
使用EM演算法對含有缺失資料的聯合泊松分佈的引數進行極大似然估計
阿新 • • 發佈:2019-01-02
本文是對《ML estimation in the bivariate passion distribution in the presence of missing values via the em algorithm》K.Adamids & S.Loukas (1994)的研究總結。
前一段時間研究了含有缺失資料的聯合正態分佈引數的估計,應該說,對於連續性假設的研究是不夠完整的,最近開始研究一種離散分佈假設-聯合泊松分佈的引數估計方法,儘管在現實生活中很難找到服從聯合泊松分佈的案例,然而對於理論完整性的研究仍然是有必要的。
EM演算法在很早的研究中就被用來作為一種估計含有潛變數引數的有效方法,典型的應用如混合高斯分佈模型。然而,不同的分佈潛變數的定義有所不同,以本文為例,聯合泊松分佈定義為:
假定X’, Y’, U 是各自服從引數為a,b,d的獨立泊松隨機變數,並且滿足:
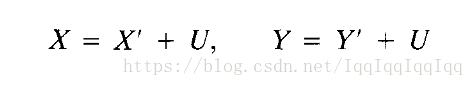
並且
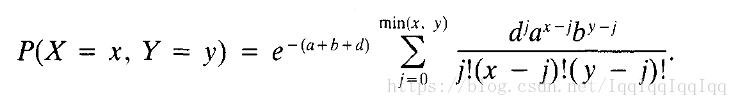
在E步:
假設
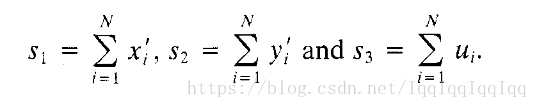
滿足
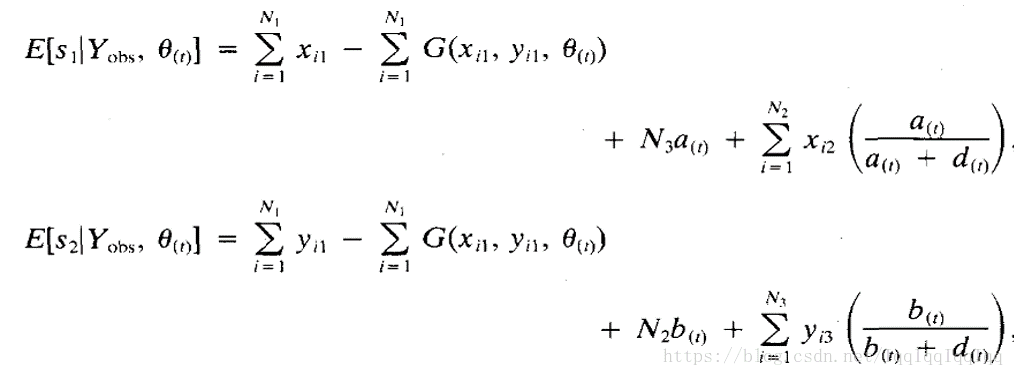
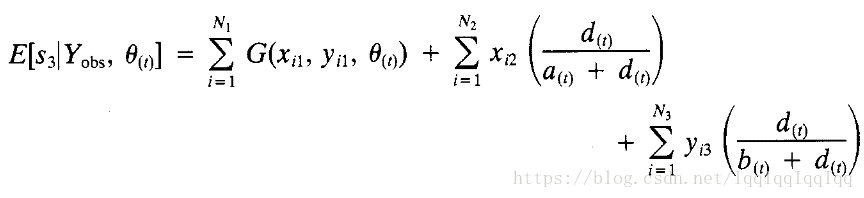
那麼
在M步,我們可以通過求解下面概率密度函式的極大似然估計:
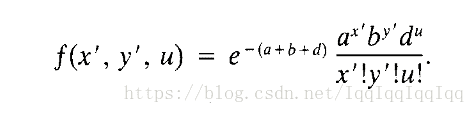
得到
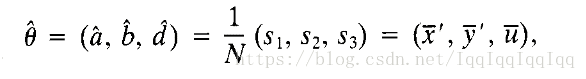
根據估計的無偏性,可以得到:
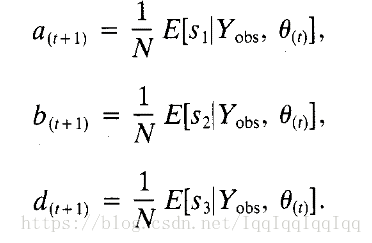
因此我們只需要為a,b,d設定一個初始值,帶入E步的等式中可以得到s1,s2,s3的期望,然後帶入M步,更新三個引數的值。如此迭代,直到收斂。
假定a=b=2,d=1,通過實驗,我們可以得到
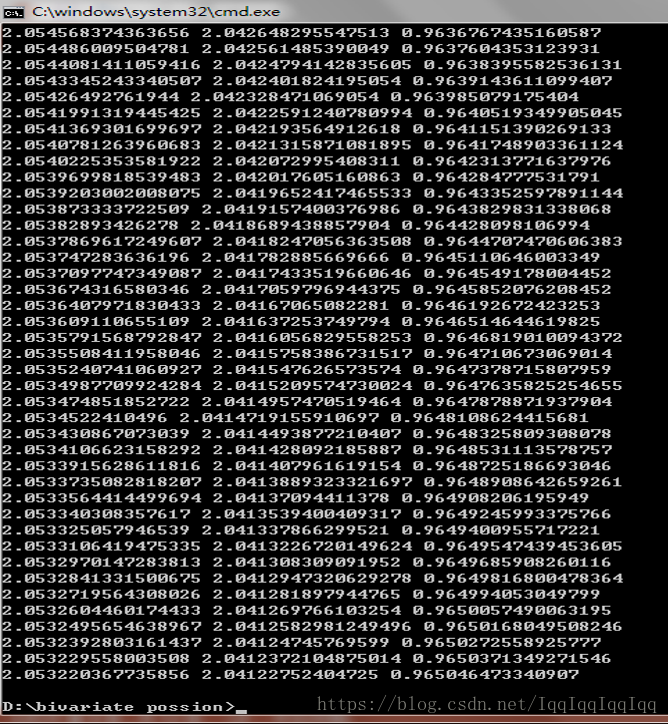
以e-5作為收斂條件,可見,最後得到的估計結果a=2.053,b=041,c=0.965,與原始值還是很接近的。