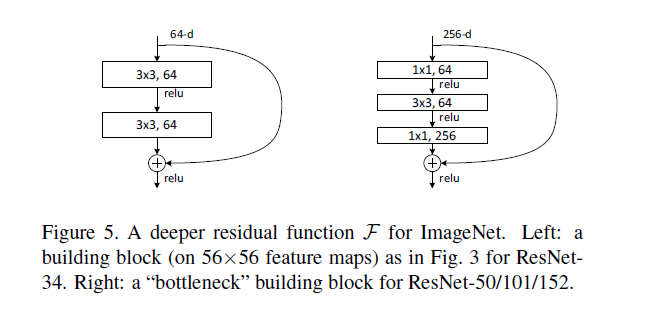
總結
OK,到這裡把常見的最新的幾個model都介紹完了,可以看到,目前cnn model的設計思路基本上朝著深度的網路以及更多的卷積計算方向發展。雖然有點暴力,但是效果上確實是提升了。當然,我認為以後會出現更優秀的model,方向應該不是更深,而是簡化。是時候動一動卷積計算的形式了。
參考部落格:http://blog.csdn.net/xbinworld/article/details/45619685
參考資料
主要討論CNN的發展,並且引用劉昕博士的思路,對CNN的發展作一個更加詳細的介紹,將按下圖的CNN發展史進行描述:

上圖所示是劉昕博士總結的CNN結構演化的歷史,起點是神經認知機模型,此時已經出現了卷積結構,經典的LeNet誕生於1998年。然而之後CNN的鋒芒開始被SVM等手工設計的特徵蓋過。隨著ReLU和dropout的提出,以及GPU和大資料帶來的歷史機遇,CNN在2012年迎來了歷史突破–AlexNet.
CNN的演化路徑可以總結為以下幾個方向:
- 進化之路一:網路結構加深
- 進化之路二:加強卷積功能
- 進化之路三:從分類到檢測
- 進化之路四:新增功能模組
本系列部落格將對CNN發展的四條路徑中最具代表性的CNN模型結構進行講解。
一切的開始( LeNet)
下圖是廣為流傳LeNet的網路結構,麻雀雖小,但五臟俱全,卷積層、pooling層、全連線層,這些都是現代CNN網路的基本元件。

- 輸入尺寸:32*32
- 卷積層:3個
- 降取樣層:2個
- 全連線層:1個
- 輸出:10個類別(數字0-9的概率)
因為LeNet可以說是CNN的開端,所以這裡簡單介紹一下各個元件的用途與意義。
Input (32*32)
輸入影象Size為32*32。這要比mnist資料庫中最大的字母(28*28)還大。這樣做的目的是希望潛在的明顯特徵,如筆畫斷續、角點能夠出現在最高層特徵監測子感受野的中心。
C1, C3, C5 (卷積層)
卷積核在二維平面上平移,並且卷積核的每個元素與被卷積影象對應位置相乘,再求和。通過卷積核的不斷移動,我們就有了一個新的影象,這個影象完全由卷積核在各個位置時的乘積求和的結果組成。
二維卷積在影象中的效果就是:
對影象的每個畫素的鄰域(鄰域大小就是核的大小)加權求和得到該畫素點的輸出值。具體做法如下:

卷積運算一個重要的特點就是: 通過卷積運算,可以使原訊號特徵增強,並且降低噪音。
不同的卷積核能夠提取到影象中的不同特徵,這裡有 線上demo,下面是不同卷積核得到的不同的feature map,

以C1層進行說明:C1層是一個卷積層,有6個卷積核(提取6種區域性特徵),核大小為5*5,能夠輸出6個特徵圖Feature Map,大小為28*28。C1有156個可訓練引數(每個濾波器5*5=25個unit引數和一個bias引數,一共6個濾波器,共(5*5+1)6=156個引數),共156 (28*28)=122,304個連線。
S2, S4 (pooling層)
S2, S4是下采樣層,是為了降低網路訓練引數及模型的過擬合程度。池化/取樣的方式通常有以下兩種:
- Max-Pooling: 選擇Pooling視窗中的最大值作為取樣值;
- Mean-Pooling: 將Pooling視窗中的所有值相加取平均,以平均值作為取樣值;
S2層是6個14*14的feature map,map中的每一個單元於上一層的 2*2 領域相連線,所以,S2層是C1層的1/4。
F6 (全連線層)
F6是全連線層,類似MLP中的一個layer,共有84個神經元(為什麼選這個數字?跟輸出層有關),這84個神經元與C5層進行全連線,所以需要訓練的引數是:(120+1)*84=10164.
如同經典神經網路,F6層計算輸入向量和權重向量之間的點積,再加上一個偏置。然後將其傳遞給sigmoid函式產生單元i的一個狀態。
Output (輸出層)
輸出層由歐式徑向基函式(Euclidean Radial Basis Function)單元組成,每類一個單元,每個有84個輸入。
換句話說,每個輸出RBF單元計算輸入向量和引數向量之間的歐式距離。輸入離引數向量越遠,RBF輸出的越大。用概率術語來說,RBF輸出可以被理解為F6層配置空間的高斯分佈的負log-likelihood。給定一個輸式,損失函式應能使得F6的配置與RBF引數向量(即模式的期望分類)足夠接近。

AlexNet 可以說是具有歷史意義的一個網路結構,可以說在AlexNet之前,深度學習已經沉寂了很久。歷史的轉折在2012年到來,AlexNet 在當年的ImageNet影象分類競賽中,top-5錯誤率比上一年的冠軍下降了十個百分點,而且遠遠超過當年的第二名。
AlexNet 之所以能夠成功,深度學習之所以能夠重回歷史舞臺,原因在於:
- 非線性啟用函式:ReLU
- 防止過擬合的方法:Dropout,Data augmentation
- 大資料訓練:百萬級ImageNet影象資料
- 其他:GPU實現,LRN歸一化層的使用
下面簡單介紹一下AlexNet的一些細節:
Data augmentation
有一種觀點認為神經網路是靠資料喂出來的,若增加訓練資料,則能夠提升演算法的準確率,因為這樣可以避免過擬合,而避免了過擬合你就可以增大你的網路結構了。當訓練資料有限的時候,可以通過一些變換來從已有的訓練資料集中生成一些新的資料,來擴大訓練資料的size。
其中,最簡單、通用的影象資料變形的方式:
- 從原始影象(256,256)中,隨機的crop出一些影象(224,224)。【平移變換,crop】
- 水平翻轉影象。【反射變換,flip】
- 給影象增加一些隨機的光照。【光照、彩色變換,color jittering】

AlexNet 訓練的時候,在data augmentation上處理的很好:
- 隨機crop。訓練時候,對於256*256的圖片進行隨機crop到224*224,然後允許水平翻轉,那麼相當與將樣本倍增到((256-224)^2)*2=2048。
- 測試時候,對左上、右上、左下、右下、中間做了5次crop,然後翻轉,共10個crop,之後對結果求平均。作者說,不做隨機crop,大網路基本都過擬合(under substantial overfitting)。
- 對RGB空間做PCA,然後對主成分做一個(0, 0.1)的高斯擾動。結果讓錯誤率又下降了1%。
ReLU 啟用函式
Sigmoid 是常用的非線性的啟用函式,它能夠把輸入的連續實值“壓縮”到0和1之間。特別的,如果是非常大的負數,那麼輸出就是0;如果是非常大的正數,輸出就是1.
但是它有一些致命的 缺點:
- Sigmoids saturate and kill gradients. sigmoid 有一個非常致命的缺點,當輸入非常大或者非常小的時候,會有飽和現象,這些神經元的梯度是接近於0的。如果你的初始值很大的話,梯度在反向傳播的時候因為需要乘上一個sigmoid 的導數,所以會使得梯度越來越小,這會導致網路變的很難學習。
- Sigmoid 的 output 不是0均值. 這是不可取的,因為這會導致後一層的神經元將得到上一層輸出的非0均值的訊號作為輸入。
產生的一個結果就是:如果資料進入神經元的時候是正的(e.g. x>0 elementwise in f=wTx+b),那麼 w 計算出的梯度也會始終都是正的。
當然了,如果你是按batch去訓練,那麼那個batch可能得到不同的訊號,所以這個問題還是可以緩解一下的。因此,非0均值這個問題雖然會產生一些不好的影響,不過跟上面提到的 kill gradients 問題相比還是要好很多的。
ReLU 的數學表示式如下:
很顯然,從圖左可以看出,輸入訊號<0時,輸出都是0,>0 的情況下,輸出等於輸入。w 是二維的情況下,使用ReLU之後的效果如下:

Alex用ReLU代替了Sigmoid,發現使用 ReLU 得到的SGD的收斂速度會比 sigmoid/tanh 快很多。
主要是因為它是linear,而且 non-saturating(因為ReLU的導數始終是1),相比於 sigmoid/tanh,ReLU 只需要一個閾值就可以得到啟用值,而不用去算一大堆複雜的運算。
關於啟用函式更多內容,請移步我的另一篇文章:http://blog.csdn.net/cyh_24/article/details/50593400
Dropout
結合預先訓練好的許多不同模型,來進行預測是一種非常成功的減少測試誤差的方式(Ensemble)。但因為每個模型的訓練都需要花了好幾天時間,因此這種做法對於大型神經網路來說太過昂貴。
然而,AlexNet 提出了一個非常有效的模型組合版本,它在訓練中只需要花費兩倍於單模型的時間。這種技術叫做Dropout,它做的就是以0.5的概率,將每個隱層神經元的輸出設定為零。以這種方式“dropped out”的神經元既不參與前向傳播,也不參與反向傳播。
所以每次輸入一個樣本,就相當於該神經網路就嘗試了一個新的結構,但是所有這些結構之間共享權重。因為神經元不能依賴於其他特定神經元而存在,所以這種技術降低了神經元複雜的互適應關係。
正因如此,網路需要被迫學習更為魯棒的特徵,這些特徵在結合其他神經元的一些不同隨機子集時有用。在測試時,我們將所有神經元的輸出都僅僅只乘以0.5,對於獲取指數級dropout網路產生的預測分佈的幾何平均值,這是一個合理的近似方法。
多GPU訓練
單個GTX 580 GPU只有3GB記憶體,這限制了在其上訓練的網路的最大規模。因此他們將網路分佈在兩個GPU上。
目前的GPU特別適合跨GPU並行化,因為它們能夠直接從另一個GPU的記憶體中讀出和寫入,不需要通過主機記憶體。
相關推薦
卷積神經網路大總結
大家都清楚神經網路在上個世紀七八十年代是著實火過一回的,尤其是後向傳播BP演算法出來之後,但90年代後被SVM之類搶了風頭,再後來大家更熟悉的是SVM、AdaBoost、隨機森林、GBDT、LR、FTRL這些概念。究其原因,主要是神經網路很難解決訓練的問題,比如梯度消
深度學習卷積神經網路大事件一覽
深度學習(DeepLearning)尤其是卷積神經網路(CNN)作為近幾年來模式識別中的研究重點,受到人們越來越多的關注,相關的參考文獻也是層出不窮,連續幾年都佔據了CVPR的半壁江山,但是萬變不離其宗,那些在深度學習發展過程中起到至關重要的推動作用的經典文獻依然值得回味
卷積神經網路總結
轉載自:https://www.cnblogs.com/skyfsm/p/6790245.html 從神經網路到卷積神經網路(CNN) 我們知道神經網路的結構是這樣的: 那捲積神經網路跟它是什麼關係呢? 其實卷積神經網路依舊是層級網路,只是層的功能和形式做了變化,可以說是傳
變形卷積核、可分離卷積?卷積神經網路中十大拍案叫絕的操作
大家還是去看原文好,作者的文章都不錯: https://zhuanlan.zhihu.com/p/28749411 https://www.zhihu.com/people/professor-ho/posts 一、卷積只能在同一組進行嗎?-- Group convo
卷積神經網路中十大拍案叫絕的操作
從2012年的AlexNet發展至今,科學家們發明出各種各樣的CNN模型,一個比一個深,一個比一個準確,一個比一個輕量。我下面會對近幾年一些具有變革性的工作進行簡單盤點,從這些充滿革新性的工作中探討日後的CNN變革方向。 很棒的分享, 轉自 CVer 卷積
卷積神經網路中十大拍案叫絕的操作:卷積核大小好處、變形卷積、可分離卷積等
文章轉自:https://www.leiphone.com/news/201708/0rQBSwPO62IBhRxV.html 從2012年的AlexNet發展至今,科學家們發明出各種各樣的CNN模型,一個比一個深,一個比一個準確,一個比一個輕量。我下面會對近幾年一些具有變革性的工作進行簡單盤點
CS231n 卷積神經網路與計算機視覺 6 資料預處理 權重初始化 規則化 損失函式 等常用方法總結
1 資料處理 首先註明我們要處理的資料是矩陣X,其shape為[N x D] (N =number of data, D =dimensionality). 1.1 Mean subtraction 去均值 去均值是一種常用的資料處理方式.它是將各個特徵值減去其均
盤點卷積神經網路中十大令人拍案叫絕的操作
轉載自https://www.jianshu.com/p/71804c97123d CNN從2012年的AlexNet發展至今,科學家們發明出各種各樣的CNN模型,一個比一個深,一個比一個準確,一個比一個輕量。我下面會對近幾年一些具有變革性的工作進行簡單盤點,從這些充滿革新性的工作中探討日後
經典卷積神經網路總結:Inception v1\v2\v3\v4、ResNet、ResNext、DenseNet、SENet等
本文為總結今年來的卷積神經網路,主要按照時間線和方法類似程度的順序總結。 開篇先前說下概要,然後展開詳細介紹,主要是在densenet、resnext、senet這三個網路上介紹,前面的一系列網路大概講一下思想。 1、時間軸 時間
深度學習(卷積神經網路)問題總結
深度卷積網路 涉及問題: 1.每個圖如何卷積: (1)一個圖如何變成幾個? (2)卷積核如何選擇? 2.節點之間如何連線? 3.S2-C3如何進行分配? 4.1
06《基於卷積神經網路LeNet-5的車牌字元識別研究》學習總結
一、本篇介紹 二、本文主要內容(知識點) 1、概要 2、卷積神經網路介紹 1.卷積層 2.次抽樣層 3、LeNet-5介
吳恩達《卷積神經網路》課程總結
Note This is my personal summary after studying the course, convolutional neural networks, which belongs to Deep Learning Specialization.
卷積神經網路(CNN)的規律總結
本篇部落格主要講述卷積神經網路(CNN)的一般規律和一些基本的特性。 卷積神經網路的區域性連線、權值共享以及池化操作等特性使之可以有效地降低網路的複雜度,減少訓練引數的數目,使模型對平移
卷積神經網路中10大拍案叫絕的操作
CNN從2012年的AlexNet發展至今,科學家們發明出各種各樣的CNN模型,一個比一個深,一個比一個準確,一個比一個輕量。我下面會對近幾年一些具有變革性的工作進行簡單盤點,從這些充滿革新性的工作中探討日後的CNN變革方向。注:水平所限,下面的見解或許有偏差,望大牛指正。另外只介紹其中具有代表性的模型,一些
02《卷積神經網路研究綜述》學習總結
一、本篇介紹 篇名:卷積神經網路研究綜述 作者:周飛燕,金林鵬,董軍 作者單位:中國科學院 發表在:計算機學報,2017年6月 二、主要內容 1、神經網路的歷史 1943年,心理學家McCulloch和數理邏輯學家Pitts提出
深度學習進階(六)--CNN卷積神經網路除錯,錯誤歷程總結
總結一下今天的學習過程 (注:我此刻的心情與剛剛三分鐘前的心情是完全不一樣的) (昨天在想一些錯誤,今天又重拾信心重新配置GPU環境,結果很失敗,不過現在好了,在尋思著今天干了什麼的時候,無意間想到是不是自己方法入口不對啊。結果果然很幸運的被我猜到了,,,哈哈哈,我的心情又
【深度學習技術】卷積神經網路常用啟用函式總結
本文記錄了神經網路中啟用函式的學習過程,歡迎學習交流。 神經網路中如果不加入啟用函式,其一定程度可以看成線性表達,最後的表達能力不好,如果加入一些非線性的啟用函式,整個網路中就引入了非線性部分,增加了網路的表達能力。目前比較流行的啟用函式主要分為以下7種:
機器學習總結之卷積神經網路一些點
1 卷積層的使用:濾波器雖然是一個矩陣,但是深層角度來說是有很多種類的,比如整體邊緣濾波器,縱向邊緣濾波器,橫向邊緣濾波器,比如通過橫向邊緣濾波器就可以保留橫向邊緣資訊。事實上,卷積神經網路中的卷積核引數都是通過網路學習得出的,除了可以學到類似於橫向,縱向邊緣濾波器,還可以學到任意角度的邊緣濾波器。不僅如此,
深度學習(卷積神經網路)一些問題總結
深度卷積網路涉及問題:1.每個圖如何卷積:(1)一個圖如何變成幾個?(2)卷積核如何選擇?2.節點之間如何連線?3.S2-C3如何進行分配?4.16-120全連線如何連線?5.最後output輸出什麼形式?①各個層解釋: 我們先要明確一點:每個層有多個Feature Ma
Keras學習(四)——CNN卷積神經網路
本文主要介紹使用keras實現CNN對手寫資料集進行分類。 示例程式碼: import numpy as np from keras.datasets import mnist from keras.utils import np_utils from keras.models impo