
快排及優化
什麼是快速排序
快速排序簡介
快速排序(英文名:Quicksort,有時候也叫做劃分交換排序)是一個高效的排序演算法,由Tony Hoare在1959年發明(1961年公佈)。當情況良好時,它可以比主要競爭對手的歸併排序和堆排序快上大約兩三倍。這是一個分治演算法,而且它就在原地排序。
所謂原地排序,就是指在原來的資料區域內進行重排,就像插入排序一般。而歸併排序就不一樣,它需要額外的空間來進行歸併排序操作。為了線上性時間與空間內歸併,它不能線上性時間內實現就地排序,原地排序對它來說並不足夠。而快速排序的優點就在於它是原地的,也就是說,它很節省記憶體。
引用一張來自維基百科的能夠非常清晰表示快速排序的示意圖如下:
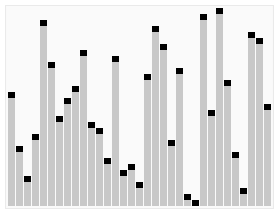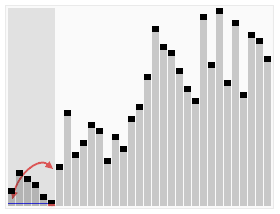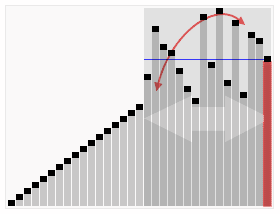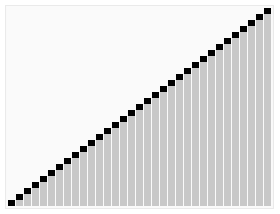
快速排序的分治思想
由於快速排序採用了分治演算法,所以:
一、分解:本質上快速排序把資料劃分成幾份,所以快速排序通過選取一個關鍵資料,再根據它的大小,把原陣列分成兩個子陣列:第一個數組裡的數都比這個主元資料小或等於,而另一個數組裡的數都比這個主元資料要大或等於。
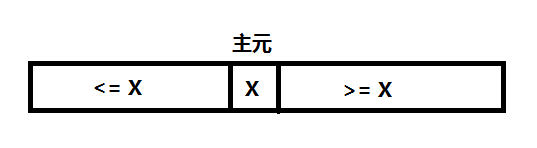
二、解決:用遞迴來處理兩個子陣列的排序。 (也就是說,遞迴地求上面圖示中左半部分,以及遞迴地求上面圖示中右半部分。)
三、合併:因為子陣列都是原址排序,所以不需要合併操作,通過上面兩步後陣列已經排好序了。
所以快速排序的主要思想是遞迴與劃分。
如何劃分
當然最重要的是它的複雜度是線性的,也就是
<code class="hljs autohotkey has-numbering">Partition(<span class="hljs-literal">A</span>,p,q) // <span class="hljs-literal">A</span>[p,..q] <span class="hljs-number">1</span> x=<span class="hljs-literal">A</span>[p] // pivot=<span class="hljs-literal">A</span>[p] 主元 <span class="hljs-number">2</span> i=p <span class="hljs-number">3</span> for j=p+<span class="hljs-number">1</span> to q <span class="hljs-number">4</span> do <span class="hljs-keyword">if</span> <span class="hljs-literal">A</span>[j]<=x <span class="hljs-number">5</span> then i=i+<span class="hljs-number">1</span> <span class="hljs-number">6</span> exch <span class="hljs-literal">A</span>[i]<-><span class="hljs-literal">A</span>[j] <span class="hljs-number">7</span> exch <span class="hljs-literal">A</span>[p]<-><span class="hljs-literal">A</span>[i] <span class="hljs-number">8</span> <span class="hljs-keyword">return</span> i // i pivot </code><ul class="pre-numbering" style="display: block;"><li>1</li><li>2</li><li>3</li><li>4</li><li>5</li><li>6</li><li>7</li><li>8</li><li>9</li></ul>
這就是劃分的虛擬碼,基本的結構就是一個for迴圈語句,中間加上了一個if條件語句,它實現了對子陣列
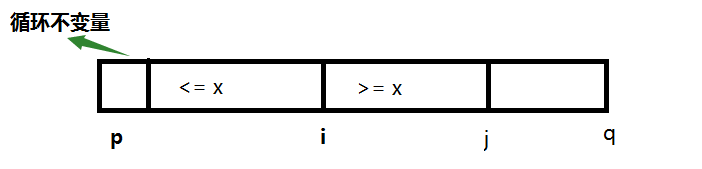
剛開始時
那麼這個演算法在n個數據下的執行時間大約是
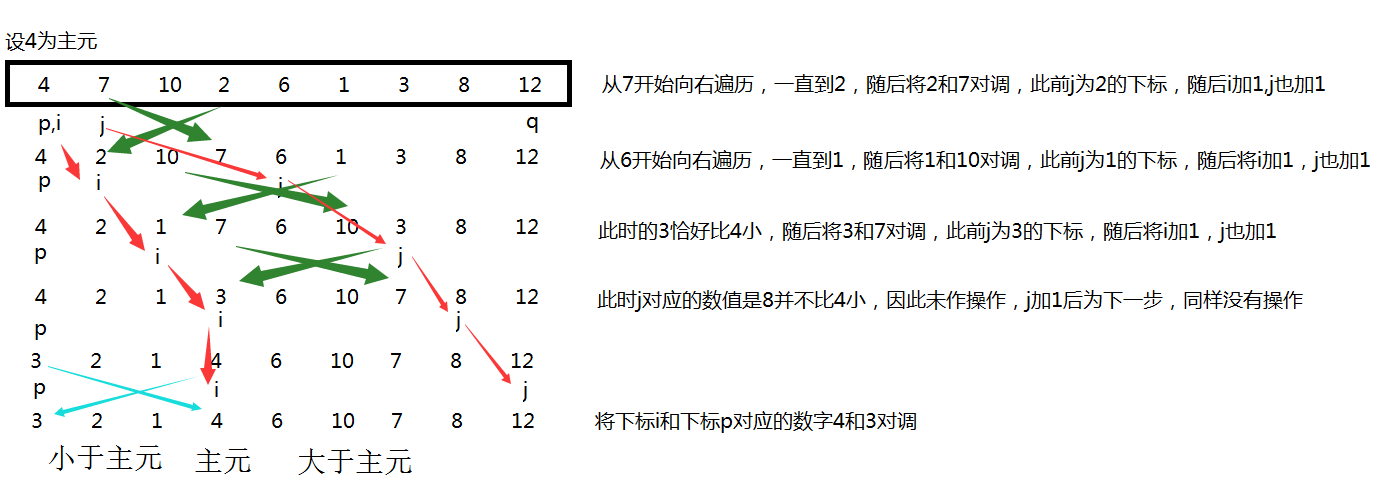
上面這幅圖詳細的描述了Partition過程,每一行後也加了註釋。
將遞迴的思想作用於劃分上
有了上面這些準備工作,再加上分治的思想實現快速排序的虛擬碼也是很簡單的。
<code class="hljs autohotkey has-numbering">Quicksort(<span class="hljs-literal">A</span>,p,q) <span class="hljs-number">1</span> <span class="hljs-keyword">if</span> p<q <span class="hljs-number">2</span> then r=Partition(<span class="hljs-literal">A</span>,p,q) <span class="hljs-number">3</span> Quicksort(<span class="hljs-literal">A</span>,p,r-<span class="hljs-number">1</span>) <span class="hljs-number">4</span> Quicksort(<span class="hljs-literal">A</span>,r+<span class="hljs-number">1</span>,q) </code><ul class="pre-numbering" style="display: block;"><li>1</li><li>2</li><li>3</li><li>4</li><li>5</li></ul>
為了排序一個數組A的全部元素,初始呼叫時
快速排序的演算法分析
相信通過前面的諸多實踐,大家也發現了快速排序的執行時間依賴於Partition過程,也就是依賴於劃分是否平衡,而歸根結底這還是由於輸入的元素決定的。
如果劃分是平衡的,那麼快速排序演算法效能就和歸併排序一樣。
如果劃分是不平衡的,那麼快速排序的效能就接近於插入排序。
怎樣是最壞的劃分
1)輸入的元素已經排序或逆向排序
2)每個劃分的一邊都沒有元素
也就是說當劃分產生的兩個子問題分別包含了n-1個元素和0個元素時,快速排序的最壞情況就發生了。
這是一個等差級數,就和插入排序一樣。它並不比插入排序快,因為當同樣是輸入元素已經逆向排好序時,插入演算法的執行時間為
我們為最壞情況畫一個遞迴樹。
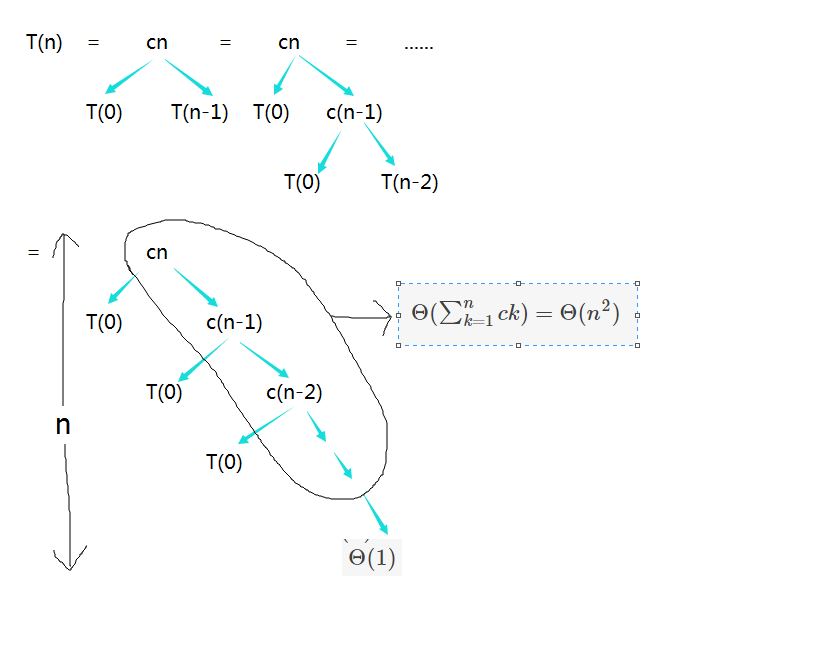
這是一課高度不平衡的遞迴樹,圖中左邊的那些
所以演算法的中執行時間為:
最壞劃分的演算法分析
通過上面的圖示我們知道了在最壞情況下快速排序的複雜度是
當輸入規模為n時,時間
除去主元后,在Partition函式中生成的兩個子問題的規模的和為n-1,所以r的規模才是0到n-1。
假設
1)而
於是有
最終因為我們可以選擇一個足夠大的
什麼是快速排序
快速排序簡介
快速排序(英文名:Quicksort,有時候也叫做劃分交換排序)是一個高效的排序演算法,由Tony Hoare在1959年發明(1961年公佈)。當情況良好時,它可以比主要競爭對手的歸併排序和堆排序快上大約兩三倍。這是一個分治演算法,而且它就在原地排序。
所謂原地排序,
快排(Quicksort)
分治演算法
原地排序(就在原來的資料區域內進行重排,像插入排序,在原來的區域完成排序,歸併排序額外的空間進行排序)
分治
分,快速排序將資料劃分為幾份,所以快排通過選取一個關鍵資料,再根據它的大小把原資料分為兩個子陣列(第一個陣
一.快速排序的基本思想
關於快速排序,它的基本思想就是選取一個基準,一趟排序確定兩個區間,一個區間全部比基準值小,另一個區間全部比基準值大,接著再選取一個基準值來進行排序,以此類推,最後得到一個有序的數列。
二.快速排序的步驟
1.選取基準值,通過不同的
基礎快排:
int __partition(int arr[], int l, int r) {
int v = arr[l];
int j = l ;
for (int i = l + 1; i <= r; i++) {
if (arr[i] < v){
sw
//遞迴法//
#include<stdio.h>
int quicksort(int a[],int left,int right)
{
int i,j,key;
if(left<right)
{
i=left,j
1、快速排序的基本思想:
快速排序使用分治的思想,通過一趟排序將待排序列分割成兩部分,其中一部分記錄的關鍵字均比另一部分記錄的關鍵字小。之後分別對這兩部分記錄繼續進行排序,以達到整個序列有序的目的。
2、快速排序的三個步驟:
(1)選擇基準:在待排序列中,按照某種方式挑出一個元素,作為 “基準”(piv
正常快排
最近在找實習,然而我覺得部落格還是要堅持日更,我相信時間總是擠出來的,不扯淡了,快排這是個面試常考題,今天主要著重於講他的優化方法,那我就直接先貼快排程式碼,再來細細道來我所知道的優化方法,正常的快排,先上圖片後上程式碼,比較容易理解
快速排序
//部分參考維基百科 https://zh.wikipedia.org/wiki/
目錄
快速排序
基本介紹
整體的思路
程式碼實現
第K大數字:
最壞情況優化:
與堆排序、歸併排序的比較
基本介紹
在平均狀況下,排序個 上節介紹瞭如何使用起泡排序的思想對無序表中的記錄按照一定的規則進行排序,本節再介紹一種排序演算法——快速排序演算法(Quick Sort)。
C語言中自帶函式庫中就有快速排序——qsort函式 ,包含在 <stdlib.h> 標頭檔案中。
快速排序演算法是在起泡排序的基礎上進行改進的一種演算
快排的兩種呼叫:
#include<iostream>
#include<cstdio>
#include<cstring>
#include<cstdlib>
#include<algorithm>
using namespac
快速排序過程
基本思想是分治的思想,說到分治,就應該想到和遞迴是分不開的。
有些書上會使用關鍵字比較的表述,有些書上會直接使用記錄比較表述,這兩種說法是兩個維度上的說法。這裡序列元素的關鍵字屬於記錄的一部分,為了簡化問題,本文的討論並不區分關鍵字和記錄,程式
/*
快速排序
基本思想
選定每次排序的基準資料 在剩下的位置將小於基準值的資料放在基準值得左邊,大於基準值的資料放到基準值的右邊
一次劃分之後 如果此基準值的左右兩邊仍存在大於兩個資料 則繼續劃分排序 直至每個數字都有序
遞迴實現Quick_Sort1
think:
1今晚終於AC道題目了…..這道題目感覺和貪心裡面的區間區間覆蓋問題類似,只不過感覺這道題目明顯需要優化子問題,因為有可能出現像【0, 7】,【1, 3】, 【3, 6】這樣的區間,不能因為先出現一個條件判斷了,之前自己做的區間覆蓋問題好像沒有想
排序演算法的穩定性:假定在待排序的記錄序列中,存在多個具有相同的關鍵字的記錄,若經過排序,這些記錄的相對次序保持不變,即在原序列中,ri=rj,且ri在rj之前,
而在排序後的序列中,ri仍在rj之前,則稱這種排序演算法是穩定的;否則稱為不穩定的。
氣泡排序:穩 sta -m 就是 color 基本 結果 num 一次 name 一.Partiton算法
Partiton算法的主要內容就是隨機選出一個數,將這個數作為中間數,將大於它的排在它右邊,小於的排在左邊(無序的)。
1 int partition (int 快排 常用的快排都是用遞歸寫的,因為比較簡單,但是可以用棧來實現非遞歸的快排。第一種是遞歸的快排#include<stdio.h>
#include <stdlib.h>
#include <time.h>
int quick(int a[],int i ,int j ostream stdout ++i rand() oid fclose cnblogs clu 快排 說到快拍,大家都會首先想到sort函數這個神奇的東西
但是,我們總得知道快拍主要用的分治思想
所以就說一說快拍吧
首先是分類
快拍主要有三種方式:
一、以第一個數為基準排 學習 格式 讀取文件 tmc 資料 數值計算 詳解 shc 存儲介質 本節內容
------------------
· Spark為什麽要分區
· Spark分區原則及方法
· Spark分區案例
· 參考 外鍵 更新 控制 指定 復雜 性能比較 多臺 roo 組成 1、mysql的生命周期
①MySql服務器監聽3306端口
②驗證訪問用戶
③創建mysql線程
④檢查內存(Qcache)
⑤解析sql
⑥生成查詢計劃
⑦打開表
⑧檢查內存(Buffer Pool)
⑨到磁盤 kibana5.2.2 elasticsearch5.2.2 elk5.2.2 elkb5.2.2.2 ELKB5.2.2集群環境部署本人陸陸續續接觸了ELK的1.4,2.0,2.4,5.0,5.2版本,可以說前面使用當中一直沒有太多感觸,最近使用5.2才慢慢有了點感覺,可見認知事務的艱難,本 相關推薦
快排及優化
【4】快排及隨機化演算法
快速排序的三種方式以及快排的優化
經典排序之快排及其優化
手寫快排及心得
快排的優化策略(3種快排4種優化)
快排演算法及常見兩種常見優化方法
快速排序相關——基本快排實現,優化,第K大數
快速排序演算法(QSort,快排)及C語言實現
快排呼叫及結構體排序
快速排序過程、partition應用、三種快排四種優化、Java實現
快排三種基本解法以及兩種快排優化
今年暑假不AC——(優化貪心+快排)
Java實現的排序演算法及比較 [冒泡,選擇,插入,歸併,希爾,快排]
回憶Partition算法及利用Partition進行快排
快排的遞歸和非遞歸
【分治】簡單說說快排
【Spark 深入學習-08】說說Spark分區原理及優化方法
MySql:監控及優化
ELKB5.2.2集群環境部署及優化終極文檔