
2017 VQA Challenge 第一名技術報告
作者丨羅若天
學校丨TTIC博士生
研究方向丨NLP,CV
1. 前言
之前聽 Chris Manning 講過一個 talk,說他們復現別人的 paper,按照別人的演算法寫,做到了比原本那篇 paper 高了 10 個點的結果。還有聽認識的同學說,有一年因為演算法的 performance 不夠好論文被拒了,第二年重新回過去跑那個程式碼,隨便調了調,performance 就比當時他們提交的時候高了很多。
我們做玄學的,好的 idea 固然重要,然而一個好的 idea 可能帶來的效果的提升還不如一個好的 trick。當然啦,最好的是 trick 又有效,而且也有一個好的故事。
所以,這裡推薦今年 VQA Challenge 的一篇技術報告,名字叫:
Tips and Tricks for Visual Question Answering
從名字就可以看出來,這篇文章沒有任何新穎的 idea,完全就是工程上的髒活累活,但是將作者試的所有結構都列舉了出來,並做了詳細的 ablation study。
雖然這篇文章中只討論了在 VQA 上的 performance,但是可能這些 trick 也能用到其他多模態的問題上。就算不能用,這篇文章至少也告訴了你,你有哪些東西可以調。
大家可以把這篇稿子當作一篇翻譯稿,我自己也不是做 VQA,所以有些東西可能不是很精準,所以我就按照論文裡怎麼說怎麼來,我就不多做評論了。
PPT(作者獲獎後做的報告):
2. VQA 背景
VQA 全稱是 visual question answering。形式是給一個圖片和一個關於這張圖片的問題,輸出一個答案。

VQA 的挑戰之處在於,這是一個多模態的問題,你需要同時瞭解文字和圖片,並進行推理,來得到最後的答案(如果需要用到 common sense 常識的話就更困難了)。類似的多模態的問題有 image captioning,visual dialog 等等。
3. 資料集
大家比較常用的資料集就是 VQA 這個資料集,來自 Gatech 和微軟;他們在去年釋出了第一個版本。由於這個資料集很新,所以還存在一些問題:你可以用簡單的通過死記硬背來回答對很多問題,獲得 ok 的效果。比如說 yes/no 問題,如果永遠回答 yes,你就能答對大部分。所以這個資料集的答案有一定先驗,不是很平衡。
今年,他們在去年的基礎上,採集了新的資料,釋出了 VQA-v2 的版本,這個版本比之前的版本又大了一倍。一共有 650000 的問題答案對,涉及 120000 幅不同的圖片。
這個新的資料庫主要解決了答案不平衡的問題。對於同一個問題,他們保證,有兩張不同的圖片,使得他們對這個問題的答案是不同的。

在新的 VQA-v2 中,對於 yes/no 問題,yes 和 no 的回答是五五開。
4. VQA 基本建模方法
首先把 VQA 問題看作分類問題。由於 VQA 資料集中的問題大多跟圖片內容有關,所以其實可能的正確答案的個數非常有限,大概在幾百到幾千個。
一般來說,會根據訓練資料集中答案出現的次數,設定一個閾值,只保留出現過一定次數的答案,作為答案的候選選項。然後把這些候選答案當作不同的標籤,這樣的話 VQA 就可以當作一個分類問題。
其次是使用 Joint embedding 方法。就是對於一張圖片,一個問題,我們分別對圖片和問題用神經網路進行 embed,把他們投影到一個共同的“語義”空間中,然後對圖片和問題特徵進行一些操作(比如連線,逐元素相乘啊等等),最後輸入進一個分類網路;
根據訓練集的資料 end-to-end 訓練整個網路。
以下為本文的整體框架:
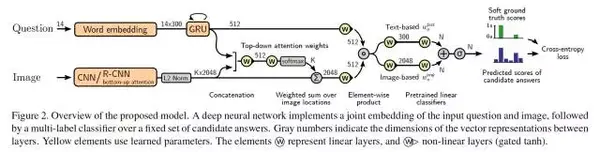
簡而言之,這是一個 joint RNN/CNN embedding 模型,加上一個簡單的問題對圖片的注意力機制。
5. 本文使用的一些 trick 彙總:
· 把 VQA 看成多類別分類(mutli-label clasification)問題,而不是多選一;
· 使用 soft score 作為 label;
· 使用 gated tanh 作為非線性層的 activation;
· 使用了 bottom-up 的圖片特徵;
· 用預訓練的特徵對最後的分類網路進行初始化;
· 訓練時使用大 mini-batch,並在 sample 訓練資料時使用均衡的 sample 方法。
從最簡單的開始介紹:
· 非線性層
文章裡全部是用了gated tanh 作為非線性層。

本質上就是原來的 tanh 激勵上根據獲得的 gate 進行了 mask,其實是跟 LSTM 和 GRU 中間非線性用的是一樣的。
本文中,作者將該層與 tanh 和 ReLU 進行了比較,gated tanh 能獲得更好的結果。但是本文沒有嘗試 Gated CNN 文章中用到的 Gated Linear Layer 進行比較(在 Gated CNN 中,GLU 要比 GTU 更好)。
· 多類別分類
在 VQA-v2 資料集中,由於資料採集自不同的 turker,所以同一張圖片同一個問題可能會有多個答案。在資料集中,每個答案都有 0 到 1 的 accuracy。
基於這樣的事實,本文並沒有像其他論文一樣做多選一的分類問題,而是轉換成了 multi-label 分類問題。原本的 softmax 層被改為了 sigmoid 層。因此,最後的網路輸出給了每個答案一個 0-1 的分數。
由於每個答案的 accuracy 是 0-1,所以本文使用了 soft target score。其中,$s$ 是 ground truth,$\hat s$ 是網路的輸出。
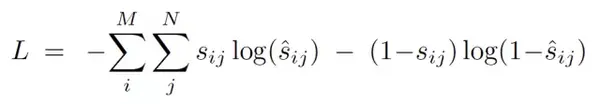
這個公式和普通的二值分類的 binary cross entropy 非常像。事實上,如果 ground truth accuracy 是 0 或者 1 的話,這個公式就等價於 binary cross entropy。
雖然在預處理時,我們根據答案的出現次數濾掉了一些不常見的答案,但是我們仍然會使用這一部分資料,只是認為這個問題所有候選答案的 accuracy 都是 0。
看成多類別分類效果更好的原因有二:首先,sigmoid output 能夠對有多個答案的資料進行訓練;其次,soft target score 提供了更豐富的訓練訊號。
· 分類網路初始化
由於分類網路最後一層是個全連線層,所以最後每個答案的分數就是圖片特徵和問題特徵與網路權重的點積。所以我們可以把最後一層全連線層權重的每一行都是每個答案的特徵,這樣最後的分數其實就是圖片特徵和問題特徵與答案特徵的相似度。
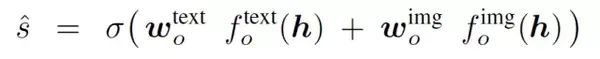
所以 $w_o^\text{text}$ 的每一行通過答案的 glove feature 進行初始化。對 $w_o^\text{img}$,他們使用了 google images。對每個答案,在 google 上進行了搜尋,挑選了 10個 最相關的圖片,計算了 10 張圖片 resnet feature 的平均值,用它做了 $w_o^\text{img}$ 每一行初始化的值。
· 大 minibatch 和均衡 sample
本文他們嘗試了多種 minbatch size 的可能,他們發現,256, 384,512 作為 batch size 效果都不錯,比更多資料或者更少的資料要更好。
均衡 sample 的設計來源於 vqa v2 本身的特性。由於每個問題,都可以找到不同的答案,所以這裡作者強制在同一個 batch 中,每個問題都要出現兩次,並且問題的答案需要是不同的。
· bottom-up image feature
這個 trick 是結果提升最大的來源,本質上,這裡他們使用了一種更強的圖片特徵,所以獲得了最好的結果提升。那篇文章中他們將這影象特徵也用在了 capitoning,獲得了當時 leaderboard 的第一名。
具體方法是,他們用 visual genome 訓練了一個 Faster RCNN,每張圖片的 feature 就是圖片中 top-K 物體的 feature。他們嘗試了對每張圖片固定 K 的值,和根據一個閾值來選擇物體(每張圖片可以有不同的 K)。
跟普通的 resnet 的區別在於,這裡他們是直接對 object 做 attention,而不是圖片中每個方塊區域進行 attention。從直觀的理解來說,這樣的 attention 更加有解釋性。
注意的是,這裡 cnn 沒有進行 finetune,每張圖片的 feature 都是事先已經提取好的了。
這部分在 Visual Genome 上訓練 Faster RCNN 的程式碼已經公佈在 github:

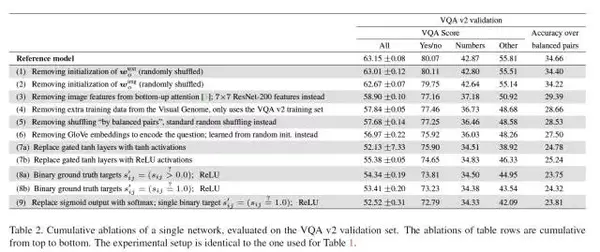
這幾改進對結果的影響可以在此表中展現,可以看到每移除一項變化對結果的影響。
6. 其餘模型細節
文字處理
對於問題,每個問題通過空格和標點分割成一個一個單詞,包括數字組成的單詞也全部當作單獨的一個獨立的單詞。句子被截斷到最多 14 個單詞(因為只有 0.25% 的問題長度大於 14),每個詞的 embedding 長度設為 300。
用 wikipedia/gigaword 上訓練的 pretrained glove 特徵進行初始化,長度小於 14 的句子填補全 0 特徵,word embeedding 送入一個 forward-GRU,hidden size 為 512。他們使用 final state 作為 feature。
他們的句子中沒有包含 start 和 end token,也沒有 dynamic unrolling,每個句子在提取特徵的時候都看作長度 14 的句子。他們發現 recurrent unit 跑相同的 iteration 更加有效(文章中並沒有給出這個部分的 ablation study,筆者:這個其實還挺不常見的) 。
他們也比較了其他演算法:比如說使用不同大小的 word embedding,embedding 隨機初始化,逆序 GRU,雙向 GRU,兩層 GRU,詞包模型;其中單層順序 GRU,300 維 glove 初始化比其他嘗試都要好(實際上詞包模型效果十分接近,這跟 IBOWIMG 的發現是差不多的)。
RNN hidden size
他們也試了不同大小的 hidden state size,最後選用了 512,雖然更大的 hidden state size 有可能獲得更好的結果,但是訓練多次的結果 variance 也會更大。
影象特徵的 l2 norm
文中聲稱影象特徵最好根據 l2 norm 歸一化。雖然文中也沒有給出不歸一化的結果進行比較,但這跟筆者在類似問題上的經驗是一致的。
注意力機制
基本上這個注意力機制和其他的差不多:將 sentence embeeding $q$ 連線到到每個 location 的 image feature,然後通過一個 MLP 獲得每個 location 的分值,然後再通過一個 softmax 獲得 attention map,然後以後的 visual feature 就是每一個 location 的 feature 的加權平均。
這篇文章僅使用了這個最簡單的注意力機制,並沒有與其他更 fancy 的模型進行比較。
Multimodal fusion
這篇文章的 fusion 簡單到爆炸,就是先對視覺特徵和文字特徵通過一個非線性層,然後進行一個 hadamard product,就是逐元素相乘。他們和 concatenation 比較效果要更好(並沒有在文章中的表格中體現)。但他們沒有嘗試其他的 fusion 方式。
這次 vqa 的並列第二名都是對 fusion 層進行改進,包括其實很多最近其他做 vqa 的論文也都是在這個地方改來改去,所以可能如果換成那些效果會更好。
Ensemble
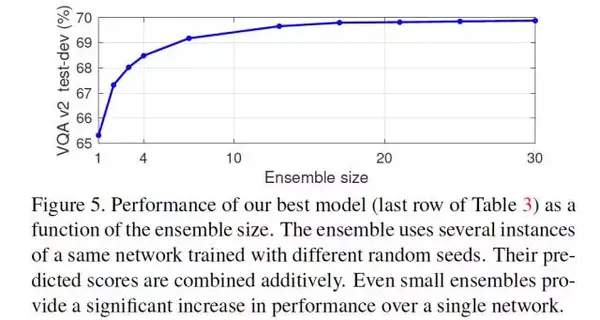
Ensemble 對於結果的提升也是非常大的,下圖表現了 Ensemble 的個數對結果的影響。
額外的訓練資料
他們同時也使用了 visual genome 中的 qa 資料。他們只保留了 visual genome 中答案在候選答案中的問題對作為訓練資料。這對結果有一定的提高(但非常微小)。
如果把答案不在候選答案中的問題,看成全 0 的 label 的話,反而會導致更差的結果。
更難的 evaluation metric
他們不但使用了 VQA 標準的 accruacy 作為 evaluation metric,他們還使用了 Accuracy over pairs。這是平衡問題對(也就是同樣問題,不同答案)都回答準確的比例。他們最後在甄選模型的時候很大程度地考慮了這個新的 metric。
7. 總結
修煉玄學的悲歡,我們這些努力不簡單。
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。
微信公眾號:PaperWeekly
新浪微博:@PaperWeekly