
強化學習--Policy Gradient
阿新 • • 發佈:2019-01-05
Policy Gradient綜述:
Policy Gradient,通過學習當前環境,直接給出要輸出的動作的概率值。
Policy Gradient 不是單步更新,只能等玩完一個epoch,再更新引數,所以是一個off-policy
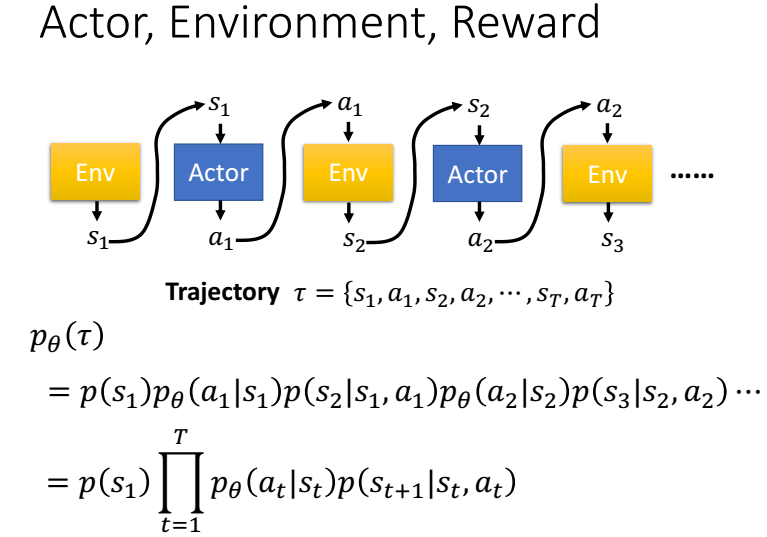
數學推導
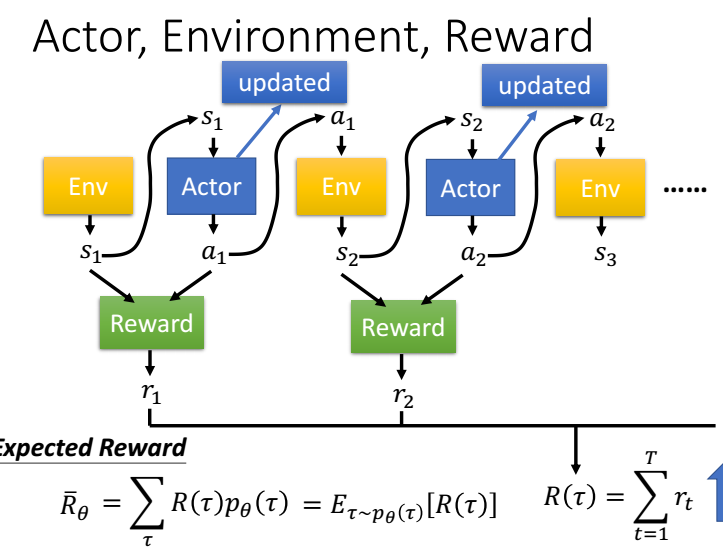
最大化R,,用梯度下降,需要求R的梯度。
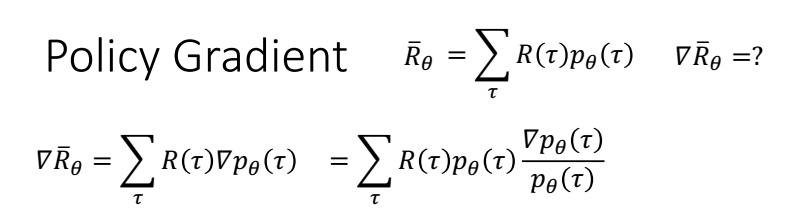
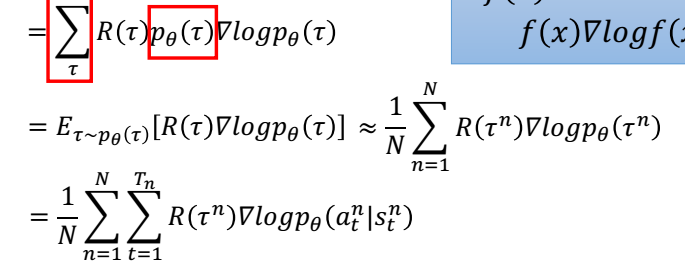
vt的計算
Policy Gradient 不是單步更新,只能等玩完一個epoch,得到每個epoch的observation_list \ action\_list reward_list
學習的時候,根據這三個list更新引數,其中下圖公式中的vt 根據reward_list算出來。
vt的計算
Policy Gradient 不是單步更新,只能等玩完一個epoch,得到每個epoch的observation_list \ action\_list reward_list
學習的時候,根據這三個list更新引數,其中下圖公式中的vt 根據reward_list算出來。
實現方式
神經網路分類模型,但是在算loss 的時候,logloss需要乘一個係數vt,這個係數與獎勵Reward相關,如果採用當前動作,
在接下來的遊戲中獲得的Reward越大,那麼在更新梯度的時候加大當前梯度下降的速度。
演算法步驟
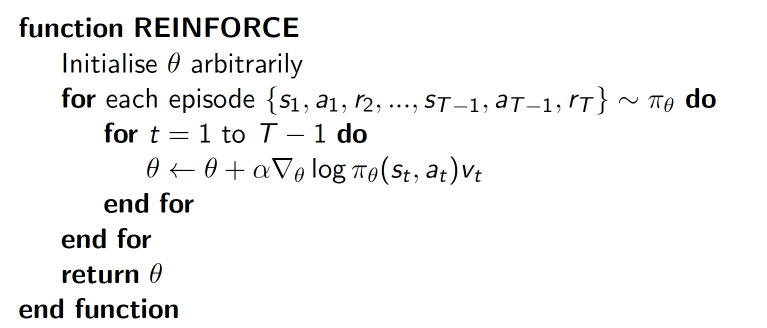
vt的計算
Policy Gradient 不是單步更新,只能等玩完一個epoch,得到每個epoch的observation_list \ action\_list reward_list
學習的時候,根據這三個list更新引數,其中下圖公式中的vt 根據reward_list算出來。
程式碼
1 """ 2 This part of code is the reinforcement learning brain, which is a brain of the agent.3 All decisions are made in here. 4 5 Policy Gradient, Reinforcement Learning. 6 7 View more on my tutorial page: https://morvanzhou.github.io/tutorials/ 8 9 Using: 10 Tensorflow: 1.0 11 gym: 0.8.0 12 """ 13 14 import numpy as np 15 import tensorflow as tf 16 17 # reproducible 18 np.random.seed(1) 19 tf.set_random_seed(1) 20 21 22 class PolicyGradient: 23 def __init__( 24 self, 25 n_actions, 26 n_features, 27 learning_rate=0.01, 28 reward_decay=0.95, 29 output_graph=False, 30 ): 31 self.n_actions = n_actions 32 self.n_features = n_features 33 self.lr = learning_rate 34 self.gamma = reward_decay 35 36 37 #每個epoch的observation \ action\ reward 38 self.ep_obs, self.ep_as, self.ep_rs = [], [], [] 39 40 self._build_net() 41 42 self.sess = tf.Session() 43 44 if output_graph: 45 # $ tensorboard --logdir=logs 46 # http://0.0.0.0:6006/ 47 # tf.train.SummaryWriter soon be deprecated, use following 48 tf.summary.FileWriter("logs/", self.sess.graph) 49 50 self.sess.run(tf.global_variables_initializer()) 51 52 def _build_net(self): 53 with tf.name_scope('inputs'): 54 self.tf_obs = tf.placeholder(tf.float32, [None, self.n_features], name="observations") 55 self.tf_acts = tf.placeholder(tf.int32, [None, ], name="actions_num") 56 self.tf_vt = tf.placeholder(tf.float32, [None, ], name="actions_value") 57 # fc1 58 layer = tf.layers.dense( 59 inputs=self.tf_obs, 60 units=10, 61 activation=tf.nn.tanh, # tanh activation 62 kernel_initializer=tf.random_normal_initializer(mean=0, stddev=0.3), 63 bias_initializer=tf.constant_initializer(0.1), 64 name='fc1' 65 ) 66 # fc2 67 all_act = tf.layers.dense( 68 inputs=layer, 69 units=self.n_actions, 70 activation=None, 71 kernel_initializer=tf.random_normal_initializer(mean=0, stddev=0.3), 72 bias_initializer=tf.constant_initializer(0.1), 73 name='fc2' 74 ) 75 76 self.all_act_prob = tf.nn.softmax(all_act, name='act_prob') # use softmax to convert to probability 77 78 with tf.name_scope('loss'): 79 # to maximize total reward (log_p * R) is to minimize -(log_p * R), and the tf only have minimize(loss) 80 neg_log_prob = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=all_act, labels=self.tf_acts) # this is negative log of chosen action 81 # or in this way: 82 # neg_log_prob = tf.reduce_sum(-tf.log(self.all_act_prob)*tf.one_hot(self.tf_acts, self.n_actions), axis=1) 83 loss = tf.reduce_mean(neg_log_prob * self.tf_vt) # reward guided loss 84 85 with tf.name_scope('train'): 86 self.train_op = tf.train.AdamOptimizer(self.lr).minimize(loss) 87 88 def choose_action(self, observation): 89 prob_weights = self.sess.run(self.all_act_prob, feed_dict={self.tf_obs: observation[np.newaxis, :]}) 90 action = np.random.choice(range(prob_weights.shape[1]), p=prob_weights.ravel()) # select action w.r.t the actions prob 91 return action 92 93 def store_transition(self, s, a, r): 94 self.ep_obs.append(s) 95 self.ep_as.append(a) 96 self.ep_rs.append(r) 97 98 def learn(self): 99 # discount and normalize episode reward 100 discounted_ep_rs_norm = self._discount_and_norm_rewards() 101 102 # train on episode 103 self.sess.run(self.train_op, feed_dict={ 104 self.tf_obs: np.vstack(self.ep_obs), # shape=[None, n_obs] 105 self.tf_acts: np.array(self.ep_as), # shape=[None, ] 106 self.tf_vt: discounted_ep_rs_norm, # shape=[None, ] 107 }) 108 109 self.ep_obs, self.ep_as, self.ep_rs = [], [], [] # empty episode data 110 return discounted_ep_rs_norm 111 112 def _discount_and_norm_rewards(self): 113 # discount episode rewards 114 discounted_ep_rs = np.zeros_like(self.ep_rs) 115 running_add = 0 116 for t in reversed(range(0, len(self.ep_rs))): 117 running_add = running_add * self.gamma + self.ep_rs[t] 118 discounted_ep_rs[t] = running_add 119 120 # normalize episode rewards 121 discounted_ep_rs -= np.mean(discounted_ep_rs) 122 discounted_ep_rs /= np.std(discounted_ep_rs) 123 return discounted_ep_rs