
深度學習之(DNN)深度神經網路
(DNN)深度神經網路
簡介
DNN是指深度神經網路。與RNN迴圈神經網路、CNN卷積神經網路的區別就是DNN特指全連線的神經元結構,並不包含卷積單元或是時間上的關聯。
神經網路簡史
神經網路技術起源於上世紀五、六十年代,當時叫感知機(perceptron),擁有輸入層、輸出層和一個隱含層。輸入的特徵向量通過隱含層變換達到輸出層,在輸出層得到分類結果。但是,Rosenblatt的單層感知機有一個嚴重得不能再嚴重的問題,即它對稍複雜一些的函式都無能為力(比如最為典型的“異或”操作)。
隨著數學的發展,這個缺點直到上世紀八十年代才被Rumelhart、Williams、Hinton、LeCun
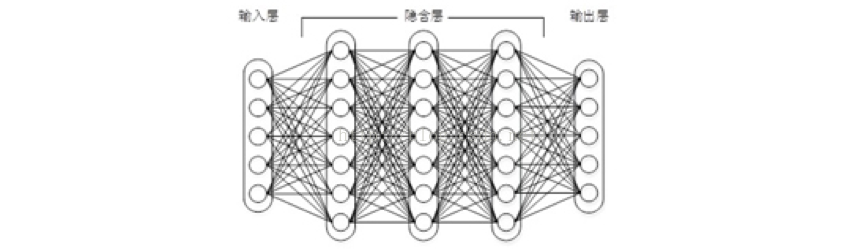
圖1 上下層神經元全部相連的神經網路——多層感知機
多層感知機可以擺脫早期離散傳輸函式的束縛,使用sigmoid或tanh等連續函式模擬神經元對激勵的響應,在訓練演算法上則使用Werbos發明的反向傳播BP演算法。對,這貨就是我們現在所說的神經網路NN。多層感知機解決了之前無法模擬異或邏輯的缺陷,同時更多的層數也讓網路更能夠刻畫現實世界中的複雜情形。多層感知機給我們帶來的啟示是,神經網路的層數直接決定了它對現實的刻畫能力——利用每層更少的神經元擬合更加複雜的函式
即便大牛們早就預料到神經網路需要變得更深,但是有一個夢魘總是縈繞左右。隨著神經網路層數的加深,優化函式越來越容易陷入區域性最優解,並且這個“陷阱”越來越偏離真正的全域性最優。利用有限資料訓練的深層網路,效能還不如較淺層網路。同時,另一個不可忽略的問題是隨著網路層數增加,“梯度消失”現象更加嚴重。具體來說,我們常常使用sigmoid作為神經元的輸入輸出函式。對於幅度為1的訊號,在BP反向傳播梯度時,每傳遞一層,梯度衰減為原來的0.25。層數一多,梯度指數衰減後低層基本上接受不到有效的訓練訊號。
DNN的出現
2006年,Hinton利用預訓練方法緩解了區域性最優解問題,將隱含層推動到了7層[2],神經網路真正意義上有了“深度”,由此揭開了深度學習的熱潮。這裡的“深度”並沒有固定的定義——在語音識別中
DNN使用時的一些問題
如圖1所示,我們看到全連線DNN的結構裡下層神經元和所有上層神經元都能夠形成連線,帶來的潛在問題是引數數量的膨脹。假設輸入的是一幅畫素為1K*1K的影象,隱含層有1M個節點,光這一層就有10^12個權重需要訓練,這不僅容易過擬合,而且極容易陷入區域性最優。另外,影象中有固有的區域性模式(比如輪廓、邊界,人的眼睛、鼻子、嘴等)可以利用,顯然應該將影象處理中的概念和神經網路技術相結合。
參考連結:http://www.zhihu.com/question/34681168/answer/84061846