分類模型的評價指標--混淆矩陣,ROC,AUC,KS,Lift,Gain
阿新 • • 發佈:2019-01-05
對於分類模型,常用的指標有混淆矩陣、ROC曲線,AUC值,KS曲線以及KS值、Lift圖,Gain圖等,查閱了很多的資料,加入自己的理解整理了一下他們的計算方法和意義,希望對大家有幫助。
1. 混淆矩陣---確定截斷點後,評價學習器效能假設訓練之初以及預測後,一個樣本是正例還是反例是已經確定的,這個時候,樣本應該有兩個類別值,一個是真實的0/1,一個是預測的0/1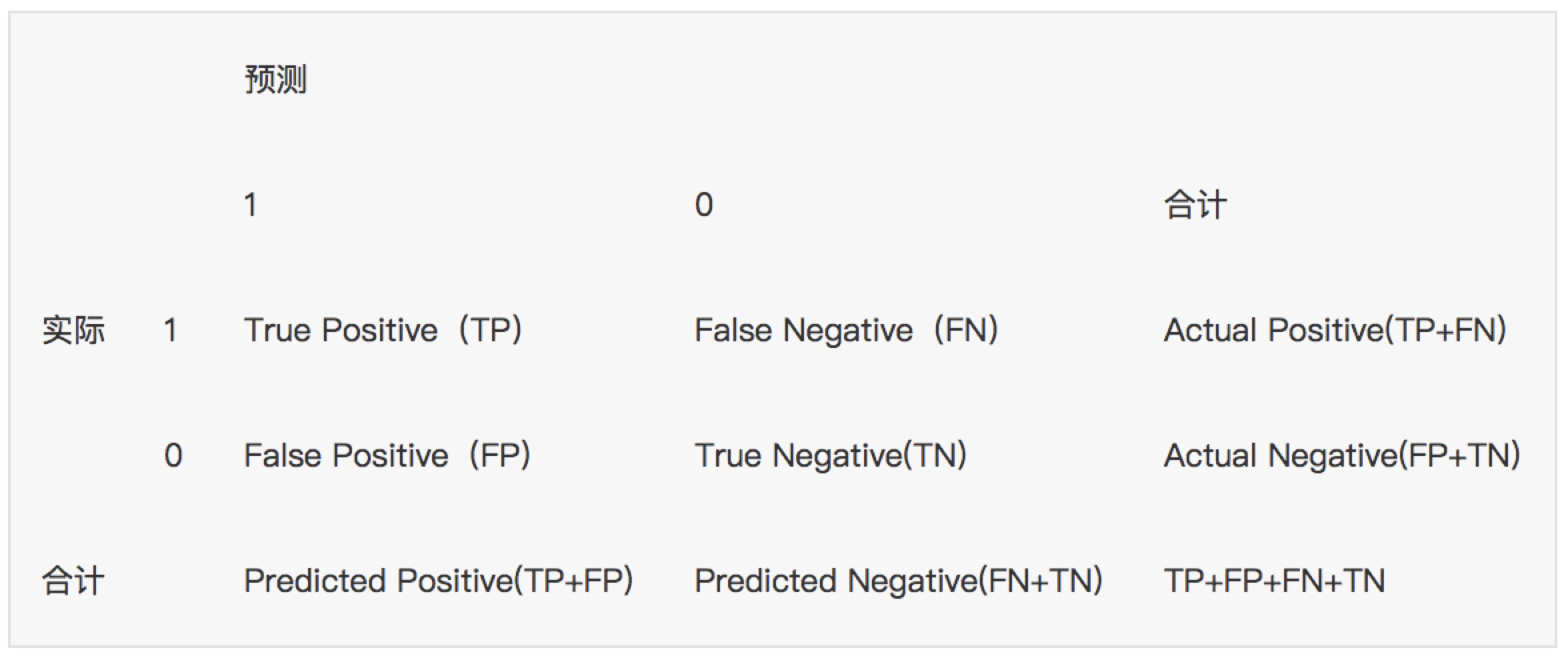
2. F1度量---查準率和查全率的加權調和平均數
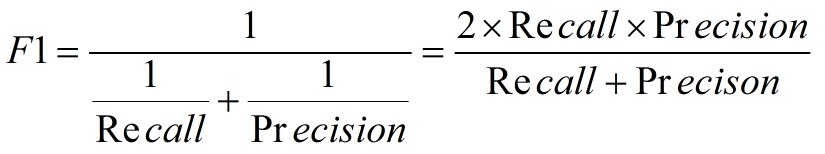
(2)當查準率查全率的重要性不同時,即權重不同時:通常,對於不同的問題,查準率查全率的側重不同。比如,對於商品推薦系統,為了減少對使用者的干擾,查準率更重要;逃犯系統中,查全率更重要。因此,F1度量的一般形式:
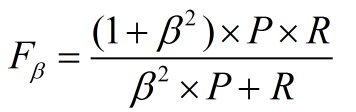
其中β表示查全率與查準率的權重,很多參考書上就只給出了這個公式,那麼究竟怎麼推導來的呢?兩個指標的設定及其關係如下,因為只考慮這兩個指標,所以二者權重和為1,即
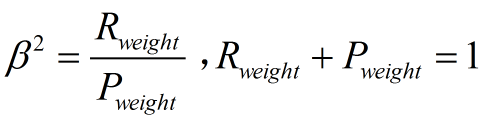
可以推導得到
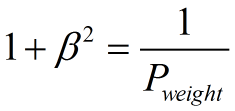
帶權重的調和平均數公式如下:
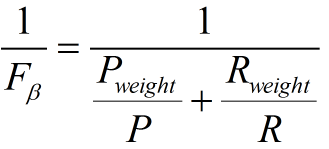
進一步推導:
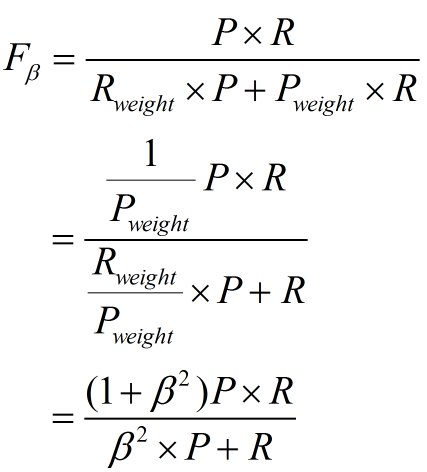
因此1. β=1,查全率的權重=查準率的權重,就是F12. β>1,查全率的權重>查準率的權重3. β<1,查全率的權重<查準率的權重那麼問題又來了,如果說我們有多個二分類混淆矩陣,應該怎麼評價F1指標呢?多個二分類混淆矩陣可能有以下幾種情況:多次訓練/測試,多個數據集上進行訓練/測試,多分類任務的兩兩類別組合等這裡介紹兩種做法:(1)巨集F1設有n個混淆矩陣,計算出查全率和查準率的平均值,在計算F1即可
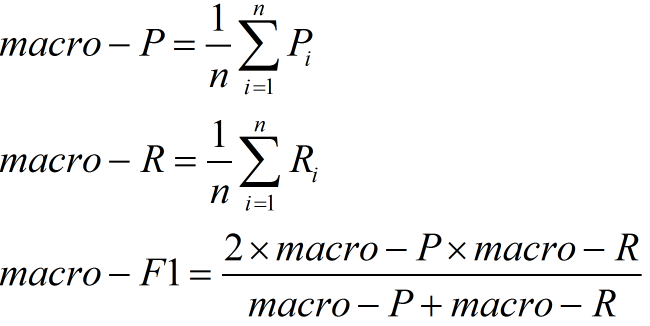 這種做法認為每一次的混淆矩陣(訓練)是同等權重的(2)微F1設有n個混淆矩陣,計算出混淆矩陣對應元素(TP,FP,FN,TN)的平均值,再計算查全率、查準率,F1
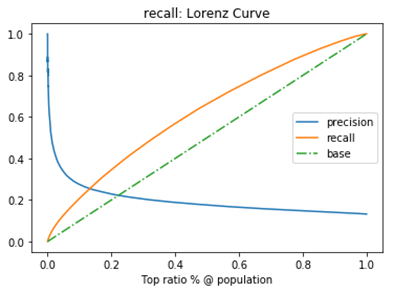
這種做法認為每一次的混淆矩陣(訓練)是同等權重的(2)微F1設有n個混淆矩陣,計算出混淆矩陣對應元素(TP,FP,FN,TN)的平均值,再計算查全率、查準率,F1  這種做法認為每一個樣本的權重是一樣的2. ROC曲線, AUC ----評價學習器效能,檢驗分類器對客戶進行正確排序的能力分類器產生的結果通常是一個概率值不是直接的0/1變數,通常數值越到,代表正例的可能性越大。根據任務的不同也會採取不同的“截斷點”,大於則為正例,小於則為反例。如重視查全率,則閾值可以設定低一些;而重視查準率,閾值可以設定高一些。如果設定了截斷點或明確了任務,那麼我們根據混淆矩陣就可以知道分類器的效果好壞。在未設定截斷點(任務不明確)情況下,我們如何評價一個分類模型的效果的好壞或者比較不同分類模型效果?我們可以觀察這個學習器利用所有可能的截斷點(就是所有樣本的預測結果)對樣本進行分類時的效果,注意要先對所有可能的截斷點進行排序,方便對比觀察。ROC曲線描繪的是不同的截斷點時,並以FPR和TPR為橫縱座標軸,描述隨著截斷點的變小,TPR隨著FPR的變化。縱軸:TPR=正例分對的概率 = TP/(TP+FN),其實就是查全率橫軸:FPR=負例分錯的概率 = FP/(FP+TN)
這種做法認為每一個樣本的權重是一樣的2. ROC曲線, AUC ----評價學習器效能,檢驗分類器對客戶進行正確排序的能力分類器產生的結果通常是一個概率值不是直接的0/1變數,通常數值越到,代表正例的可能性越大。根據任務的不同也會採取不同的“截斷點”,大於則為正例,小於則為反例。如重視查全率,則閾值可以設定低一些;而重視查準率,閾值可以設定高一些。如果設定了截斷點或明確了任務,那麼我們根據混淆矩陣就可以知道分類器的效果好壞。在未設定截斷點(任務不明確)情況下,我們如何評價一個分類模型的效果的好壞或者比較不同分類模型效果?我們可以觀察這個學習器利用所有可能的截斷點(就是所有樣本的預測結果)對樣本進行分類時的效果,注意要先對所有可能的截斷點進行排序,方便對比觀察。ROC曲線描繪的是不同的截斷點時,並以FPR和TPR為橫縱座標軸,描述隨著截斷點的變小,TPR隨著FPR的變化。縱軸:TPR=正例分對的概率 = TP/(TP+FN),其實就是查全率橫軸:FPR=負例分錯的概率 = FP/(FP+TN)如果是隨機分類,沒有進行任何學習器,FPR=TPR,即正例分對和負例分錯概率相同,預測出來的正例負例和正例負例本身的分佈是一致的,所以是一條45°的直線。因此,ROC曲線越向上遠離這條45°直線,說明用了這個學習器在很小的代價(負例分錯為正例,橫軸)下達到了相對較大的查全率(TPR)。
作圖步驟:1. 根據學習器的預測結果(注意,是正例的概率值,非0/1變數)對樣本進行排序(從大到小)-----這就是截斷點依次選取的順序2. 按順序選取截斷點,並計算TPR和FPR---也可以只選取n個截斷點,分別在1/n,2/n,3/n等位置3. 連線所有的點(TPR,FPR)即為ROC圖例圖:因為樣本有限,通常不是平滑曲線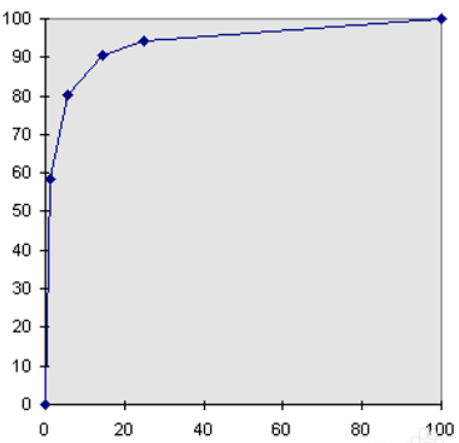
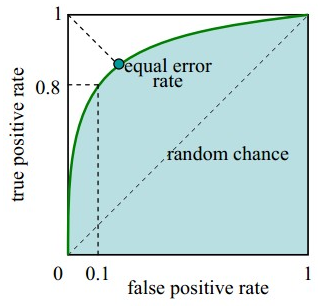
判斷標準:1. 一個ROC曲線完全”包住“另一個ROC曲線--->第一個學習器效果更好2. 兩個ROC曲線相交--->利用ROC曲線下的面積(AUC,area under ROC curve,是一個數值)進行比較3. KS曲線,KS值---學習器將正例和反例分開的能力,確定最好的“截斷點”KS曲線和ROC曲線都用到了TPR,FPR。KS曲線是把TPR和FPR都作為縱座標,而樣本數作為橫座標。作圖步驟:1. 根據學習器的預測結果(注意,是正例的概率值,非0/1變數)對樣本進行排序(從大到小)-----這就是截斷點依次選取的順序2. 按順序選取截斷點,並計算TPR和FPR ---也可以只選取n個截斷點,分別在1/n,2/n,3/n等位置3. 橫軸為樣本的佔比百分比(最大100%),縱軸分別為TPR和FPR,可以得到KS曲線4. TPR和FPR曲線分隔最開的位置就是最好的”截斷點“,最大間隔距離就是KS值,通常>0.2即可認為模型有比較好偶的預測準確性例圖:
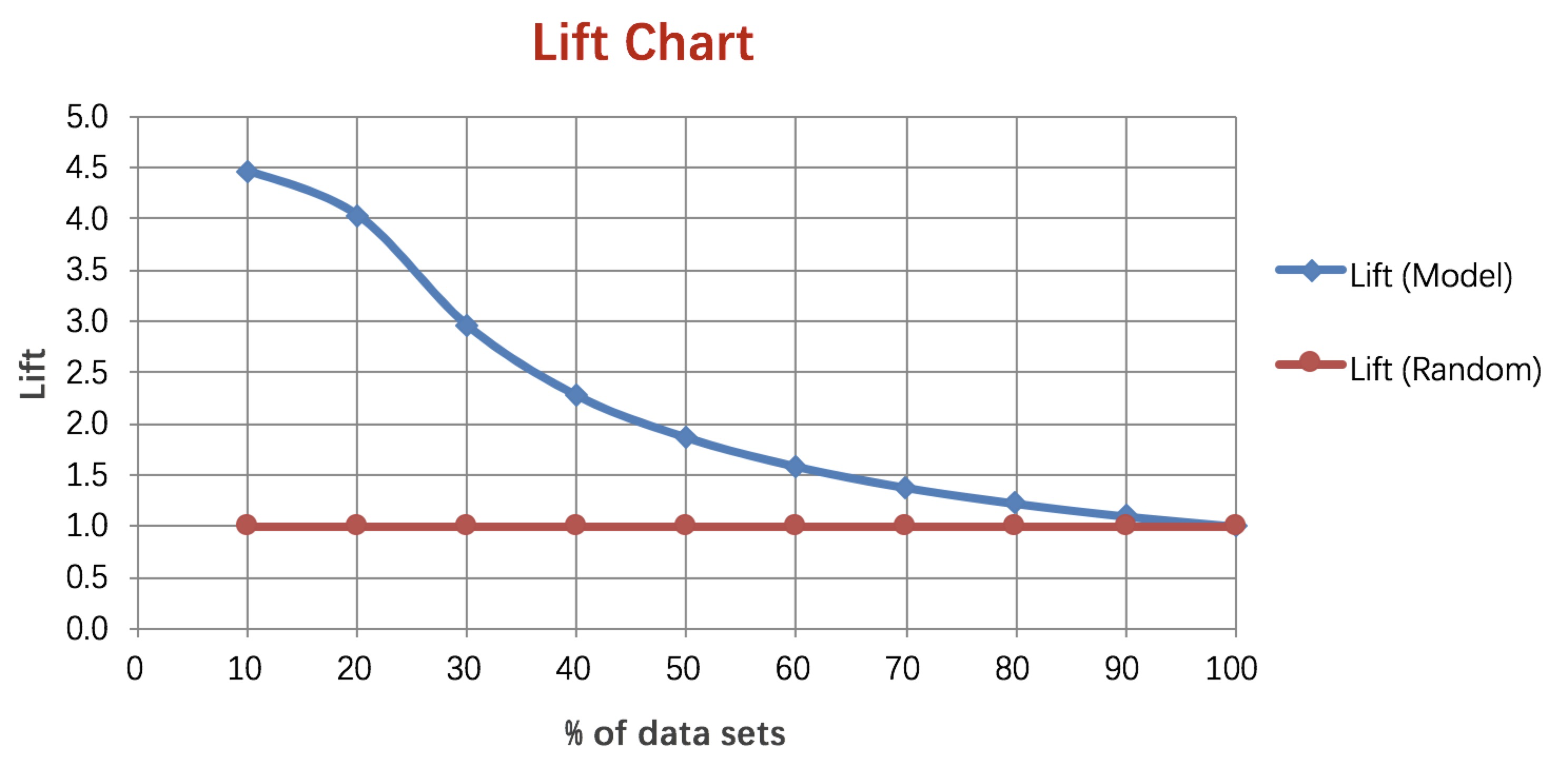
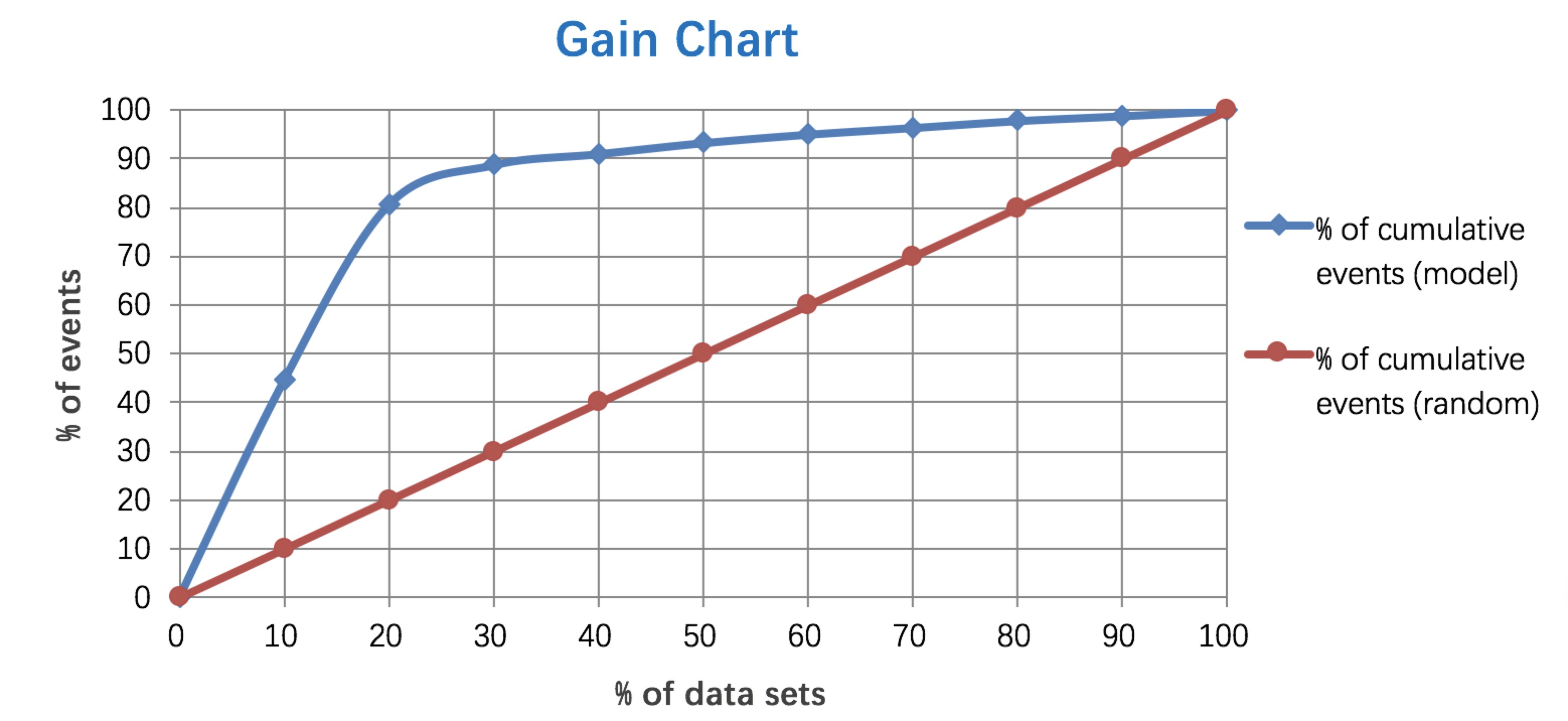
 4. Lift 和Gain圖個人認為前三個指標應用場景更多一些。Lift圖衡量的是,與不利用模型相比,模型的預測能力“變好”了多少,lift(提升指數)越大,模型的執行效果越好。Gain圖是描述整體精準度的指標。計算公式如下:
4. Lift 和Gain圖個人認為前三個指標應用場景更多一些。Lift圖衡量的是,與不利用模型相比,模型的預測能力“變好”了多少,lift(提升指數)越大,模型的執行效果越好。Gain圖是描述整體精準度的指標。計算公式如下: 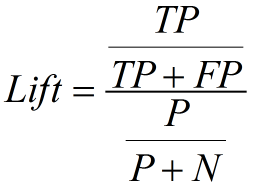
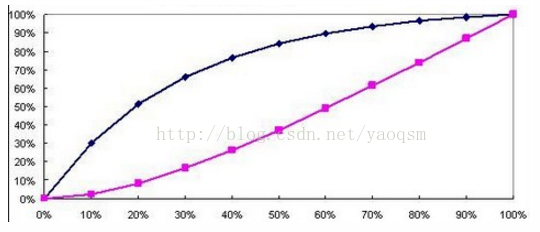
 作圖步驟:1. 根據學習器的預測結果(注意,是正例的概率值,非0/1變數)對樣本進行排序(從大到小)-----這就是截斷點依次選取的順序2. 按順序選取截斷點,並計算Lift和Gain ---也可以只選取n個截斷點,分別在1/n,2/n,3/n等位置例圖:
作圖步驟:1. 根據學習器的預測結果(注意,是正例的概率值,非0/1變數)對樣本進行排序(從大到小)-----這就是截斷點依次選取的順序2. 按順序選取截斷點,並計算Lift和Gain ---也可以只選取n個截斷點,分別在1/n,2/n,3/n等位置例圖: