機器學習之初識SVM
本文轉載自知乎問題
支援向量機(Support Vector Machine)是Cortes和Vapnik於1995年首先提出的,它在解決小樣本、非線性及高維模式識別中表現出許多特有的優勢,並能夠推廣應用到函式擬合等其他機器學習問題中。
支援向量機方法是建立在統計學習理論的VC維理論和結構風險最小原理基礎上的,根據有限的樣本資訊在模型的複雜性(即對特定訓練樣本的學習精度,Accuracy)和學習能力(即無錯誤地識別任意樣本的能力)之間尋求最佳折衷,以期獲得最好的推廣能力(或稱泛化能力)。
以上是經常被有關SVM 的學術文獻引用的介紹,有點八股,我來逐一分解並解釋一下。
Vapnik是統計機器學習的大牛,這想必都不用說,他出版的《Statistical Learning Theory》是一本完整闡述統計機器學習思想的名著。在該書中詳細的論證了統計機器學習之所以區別於傳統機器學習的本質,就在於統計機器學習能夠精確的給出學習效果,能夠解答需要的樣本數等等一系列問題。與統計機器學習的精密思維相比,傳統的機器學習基本上屬於摸著石頭過河,用傳統的機器學習方法構造分類系統完全成了一種技巧,一個人做的結果可能很好,另一個人差不多的方法做出來卻很差,缺乏指導和原則。
所謂VC維是對函式類的一種度量,可以簡單的理解為問題的複雜程度,VC維越高,一個問題就越複雜。正是因為SVM關注的是VC維,後面我們可以看到,SVM解決問題的時候,和樣本的維數是無關的(甚至樣本是上萬維的都可以,這使得SVM很適合用來解決文字分類的問題,當然,有這樣的能力也因為引入了核函式)。
結構風險最小聽上去文縐縐,其實說的也無非是下面這回事。
機器學習本質上就是一種對問題真實模型的逼近(我們選擇一個我們認為比較好的近似模型,這個近似模型就叫做一個假設),但毫無疑問,真實模型一定是不知道的(如果知道了,我們幹嗎還要機器學習?直接用真實模型解決問題不就可以了?對吧,哈哈)既然真實模型不知道,那麼我們選擇的假設與問題真實解之間究竟有多大差距,我們就沒法得知。比如說我們認為宇宙誕生於150億年前的一場大爆炸,這個假設能夠描述很多我們觀察到的現象,但它與真實的宇宙模型之間還相差多少?誰也說不清,因為我們壓根就不知道真實的宇宙模型到底是什麼。
這個與問題真實解之間的誤差,就叫做風險(更嚴格的說,誤差的累積叫做風險)。我們選擇了一個假設之後(更直觀點說,我們得到了一個分類器以後),真實誤差無從得知,但我們可以用某些可以掌握的量來逼近它。最直觀的想法就是使用分類器在樣本資料上的分類的結果與真實結果(因為樣本是已經標註過的資料,是準確的資料)之間的差值來表示。這個差值叫做經驗風險Remp(w)。以前的機器學習方法都把經驗風險最小化作為努力的目標,但後來發現很多分類函式能夠在樣本集上輕易達到100%的正確率,在真實分類時卻一塌糊塗(即所謂的推廣能力差,或泛化能力差)。此時的情況便是選擇了一個足夠複雜的分類函式(它的VC維很高),能夠精確的記住每一個樣本,但對樣本之外的資料一律分類錯誤。回頭看看經驗風險最小化原則我們就會發現,此原則適用的大前提是經驗風險要確實能夠逼近真實風險才行(行話叫一致),但實際上能逼近麼?答案是不能,因為樣本數相對於現實世界要分類的文字數來說簡直九牛一毛,經驗風險最小化原則只在這佔很小比例的樣本上做到沒有誤差,當然不能保證在更大比例的真實文字上也沒有誤差。
統計學習因此而引入了泛化誤差界的概念,就是指真實風險應該由兩部分內容刻畫,一是經驗風險,代表了分類器在給定樣本上的誤差;二是置信風險,代表了我們在多大程度上可以信任分類器在未知文字上分類的結果。很顯然,第二部分是沒有辦法精確計算的,因此只能給出一個估計的區間,也使得整個誤差只能計算上界,而無法計算準確的值(所以叫做泛化誤差界,而不叫泛化誤差)。
置信風險與兩個量有關,一是樣本數量,顯然給定的樣本數量越大,我們的學習結果越有可能正確,此時置信風險越小;二是分類函式的VC維,顯然VC維越大,推廣能力越差,置信風險會變大。
泛化誤差界的公式為:
公式中R(w)就是真實風險,Remp(w)就是經驗風險,Ф(n/h)就是置信風險。統計學習的目標從經驗風險最小化變為了尋求經驗風險與置信風險的和最小,即結構風險最小。
SVM正是這樣一種努力最小化結構風險的演算法。SVM其他的特點就比較容易理解了。
小樣本,並不是說樣本的絕對數量少(實際上,對任何演算法來說,更多的樣本幾乎總是能帶來更好的效果),而是說與問題的複雜度比起來,SVM演算法要求的樣本數是相對比較少的。
非線性,是指SVM擅長應付樣本資料線性不可分的情況,主要通過鬆弛變數(也有人叫懲罰變數)和核函式技術來實現,這一部分是SVM的精髓,以後會詳細討論。多說一句,關於文字分類這個問題究竟是不是線性可分的,尚沒有定論,因此不能簡單的認為它是線性可分的而作簡化處理,在水落石出之前,只好先當它是線性不可分的(反正線性可分也不過是線性不可分的一種特例而已,我們向來不怕方法過於通用)。
高維模式識別是指樣本維數很高,例如文字的向量表示,如果沒有經過另一系列文章(《文字分類入門》)中提到過的降維處理,出現幾萬維的情況很正常,其他演算法基本就沒有能力應付了,SVM卻可以,主要是因為SVM 產生的分類器很簡潔,用到的樣本資訊很少(僅僅用到那些稱之為“支援向量”的樣本,此為後話),使得即使樣本維數很高,也不會給儲存和計算帶來大麻煩(相對照而言,kNN演算法在分類時就要用到所有樣本,樣本數巨大,每個樣本維數再一高,這日子就沒法過了……)。
通過下面的例子,你也許更能理解SVM方法。
故事是這樣子的:
在很久以前的情人節,大俠要去救他的愛人,但魔鬼和他玩了一個遊戲。
魔鬼在桌子上似乎有規律放了兩種顏色的球,說:“你用一根棍分開它們?要求:儘量在放更多球之後,仍然適用。”
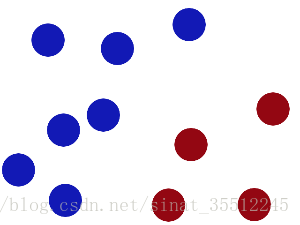
於是大俠這樣放,乾的不錯?
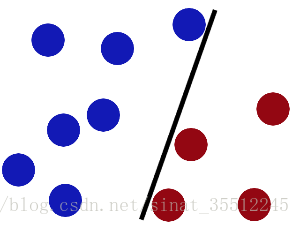
然後魔鬼,又在桌上放了更多的球,似乎有一個球站錯了陣營。
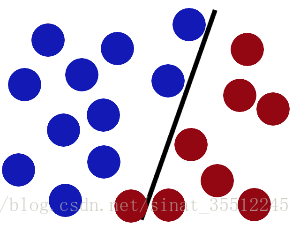
SVM就是試圖把棍放在最佳位置,好讓在棍的兩邊有儘可能大的間隙。
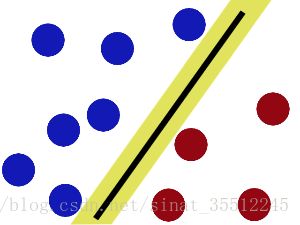
現在即使魔鬼放了更多的球,棍仍然是一個好的分界線。
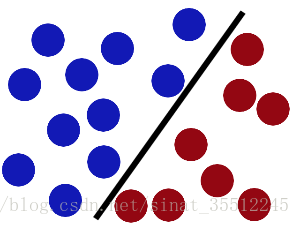
然後,在SVM 工具箱中有另一個更加重要的 trick。 魔鬼看到大俠已經學會了一個trick,於是魔鬼給了大俠一個新的挑戰。

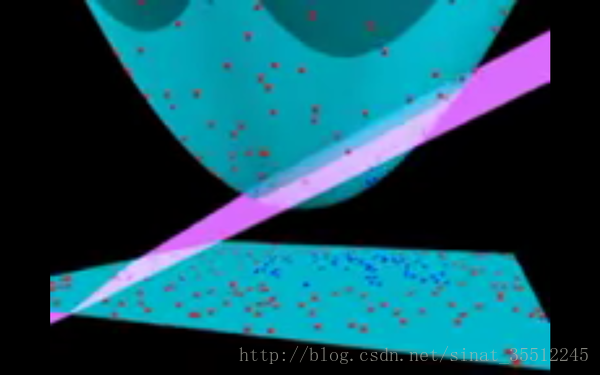
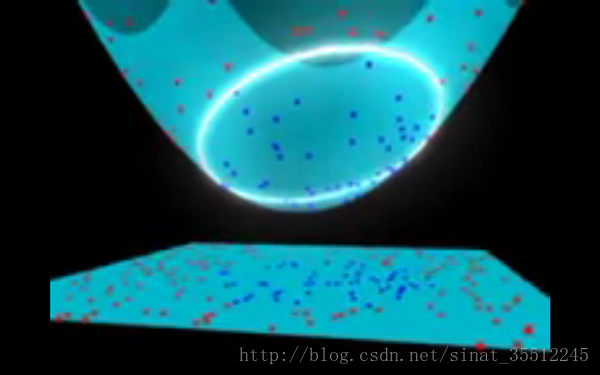
現在,大俠沒有棍可以很好幫他分開兩種球了,現在怎麼辦呢?當然像所有武俠片中一樣大俠桌子一拍,球飛到空中。然後,憑藉大俠的輕功,大俠抓起一張紙,插到了兩種球的中間。
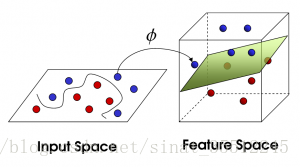
現在,從魔鬼的角度看這些球,這些球看起來像是被一條曲線分開了。
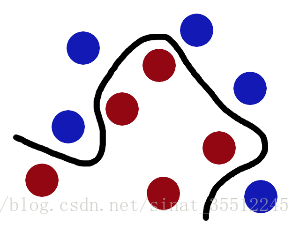
再之後,無聊的大人們,把這些球叫做 「data」,把棍子叫做 「classifier」, 最大間隙trick叫做「optimization」, 拍桌子叫做「kernelling」, 那張紙叫做「hyperplane」。
下面是一個視訊截圖: