
System Design: Web Crawler
資料整理來源:
- https://www.jiuzhang.com/qa/871/
- https://zhuanlan.zhihu.com/p/20821699
Crawler實質是一個BFS的過程。從某個網站的主頁開始作為起點,進行BFS。對每一個頁面含有的URL都放入隊列當中。再進行迭代。
我們可以把整個過程抽象成為一幅有向圖的BFS。但是,爬蟲可以在BFS的基礎上產生更多的問題。比如,每個頁面還有很多的URL,但是否每個URL都那麼重要?是否應該先遍歷重要的URL?
如果頁面更新了怎麼辦呢?
再比如,為了加速爬蟲,使用了多執行緒甚至分散式去爬取,怎麼協調?
下面我將一個一個問題進行闡述及提出可能的思路:
對於URL分權重問題,我們可以使用PriorityQueue的大根堆作為BFS的佇列buffer,根據頁面的權重進行排序。優先抓取權重較高的網頁。對於權重的設定,考慮的因素有:連結長度或者如同PageRank演算法一樣通過引用數(link到該網頁的網頁的權重以及該網頁被指向的次數)來確定一個URL 的重要程度。關於PageRank的介紹詳情可以看:
https://blog.csdn.net/rubinorth/article/details/52215036#6-pagerank%E7%AE%97%E6%B3%95%E7%9A%84%E7%BC%BA%E7%82%B9
簡而言之,就是rank的實質是一個概率。其被引用的概率。一開始是1/N,N是網頁的總數。假設A網頁有網頁B和網頁C兩個網站連結,而網頁B上有4個外連結,網頁C上有3個外連結。那麼網頁A的PR(A) = PR(B) / 4 + PR(C) / 3. 為了滿足馬爾科夫鏈的收斂定律,如果某個自私的網頁上沒有別的外連結,我們假設其對每個網頁都有連結,但是外加一個阻尼係數來判斷使用者有多大可能停留在相同的網頁而不會再重新在位址列上輸入新的地址。
針對網頁更新的問題,網頁如果被抓下來以後,有的網頁會持續變化,有的不會。這裡就需要對網頁的抓取設定一些生命力資訊。當一個新的網頁連結被發現以後,他的生命力時間戳資訊應該是被發現的時間,表示馬上需要被抓取,當一個網頁被抓取之後,他的生命力時間戳資訊可以被設定為x分鐘以後,那麼,等到x分鐘以後,這個網頁就可以根據這個時間戳來判斷出,他需要被馬上再抓取一次了。一個網頁被第二次抓取以後,需要和之前的內容進行對比,如果內容一致,則延長下一次抓取的時間,如設為2x分鐘後再抓取,直到達到一個限制長度如半年或者三個月(這個數值取決於你爬蟲的能力)。如果被更新了,則需要縮短時間,如,x/2分鐘之後再抓取。
架構設計,從簡單到複雜,下屬內容參考文章開頭的知乎專欄:
如果我們要爬取一個新聞網站的所有新聞頁面,我們我們需要得到這些頁面的url,這也是通過crawlers來獲取的(從HTML頁面中提取出來)。所以我們可以設計兩種crawler,一種負責獲取更多的url,一種負責爬取頁面內容。
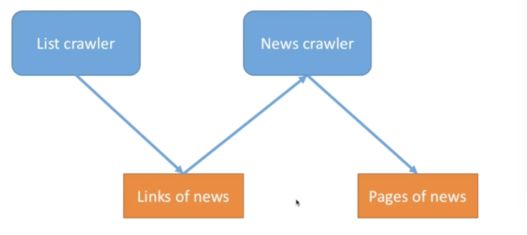
Links Of News就是BFS的Buffer佇列,而Pages of News則是爬出來的內容。
接著,針對不同的網站我們進行不同的BFS。所以,我們可以對不同的網站分別建立1個List Crawler執行緒和N個 News crawler執行緒。由於Buffer佇列和內容資料結構都是多執行緒共享的記憶體,所以需要臨界區資料保護。

在這裡,list crawler就是生產者,news crawler就是消費者。links of news就是生產、消費佇列。Page of news則是寫鎖臨界區。是一個排它鎖。
但是這個架構有一個問題,如果163的新聞比較少,sina最多,那麼163的爬蟲爬完了會閒置浪費,而不能幫忙爬sina。所以升級版是設計通用的爬蟲,每個Crawler任務不同,有的爬頁面,有的爬url,這些爬蟲都通過一個scheduler統一排程,這種架構減少了冗餘浪費,效能更優。

關於排程crawler可以是通過條件鎖的生產者消費者問題,可以參考我的部落格:https://blog.csdn.net/firehotest/article/details/60455811
以上講的是單機多執行緒的設計,那如果推到分散式的爬蟲呢?
最經典的架構就是Task&Pages在中心,Crawler分佈在四周,每個Crawler和一個Connector相對應。
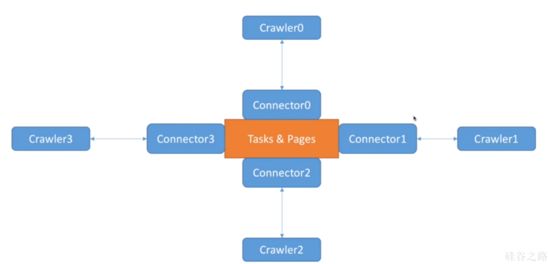

注意,此時connector變成了消費者。news crawler只是一個幹活的。
這個架構好像Connector太多了,我們真的需要這麼多Connector嗎?我們可以實現一個一對多的架構,由統一的Sender給Crawler發任務,統一的Receiver接收結果。用多一個table去記錄crawlers的狀態,只能由sender和receiver去修改。pages由receiver統一去修改。這個架構其實並沒有減少Crawler和中心的連線數,可是這種架構方便統一管理,免去了協調過多Connector的麻煩,也符合當下微架構的設計模式。
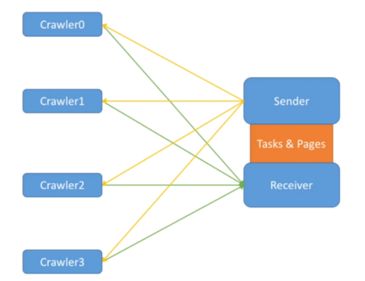
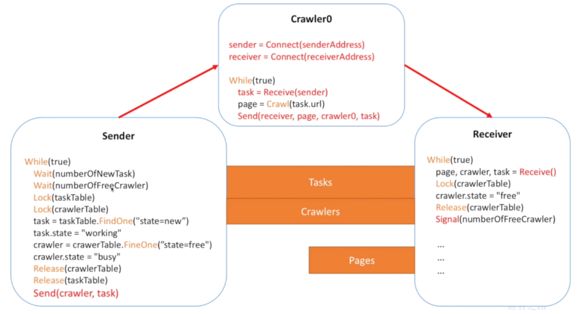
但是總是要鎖來鎖去有點麻煩,能不能避開鎖的問題呢?我們可以利用資料庫來解決,直接從資料庫裡獲取資料存放資料資料,讓資料庫來解決同步機制。
