
Saprk基本架構原理簡介
一,簡介
Apache Spark 是專為大規模資料處理而設計的快速通用的計算引擎。Spark是UC Berkeley AMP lab (加州大學伯克利分校的AMP實驗室)所開源的類Hadoop MapReduce的通用並行框架,Spark,擁有Hadoop MapReduce所具有的優點;但不同於MapReduce的是——Job中間輸出結果可以儲存在記憶體中,從而不再需要讀寫HDFS,因此Spark能更好地適用於資料探勘與機器學習等需要迭代的MapReduce的演算法。
Spark 是一種與 Hadoop 相似的開源叢集計算環境,但是兩者之間還存在一些不同之處,這些有用的不同之處使 Spark 在某些工作負載方面表現得更加優越,換句話說,Spark 啟用了記憶體分佈資料集,除了能夠提供互動式查詢外,它還可以優化迭代工作負載。
Spark 是在 Scala 語言中實現的,它將 Scala 用作其應用程式框架。與 Hadoop 不同,Spark 和 Scala 能夠緊密整合,其中的 Scala 可以像操作本地集合物件一樣輕鬆地操作分散式資料集。
儘管建立 Spark 是為了支援分散式資料集上的迭代作業,但是實際上它是對 Hadoop 的補充,可以在 Hadoop 檔案系統中並行執行。通過名為 Mesos 的第三方叢集框架可以支援此行為。Spark 由加州大學伯克利分校 AMP 實驗室 (Algorithms, Machines, and People Lab) 開發,可用來構建大型的、低延遲的資料分析應用程式。
二,spark生態系統
Shark ( Hive on Spark): Shark基本上就是在Spark的框架基礎上提供和Hive一樣的H iveQL命令介面,為了最大程度的保持和Hive的相容性,Shark使用了Hive的API來實現query Parsing和 Logic Plan generation,最後的PhysicalPlan execution階段用Spark代替Hadoop MapReduce。通過配置Shark引數,Shark可以自動在記憶體中快取特定的RDD,實現資料重用,進而加快特定資料集的檢索。同時,Shark通過UDF使用者自定義函式實現特定的資料分析學習演算法,使得SQL資料查詢和運算分析能結合在一起,最大化RDD的重複使用。Spark streaming
Spark Core:包含Spark的基本功能;尤其是定義RDD的API、操作以及這兩者上的動作。其他Spark的庫都是構建在RDD和Spark Core之上的
MLlib:機器學習 MLlib 是Spark 中提供機器學習函式的庫。它是專為在叢集上並行執行的情況而設計的。MLlib 中包含許多機器學習演算法,可以在Spark 支援的所有程式語言中使用,由於Spark基於記憶體計算模型的優勢,非常適合機器學習中出現的多次迭代,避免了操作磁碟和網路的效能損耗。Spark 官網展示的 MLlib 與Hadoop效能對比圖就非常顯著。所以Spark比Hadoop的MapReduce框架更易於支援機器學習。
GraphX:圖形操作 GraphX 是 Spark 中用於圖形和圖形平行計算的新元件。在高層次上, GraphX 通過引入一個新的圖形抽象來擴充套件 Spark RDD :一種具有附加到每個頂點和邊緣的屬性的定向多重圖形。為了支援圖計算,GraphX 公開了一組基本運算子(例如: subgraph ,joinVertices 和 aggregateMessages )以及 Pregel API 的優化變體。此外,GraphX 還包括越來越多的圖形演算法 和 構建器,以簡化圖形分析任務。

三,spark核心概念
RDD:Spark的核心概念是RDD (resilient distributed dataset),指的是一個只讀的,可分割槽的分散式資料集,這個資料集的全部或部分可以快取在記憶體中,在多次計算間重用。RDD--分散式彈性資料集可以把資料集保持在記憶體中,而不是在磁碟中,這樣每次計算只需要從記憶體中讀取資料,而不是通過IO讀取磁碟,跨過了系統IO瓶頸,大大節省了資料傳輸時間.Scala語言的簡潔的特點,所以,Spark非常合適做機器學習的工作中頻繁的迭代計算.RDD可以從本地資料集中通過輸入轉換產生,也可以使用已儲存的RDD,也可以從別的RDD轉換而來,需要使用時,可以把RDD快取在記憶體中(如果記憶體不夠大,會自動儲存到本地).
RDD通過血統來實現容錯機制,每一次轉換,系統會儲存轉換日誌,如果RDD出現故障,系統會根據轉換日誌重建RDD。利用記憶體加快資料載入在眾多的其它的In-Memory類資料庫或Cache類系統中也有實現,Spark的主要區別在於它處理分散式運算環境下的資料容錯性(節點實效/資料丟失)問題時採用的方案。為了保證RDD中資料的魯棒性,RDD資料集通過所謂的血統關係(Lineage)記住了它是如何從其它RDD中演變過來的。
四,spark架構組成與任務排程
架構組成圖

Cluster Manager:在standalone模式中即為Master主節點,控制整個叢集,監控worker。在YARN模式中為資源管理器
Worker節點:從節點,負責控制計算節點,啟動Executor或者Driver。
Driver: 執行Application 的main()函式
Executor:執行器,是為某個Application執行在worker node上的一個程序
資源管理與作業排程
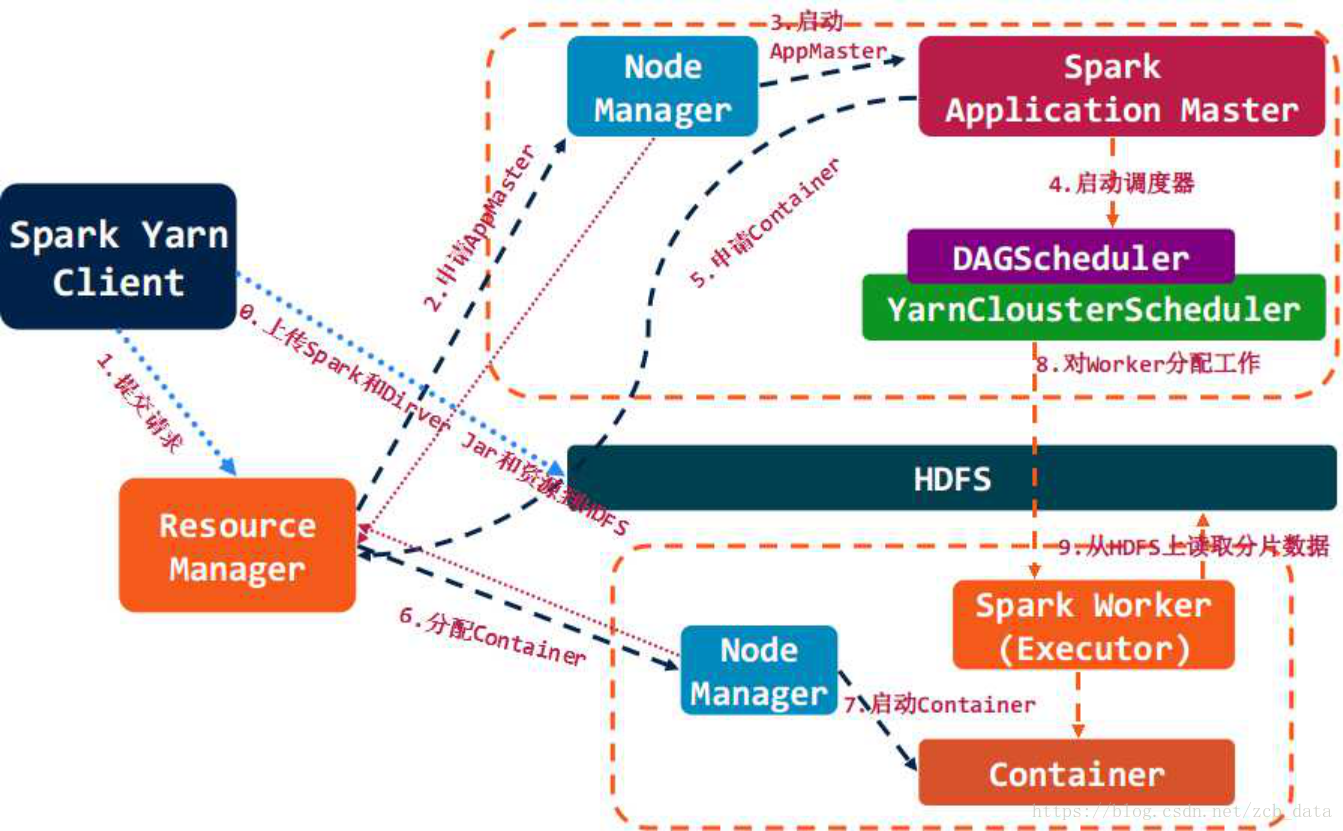
* 構建Spark Application的執行環境,啟動SparkContext
* SparkContext向資源管理器(可以是Standalone,Mesos,Yarn)申請執行Executor資源,並啟動StandaloneExecutorbackend,
* Executor向SparkContext申請Task
* SparkContext將應用程式分發給Executor
* SparkContext構建成DAG圖,將DAG圖分解成Stage、將Taskset傳送給Task Scheduler,最後由Task Scheduler將Task傳送給Executor執行
* Task在Executor上執行,執行完釋放所有資源
五,spark與hadoop的對比
1,Spark的中間資料放到記憶體中,對於迭代運算效率更高:
spark旨在延長MapReduce的迭代演算法,和互動低延遲資料探勘的。 MapReduce和Spark的一個主要區別,MapReduce是非週期性。也就是說,資料流從一個穩定的來源,加工,流出到一個穩定的檔案系統。“Spark允許相同的資料,這將形成一個週期,如果工作是視覺化的迭代計算。
2,Spark比Hadoop更通用:
Spark提供的資料集操作型別有很多種,不像Hadoop只提供了Map和Reduce兩種操作。比如map, filter, flatMap, sample, groupByKey, reduceByKey, union, join, cogroup, mapValues, sort,partionBy等多種操作型別,Spark把這些操作稱為Transformations。同時還提供Count, collect, reduce, lookup, save等多種actions操作。
這些多種多樣的資料集操作型別,給給開發上層應用的使用者提供了方便。各個處理節點之間的通訊模型不再像Hadoop那樣就是唯一的Data Shuffle一種模式。使用者可以命名,物化,控制中間結果的儲存、分割槽等。可以說程式設計模型比Hadoop更靈活。Spark不適用那種非同步細粒度更新狀態的應用,例如web服務的儲存或者是增量的web爬蟲和索引。就是對於那種增量修改的應用模型,當然不適合把大量資料拿到記憶體中了。增量改動完了,也就不用了,不需要迭代了。
3,容錯性:
在分散式資料集計算時通過checkpoint來實現容錯,而checkpoint有兩種方式,一個是checkpoint data,一個是logging the updates。使用者可以控制採用哪種方式來實現容錯。做checkpoint的兩種方式,一個是checkpoint data,一個是logging the updates。貌似Spark採用了後者。但是文中後來又提到,雖然後者看似節省儲存空間。但是由於資料處理模型是類似DAG的操作過程,由於圖中的某個節點出錯,由於lineage chains的依賴複雜性,可能會引起全部計算節點的重新計算,這樣成本也不低。他們後來說,是存資料,還是存更新日誌,做checkpoint還是由使用者說了算吧。相當於什麼都沒說,又把這個皮球踢給了使用者。所以我看就是由使用者根據業務型別,衡量是儲存資料IO和磁碟空間的代價和重新計算的代價,選擇代價較小的一種策略。
4,可用性:
Spark通過提供豐富的Scala, Java,Python API及互動式Shell來提高可用性。
六,spark與hadoop的結合
Spark可以直接對HDFS進行資料的讀寫,同樣支援Spark on YARN。Spark可以與MapReduce運行於同叢集中,共享儲存資源與計算,資料倉庫Shark實現上借用Hive,幾乎與Hive完全相容。
從Hadoop 0.23把MapReduce做成了庫,看出Hadoop的目標是要支援包括MapReduce在內的更多的平行計算模型,比如MPI,Spark等。畢竟現在Hadoop的單節點CPU利用率並不高,那麼假如這種迭代密集型運算是和現有平臺的互補。同時,這對資源排程系統就提出了更高的要求。有關資源排程方面,UC Berkeley貌似也在做一個Mesos的東西,還用了Linux container,統一排程Hadoop和其他應用模型。