
YOLOv2論文理解
YOLO9000:Better, Faster, Stronger
論文YOLO9000: Better, Faster, Stronger的主要內容有三點:
1、作者提出了YOLOv2。
YOLOv2在YOLOv1的基礎上,使用新的網路結構(darknet19)和技巧(Batch Normalization、High Resolution Classifier、Convolutional With Anchor Boxes等),提高了檢測速度和檢測精度。
2、作者提出了一種聯合訓練方法,可以同時使用檢測資料集和分類資料集來訓練檢測模型,用分層的觀點對物體分類,用檢測資料集學習準確預測物體的位置,用分類資料集來增加可識別的類別量,提升魯棒性。
3、作者基於YOLOv2提出了YOLO9000,可以實時檢測九千多種物體。
我參考論文和程式碼進行了實驗,YOLOv2相對於YOLOv1有很明顯的提升,但是YOLO9000使用感受並不好。YOLO9000的主要問題在於很難調整合適的分層閾值,同時很多物體的檢測精度過低。
由於工作和學習中對YOLOv2的研究比較多,對YOLO9000的研究並不深入,所以本文僅記錄對YOLOv2的理解。
Better
YOLO相較於其他的state-of-the-art的檢測系統有一些缺陷,主要表現在兩點:
1、和Fast R-CNN相比,YOLO會產生較多的bounding boxes的定位錯誤。
2、和基於region proposal的檢測系統相比,YOLO的Recall較低。
機器視覺的發展有著神經網路越來越大、越來越深的趨勢。現在的檢測系統,更好的檢測效能往往伴隨著更大的神經網路或者是多個檢測模型的整合。YOLO的目標是高精度實時檢測,所以期望在不增大網路、精度不下降的前提下來對定位錯誤和低Recall進行改善,為此作者嘗試了一系列方法(如圖所示)。

Batch Normalization
BN在消除對其他正則項依賴的同時,在幫助模型收斂方面有顯著作用。通過對每個卷積層新增BN,YOLO的mAP有了2%的提升。BN對模型的泛化很有幫助,加入BN後,去掉了dropout模型依舊沒有過擬合。
High Resolution Classifier
所有state-of-the-art的檢測方法都在ImageNet上對分類器進行了預訓練。從AlexNet開始,多數分類器都把輸入影象resize到256 * 256以下,這會容易丟失一些小物體的資訊。
YOLOv1先使用224 * 224的解析度來訓練分類網路,在訓練檢測網路的時候再切換到448 * 448的解析度,這意味著YOLOv1的卷積層要重新適應新的分辨率同時YOLOv1的網路還要學習檢測網路。
現在,YOLOv2直接使用448 * 448的解析度來fine tune分類網路,好讓網路可以調整filters來適應高解析度。然後再用這個結果來fine tune檢測網路。
使用高解析度的分類網路提升了將近4%的mAP。
Convolutional With Anchor Boxes
YOLOv1使用卷積層之後的全連線層來直接預測bounding boxes的座標。Faster R-CNN的做法和YOLO不同,使用精心挑選的anchor boxes來預測bounding boxes的座標。Faster R-CNN的region proposal network(RPN)使用全卷積網路來預測相對anchor boxes的offsets和confidences。因為預測層是個卷積層,RPN在一個特徵圖上預測所有bounding boxes的offsets。和直接預測座標相比,預測offsets簡化了問題,而且網路更容易學習。
YOLOv2去掉了全連線層,使用anchor boxes預測bounding boxes。
YOLOv2一個池化層,使得卷積層的輸出有更高的解析度。
YOLOv2將輸入影象的尺寸從448 * 448縮減到416 * 416,這樣特徵圖的輸出就是一個奇數,有一箇中心柵格。作者觀察到,有很多物體,尤其是較大的物體往往會位於影象的中心。有一箇中心柵格的話可以用中心柵格專門去負責預測這些中心落在影象中心附近的物體,而不需要影象中心附近的4個柵格去預測這些物體。YOLOv2對影象進行了32倍的降取樣,最終輸出的特徵圖尺寸是13 * 13。
使用anchor boxes預測座標的同時,YOLOv2還對對conditional class probability的預測機制和空間位置(柵格)做了解耦。
在YOLOv1將輸入影象劃分為S*S的柵格,每一個柵格預測B個bounding boxes,以及這些bounding boxes的confidence scores。
每一個柵格還要預測C個 conditional class probability(條件類別概率):Pr(Classi|Object)。即在一個柵格包含一個Object的前提下,它屬於某個類的概率。且每個柵格預測一組(C個)類概率,而不考慮框B的數量。
YOLOv2不再由柵格去預測條件類別概率,而由Bounding boxes去預測。在YOLOv1中每個柵格只有1組條件類別概率,而在YOLOv2中,因為每個柵格有B個bounding boxes,所以有B組條件類別概率。
在YOLOv1中輸出的維度為S * S * (B * 5 + C ),而YOLOv2為S * S * (B * (5 + C))。

使用anchor boxes, 模型的的精度有一點點下降,但是Recall有大幅上升。沒有anchor box,我們的中間模型的mAP為69.5,Recall為81%。使用anchor boxes 模型的mAP為69.2,Recall為88%。儘管mAP有輕微的下降,但是Recall的增加意味著模型有更多的改進空間。
Dimension Clusters
嘗試在YOLO中使用anchor boxes的過程中遇到了兩個問題,第一個問題是如何選擇anchor boxes。Faster R-CNN的anchor boxes是手工精心挑選的,但未必是最好的。雖然神經網路在訓練過程中會逐漸學著調整預測的bounding boxes,讓預測更合理,但有好的anchor boxes幫助可以神經網路讓預測更簡單。
機器學習的本質是學習資料中的概率分佈,手工挑選的anchor boxes未必很好的符合訓練集ROI的概率分佈,使用K-means從訓練集中聚類得到的anchor boxes可能更好。
YOLOv2中的anchor boxes是通過k-means在訓練集中學得的。值得注意的是,因為使用歐氏距離會讓大的bounding boxes比小的bounding boxes產生更多的error,而我們希望能通過anchor boxes獲得好的IOU scores,並且IOU scores是與box的尺寸無關的。
為此作者定義了新的距離公式:
作者使用了一系列k的值執行k-means,並畫出了平均IOU,如圖所示:

和使用手工挑選的anchor boxes相比,使用K-means得到的anchor boxes表現更好。使用5個k-means得到的anchor boxes的效能(IOU 61.0)和使用9個手工挑選的anchor boxes的效能(IOU 60.9)相當。這意味著使用k-means獲取anchor boxes來預測bounding boxes讓模型更容易學習如何預測bounding boxes。

Direct location prediction
嘗試在YOLO中使用anchor boxes的過程中遇到的第二個問題就是模型變得不穩定,尤其是在訓練的早期迭代。不穩定的主要因素來自對bounding box中心座標x,y的預測。在RPN中,網路預測出偏移量
論文中的該公式可能有誤,參考Faster R-CNN的論文,公式應為:
公式中
由於模型是隨機初始化的,要花很長時間去訓練,引數才能調整到能夠很敏感的預測offset。因此YOLOv2不預測offset,而是延續YOLOv1預測bounding boxes相對柵格左上角的座標(相對柵格邊長的比例)。為了確保bounding boxes的中心落在柵格中(即座標落在0到1之間),作者使用了logistic啟用函式來約束預測值。
YOLOv2網路為每個柵格預測5個bounding boxes(對應5個anchor boxes),每個bounding box預測5個座標
置信分的計算公式為:


約束了位置預測的範圍後,網路引數變得更容易學習,網路變得穩定。和使用手選的anchor boxes預測offset相比,使用k-means得到的anchor boxes直接預測相對柵格的座標,mAP提升了將近5%。
Fine-Grained Features
YOLOv2在卷積層輸出的13 * 13特徵圖上進行檢測,這對於大的物體是足夠的,但是更細粒度的特徵可以幫助模型定位較小的目標。Faster R-CNN和SSD在一系列尺寸不同的特徵圖上執行RPN來獲取不同分別率的資訊。YOLOv2採取不同的方法,通過新增一個passthrough layer,將前一個卷積塊26 * 26解析度的特徵圖的資訊融合起來。
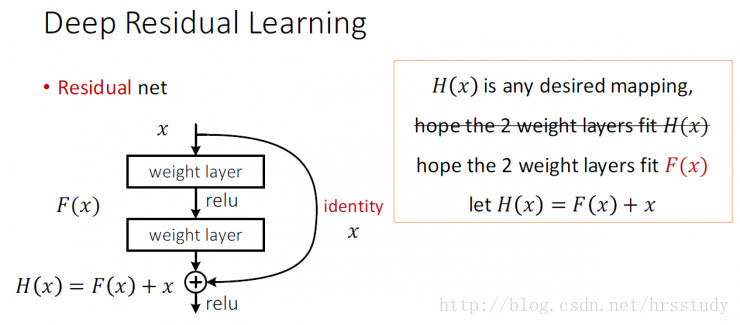
類似於ResNet的Identity Mapping,passthrough layer層通過將相鄰特徵堆疊到不同的通道,將較高解析度特徵與低解析度特徵的資訊融合。這使得26×26×512的特徵圖轉換為與原始特徵相連線的13×13×2048的特徵圖。YOLOv2的檢測器在這個擴充套件的特徵圖的頂部執行,以便利用細粒度的特徵。這提高了將近1%的效能。
Multi-Scale Training
YOLOv1網路使用448 * 448的影象作為輸入,YOLOv2加入anchor boxes後,輸入影象的尺寸變成了416 * 416。YOLOv2網路只用到了卷積層和池化層,因此可以進行動態調整輸入影象的尺寸。作者希望YOLOv2對於不同尺寸影象的檢測都有較好的魯棒性,因此做了針對性訓練。
和YOLOv1訓練時網路輸入的影象尺寸固定不變不同,YOLOv2(在cfg檔案中random=1時)每隔幾次迭代後就會微調網路的輸入尺寸。訓練時每迭代10次,就會隨機選擇新的輸入影象尺寸。因為YOLOv2的網路使用的downsamples倍率為32,所以使用32的倍數調整輸入影象尺寸{320,352,…,608}。訓練使用的最小的影象尺寸為320 * 320,最大的影象尺寸為608 * 608。
這種策略讓YOLOv2網路不得不學著對不同尺寸的影象輸入都要預測得很好,這意味著同一個網路可以勝任不同解析度的檢測任務,在網路訓練好之後,在使用時只需要根據需求,修改cfg檔案中的網路輸入影象尺寸(width和height的值)即可。
YOLOv2在檢測速度和精度上達到了很好的平衡。
YOLOv2在檢測低解析度的影象時,精度較低但速度非常快。在輸入尺寸為228 * 228的時候,檢測幀率達到90FPS,而mAP幾乎和Faster R-CNN的水準相同。使意味著YOLOv2在低效能GPU、高幀率視訊、多媒體視訊流場景中更加適用。
在檢測大尺寸影象檢測中,YOLOv2不僅依然保持著實時檢測,精度也很高,如在VOC2007 上mAP為78.6%。和其他檢測系統的效能對比見下面幾張圖:
VOC2007


VOC2012

COCO2015

Faster
YOLO設計的初衷是兼得速度和精度,達到實時檢測。YOLOv2不僅提高了精度,通過設計新的網路結構,檢測速度也有提升。
Darknet-19
多數的檢測系統使用VGG-16作為基礎特徵提取器。VGG-16是一個高精度的有效的分類網路,但是有些過於複雜。VGG-16的卷積層對一張224 * 224 的影象做一次前傳計算要做306.9億次浮點數運算。
YOLOv1使用的網路是基於GoogleNet的。該網路比VGG-16快,對一張224 * 224 的影象做一次前傳計算要做85.2億次浮點數運算,但是精度比VGG-16略低。VGG-16在ImageNet上的Top-5精度為90.0%,YOLOv1的定製網路精度為88.0%。
YOLOv2的分類網路叫做Darknet-19,Darknet-19對一張224 * 224 的影象做一次前傳計算要做55.8億次浮點數運算,在ImageNet上的Top-5精度為91.2%,比YOLOv1更快,比VGG-16更高。
Darknet-19的網路結構如圖:

類似VGG網路,Darknet-19中使用了較多的3 * 3卷積核,在每一次池化操作後把通道數翻倍。
Darknet-19也借鑑了Network in Network的思想,使用了全域性平均池化(global average pooling),還把1 * 1的卷積核置於3 * 3的卷積核之間,用來壓縮特徵。
同時,Darknet-19還用了batch normalization穩定模型訓練,加速收斂並泛化模型。
Training for classification
作者使用Darknet-19在標準的ImageNet1000類分類資料集上訓練了160個迭代,用的隨機梯度下降演算法,初始學習率為0.1,polynomial rate decay 為4,weight decay為0.0005 ,momentum 為0.9。訓練時用了很多常見的資料擴充方法(data augmentation),包括random crops, rotations, and hue, saturation, and exposure shifts。
初始訓練時網路的輸入是224 * 224,160個迭代後輸入的解析度切換到448 * 448進行fine tune,fine tune時學習率調整為0.001,訓練10個迭代。最終分類網路在ImageNet上top-1準確率76.5%,top-5準確率93.3%。
Training for detection
訓練檢測網路時去掉了分類網路的網路最後一個卷積層,在後面增加了三個卷積核尺寸為3 * 3,卷積核數量為1024的卷積層,並在這三個卷積層的最後一層後面跟一個卷積核尺寸為1 * 1的卷積層,卷積核數量是(B * (5 + C))。
對於VOC資料集,卷積層輸入影象尺寸為416 * 416時最終輸出是13 * 13個柵格,每個柵格預測5種boxes大小,每個box包含5個座標值和20個條件類別概率,所以輸出維度是13 * 13 * 5 * (5+20)= 13 * 13 * 125。
檢測網路加入了passthrough layer,從最後一個輸出為26 * 26 * 512的卷積層連線到新加入的三個卷積核尺寸為3 * 3的卷積層的第二層,使模型有了細粒度特徵。
從yolo-voc.cfg檔案可以看到,第25層為route層,逆向9層拿到第16層26 * 26 * 512的輸出,並由第26層的reorg層把26 * 26 * 512 變形為13 * 13 * 2048,再有第27層的route層連線24層和26層的輸出,堆疊為13 * 13 * 3072,由最後一個卷積核為3 * 3的卷積層進行跨通道的資訊融合並把通道降維為1024。
如圖所示:

作者訓練檢測網路時以0.001的初始學習率訓練了160個迭代,在60次和90次迭代的時候,學習率減為原來的十分之一。weight decay為0.0005,momentum為0.9,使用了類似於Faster-RCNN和SSD的資料擴充(data augmentation)方法。