Temporal Action Detection (時序動作檢測)綜述
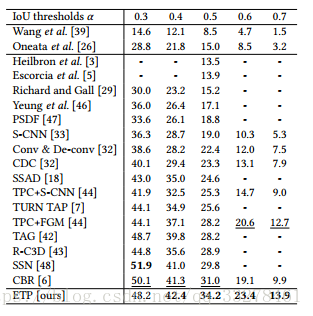
最近幾年由於網路上視訊量的急劇增多和神經網路的飛快發展,這項任務得到了更多的關注。目前這項任務的主要資料集有THUMOS2014、ActivityNet。評價指標為IOU,目前2017的大多數工作在IOU=0.5的情況下達到了20%-30%的MAP,雖然較2016年提升了10%左右,但是在IOU=0.7時直接降低到了10%以下,2018年IOU=0.5有34%的MAP。
目前的趨勢是尋找視訊內活動的相關性來更精準的定位,尋找可以代替光流的方法來加速模型。本文對近兩年時序動作檢測的主要工作進行了一個簡單的綜述。
本文主要是之前的筆記整理,有錯誤或者說的不好的地方請指出啊,請鞭笞我。
一、任務
時序動作檢測主要解決的是兩個任務:localization+recognization
1)where:什麼時候發生動作,即開始和結束時間;
2)what:每段動作是什麼類別
一般把這個任務叫做Temporal Action Detection,有的直接叫Action Detection,還有叫Action Localization、
二:評價指標:
1).average recall (AR):
Temporal Action Proposal任務不需要對活動分類,只需要找出proposals,所以判斷找的temporal proposals全不全就可以測評方法好壞,常用average recall (AR) ,Average Recall vs. Average Number of Proposals per Video (AR-AN) 即曲線下的面積(ActivityNet Challenge 2017就用這個測評此項任務)。如下圖:

2).mean Average Precision (mAP) :
Temporal Action Detection(Localization)問題中最常用的評估指標。一般對tIOU=0.5的進行對比,tIOU是時間上的交併。
三、DataSet:
1.THUMOS2014
該資料集包括行為識別和時序行為檢測兩個任務,大多數論文都在此資料集評估。
訓練集:UCF101資料集,101類動作,共13320段分割好的視訊片段;
驗證集:1010個未分割過的視訊;其中200個視訊有時序行為標註(3007個行為片 段,只有20類,可用於時序動作檢測任務)
測試集:1574個未分割過的視訊;其中213個視訊有時序行為標註(3358個行為片段,只有20類,可用於時序動作檢測任務)
2.ActivityNet
200類,每類100段未分割視訊,平均每段視訊發生1.54個行為,共648小時
3.MUTITHUMOS
一個稠密、多類別、逐幀標註的視訊資料集,包括30小時的400段視訊,65個行為類別38,690個標註,平均每幀1.5個label,每個視訊10.5個行為分類,算是加強版THUMOS,目前我只在Learning Latent Super-Events to Detect Multiple Activities in Videos這篇論文看到了該資料集的評估。
建議:
四、基本流程
1.先找proposal,在對proposal分類和迴歸邊界
2.找proposal方法:主要就是以下幾種
(1)單純的滑動視窗(SCNN提出):
固定一些尺寸在視訊長度上滑窗,重疊度越高,效果越好,但是計算量大。
理論上這種方法只要重疊度夠高,是找的最全的,但是冗餘多。
(2)時序動作分組(TAG提出):
逐個視訊幀分類(CNN網路),把相鄰的類別一樣的分成一組,設定一些閾值防止噪聲干擾,一般設定多組閾值防止漏掉proposal。這種方法對於邊界比較靈活,但是可能會因為分類錯誤漏掉proposal。
(3)單元迴歸(TURN提出):
把視訊分成固定大小單元,比如16視訊幀一組,每組學一個特徵(放C3D裡),然後每組或者多組作為中心anchor單元(參照faster-rcnn)向兩端擴充套件找不同長度proposal。
五、目前的主要方法
1.SCNN(Temporal Action Localization in Untrimmed Videos via Multi-stage CNNs):
多階段網路,這篇文章是CVPR2016上的工作“Temporal action localization in untrimmed videos via multi-stage cnns”,時間較早,方法簡單。主要提出了一個三階段的3D卷積網路來做動作檢測:(1)proposal network;(2)classification network;(3)localization network。
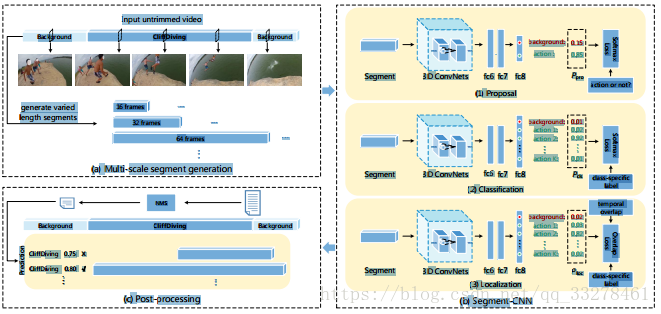
圖1.scnn框架總覽
該網路首先採用不同尺度滑窗的方法找一些proposal,然後將這些proposal均勻取樣到固定長度16幀,將proposal輸入到proposal network來做二分類,輸出是不是動作;然後將包含動作的proposal和部分背景proposal(取樣到和一類動作數目相同)輸入到classification network為這些動作分類,輸出為K+1個類別(包括背景類)的分數;最後輸入到一個localization network,輸出仍然是K+1個類別的分數,不過此時的損失函式不只是softmax loss,還加入基於IoU分數的overlap Loss來調整邊界。以上三個網路均採用標準C3D網路結構,定位網路由分類網路的權值來初始化,分類網路只在訓練時使用。
這篇文章在THUMOS2014資料集上IOU=0.5時達到了19.0的MAP。
2.TURN(TURN TAP: Temporal Unit Regression Network for Temporal Action Proposals):
單元迴歸網路,SCNN中採用的滑窗找proposal的如果想要得到準確的結果,就需要增大視窗之間的重疊度,這樣導致了一個問題就是計算量極大。為了減小計算量,增加時序定位精度,本文借鑑faster-rcnn引入邊界迴歸的方法:將視訊分為等長短單元,做單元水平的迴歸。
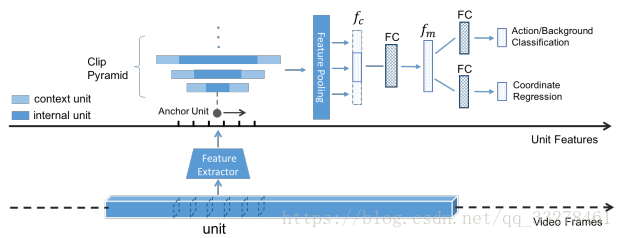
每個單元輸入到C3D網路內提取單元水平特徵,相鄰單元組成一個clip,以每一個unit為anchor unit,構造一個clip pyramid。然後在單元水平上作座標迴歸,網路包含兩個輸出:第一個輸出置信度分數判斷clip中是否包含動作,第二個輸出時序座標偏移來調整邊界。
本篇文章方法在THUMOS2014資料集IOU=0.5時的MAP為25.6%,主要貢獻是(1)提出了一個新的用座標迴歸來生成時序提議段的方法;(2)速度很快(800fps)(3)在不同資料集上不需要做fine-tuning效果就很好(4)提出了新的評估提議段好壞的指標AR-F。
3.TAG(A Pursuit of Temporal Accuracy in General Activity Detection):
時序動作分組,也是為了解決密集的滑動視窗計算量太大的問題而提出的方法。TAG的方法主要由三部分組成(1)用TSN的稀疏取樣方法取樣一段視訊裡的snippt;(2)給snippt打分,這裡是二分類判斷它是是不是動作;(3)把是動作的snippt組成一個proposal,就得到了不同粒度的提議段(這裡會設定動作閾值來表示多少分可以算作動作,還有一個容忍度閾值來防止噪聲干擾,即連續幀中出現了幾個視訊幀不滿足的情況下仍把它加入proposal)。這篇文章還把是否是動作與動作是否完整作為兩個不同的特徵。核心思想是找有更多動作的proposal。
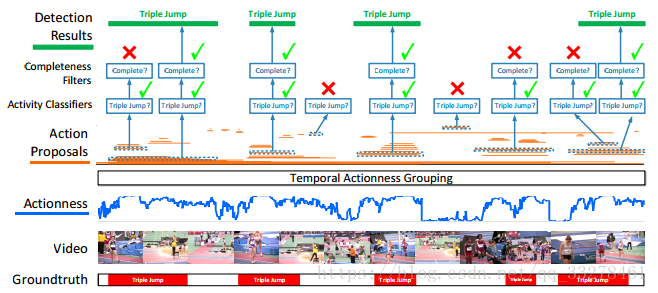
TAG的方法有以下幾個優點:(1)更關注動作做內容,減少了proposal數目,減少計算量;(2)合併片段是自底向上的,更加精確;(3)設定多個閾值組合,可以不需改變引數的訓練。
本文在THUMOS2014上IOU=0.5時候MAP=28.25。
4.CDC(CDC: Convolutional-De-Convolutional Networks for Precise Temporal Action Localization in Untrimmed Videos):
卷積-反捲積網路,該網路主要是在scnn中提到的用滑窗產生proposal的方法基礎上繼續做精調。C3D可以很好的學習高階語義特徵,但是它在時間上會丟失細粒度(標準C3D網路會把時間減少到原來的1/8長度)這時候如果想在視訊幀的水平上做精確定位是不可能的,但是可以用反捲積的方式進行上取樣。所以本文提出了一種在空間上做下采樣(1*1的類別資訊),時間上做上取樣(恢復到原視訊長L)的方法。
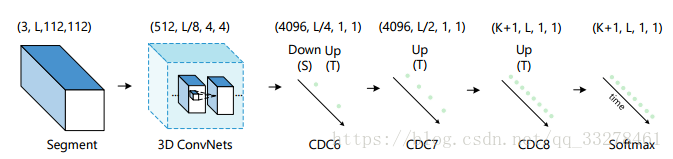

本文還提出了一個把卷積和反捲積操作結合到一起的過濾器,實驗證明這個結合的方法比分開計算效果要好一些,但是引數多了很多。網路首先把scnn得到的proposal向兩端擴充套件,然後每幀打分,哪類平均分最高就作為類別,然後從兩端往中心一直找到一個分數高於均分的視訊幀作為邊界,裡面的內容就是我們找到的動作。
本文在THUMOS2014上IOU=0.5時的MAP=23.3%。
CDC主要貢獻:(1)提出了一個卷積-反捲積過濾器(2)用上述過濾器建立了一個端到端的網路3)提到了定位精度。
5.SSN(Temporal Action Detection with Structured Segment Networks):
結構化分段網路,提出了一個通過結構化時序金字塔對每一個動作例項的時序結構建模的新框架。作者認為對視訊檢測是一個十分難的問題,所以需要對時序結構進行分析,判斷動作是不是完整,所以他把視訊內的動作劃分為三個階段:開始,行動,結束。這個劃分方式在以後的工作中也被大量使用。本文采用了TAG的方法生成proposal,然後把proposal分成開始,活動,結束三個階段,對每個階段做時間上的金子塔池化操作,然後把結果合併在一起送入兩個分類器,一個判斷該段是什麼動作,一個判斷動作完整不完整。
本文在THUMOS上IOU=0.5的時候MAP=29.8.
主要貢獻:(1)提出一個有效的三階段機制來建模活動的時間結構,從而區分完整和不完整的proposal;(2)以端到端的方式學習網路,並且一旦訓練完畢,就可以對時間結構進行快速推測;(3)該方法在主流資料集THUMOS14和ActivityNet上實現了超過以前的檢測效能。
6.CBR(Cascaded Boundary Regression for Temporal Action Detection):
級聯的邊界迴歸網路,這篇論文獲得了2017年在THUMOS2014資料集上的最佳效果。方法比較簡單,作者做了大量的實驗,對很多引數的選擇都做了比較好的實驗,為後人科研選擇合適的方法給了一些啟發。CBR是在TURN的基礎上做的,網路分為兩部分,第一部分用粗略proposal作為輸入,輸出類別無關的proposal,第二部分來繼續調整邊界。

與之前方法比較這裡每一部分都是級聯的,意思就是調整一次效果不好,就繼續調整,一直到效果好位置。這裡和TURN不同的是找的proposal不在是根據是不是動作,而且為每個動作都通過單元迴歸找一個proposal,把分數最高的作為我們要找的proposal。網路對C3D,TWO STREAM,FLOW特徵進行了對比,得出雙流特徵效果比光流和C3D好;對單元水平和幀級迴歸做了對比,證明單元水平的效果好一些;網路還對每一階段級聯級數做了實驗,證明2-3級的proposal網路和2級的分類網路效果更好。
該文章在THUMOS2014上IOU=0.5時MAP=31.0%,是2017年該資料集最好的效果。
7.R-C3D(R-C3D: Region Convolutional 3D Network for Temporal Activity Detection):
之前的方法有些用滑窗的方法計算量大,預測邊界不靈活,很多都不是端到端的學習深層特徵,只在分類網路上學習現成的特徵對定位效果可能不佳。所以本文借鑑目標檢測領域faster-rcnn的思想提出了一個端到端的網路,生成候選段和分類結合在一起學習特徵,用全卷積來學習3D特徵再加上ROI pooling使網路可以接收任意長度輸入,生成候選段的步驟過濾掉了很多背景可以節約計算,而且候選段由預定義的anchor來預測,可以檢測靈活的活動邊界。

網路由三部分組成:特徵抽取網路、時序候選段子網、分類子網。
候選段偏移和類別分數由最後兩個1*1*1的卷積層計算。特徵和損失函式都由兩個子網路共享。
該方法在THUMOS2014資料集上IOU=0.5時的MAP為28.9%。
主要貢獻是提出了一種端到端的網路把定位和分類結合起來一起訓練,可以接受任意長度視訊輸入並且節約了計算。
8.ETP(Precise Temporal Action Localization by Evolving Temporal Proposals):
提出了三階段的evolving temporal proposal網路,引入了非區域性金字塔特徵,該方法是目前在THUMOS2014資料集上效果比較好,IOU=0.5的時候MAP=34.2%。
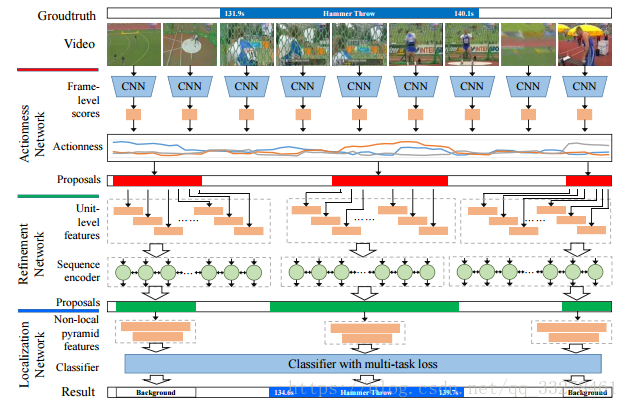
網路分為三個階段:Actionness Network、Refinement Network、Localization Network。
第一個網路運用TAG的方法生成proposal,是一個分類網路。第二個網路在單元水平做進一步調整,同時運用了雙門的RNN更加關注視訊的上下文資訊。最後一個定位網路繼續調整邊界,採用SSN的結構,並在頂層加入了非區域性塊,但是為了防止對網路的影響太大,以殘差連線方式加入,定位網路是一個多工網路,不只要判斷proposal是動作還是背景,還要判斷它是什麼動作,還要調整邊界。
這篇文章在THUMOS2014資料集IOU=0.5時MAP達到34.2%。
主要貢獻是利用RNN更加關注動作的上下文資訊,引入了非區域性特徵,融合了之前一些比較好的方法,達到了目前比較好的效果。
9.Learning Latent Super-Events to Detect Multiple Activities in Videos:
在視訊中學習潛在的超級事件來做多活動檢測。這篇文章關注於更細粒度的檢測,用的資料集是MUTITHUMOS,在THUMOS的基礎上加了一些資料,平均每段視訊內的活動更多。目前的方法基本都更關注候選段的決策,而忽略了整段視訊的時序結構和上下文資訊,連續的視訊中有很多上下文資訊都可以幫助我們做更好的動作檢測。所以本文提出了一個超級事件的概念,與子事件相對應,一個超級事件包含一系列的子事件,是相互關聯的子事件的集合。題目名為潛在的超級事件是因為這些超級事件和子事件的定義是無需標註的。文章還提出了一個時間結構過濾器來學習每類的軟注意力權重從而得到超級事件表現,用它來逐幀分類。
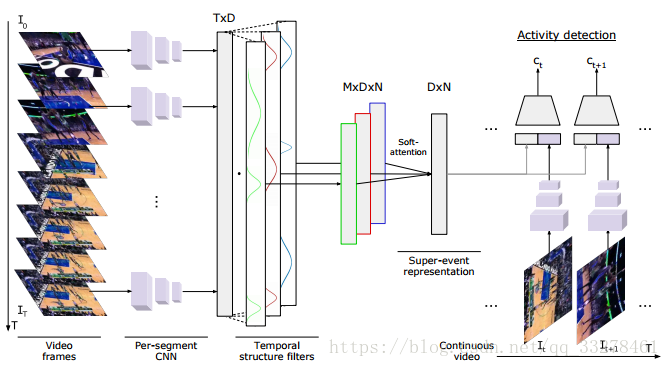
首先將整段視訊輸入網路,對每幀或每個區域性段落學習一個特徵,這裡用到了RNN還用到全卷積的網路來對每幀學習一個類別分數,然後把這些特徵輸入到M個時間結構過濾器裡,時間結構過濾器由若干個柯西分佈組成,它可以讓模型知道哪些時間間隔和幀級檢測相關。
用I3D特徵+超級事件在MUTITHUMOS上MAP為36.4%。
10.CVPR2018-Rethinking the Faster R-CNN Architecture for Temporal Action Localization
之前的R-C3D是直接生硬的遷移faster-rcnn到動作檢測上,有一些問題,主要是因為視訊長度相差很大1s到幾分鐘都有可能。rethinking faster rcnn這篇文章做了一些改進,使之更適應動作檢測:1)感受野對齊,用了空洞卷積2)利用上下文,即動作前後的資訊,類似ssn提到的3)加入光流資訊,並做了個晚融合。
效果超級之好,目前我知道的thumos14最佳,直接從去年IOU=0.5的map31%提高到了42%,參考以下連結文章的詳細描述吧。https://blog.csdn.net/qq_33278461/article/details/81155181