
倒排索引概念及完整例項
在電腦科學領域,倒排索引(也稱為倒排檔案)是一種儲存了來自文字中的對映的索引資料結構。比如單詞或者數字,對應到它們在資料庫、一個檔案或者一組檔案中的位置。它是在文件檢索系統中使用的最流行的資料結構,在搜尋引擎中有大規模使用案例。
先認識 “單詞—文件” 矩陣
單詞—文件基本模型:
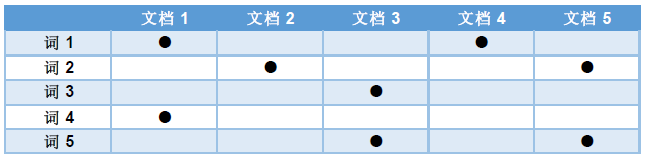
以上表示:
詞1在文件1和文件4中出現,文件1包含詞1和詞4。
詞2在文件2和文件5中出現,文件2包含詞2。
…不一一囉嗦
搜尋引擎的索引其實就是實現 “ 單詞—文件 ”矩陣的具體資料結構。
各項實驗資料表明,倒排索引是單詞到文件對映關係的最佳實現方式
倒排索引相關的基本術語
文件(Document):一般搜尋引擎處理的物件是網際網路網頁,對於搜尋引擎來講,Word、PDF、html、XML等不同格式的檔案都可以稱為文件,一般以文件來表示文字資訊。
文件集合(Document Collection):由若干文件構成的集合成為文件集合。比如海量的網際網路網頁等。
文件編號(Document ID):在搜尋引擎內部,會為文件集合每個文件賦予一個唯一的內部編號,以作為文件的唯一標識,以便於處理。
單詞編號(Word ID):與文件編號類似,搜尋引擎內部以唯一的編號來表示某個單詞,以作為某個單詞的唯一表示。
倒排索引(Inverted Index
單詞詞典(Lexicon):搜尋引擎通常的索引單位是單詞,單詞詞典是由文件集合中出現過的所有單詞構成的字串集合,單詞詞典內每條索引記載單詞本身的一些資訊及指向倒排列表的指標。
倒排列表(PostingList):倒排列表記載了出現過某個單詞的所有文件的文件列表及單詞在該文當中出現的位置資訊,每條記錄成為一個倒排向(Posting)。根據倒排列表,即可獲知哪些文件包含某個單詞。
倒排檔案(Inverted File):所有單詞的倒排列表往往順序地儲存在磁碟的某個檔案裡,這個檔案即為倒排檔案,倒排檔案是儲存倒排索引的物理檔案。
倒排索引示意圖:
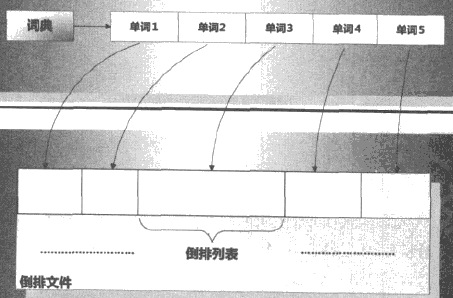
一個倒排索引的例項
例項文件如下圖:

中文和英文不同,詞之間無明確的分隔符號,首先需用分詞系統將文件自動切分成單詞序列。
然後對每個單詞賦予唯一的單詞編號,同時記錄下哪些文件包含這個單詞,處理後即得到最簡單的倒排索引:
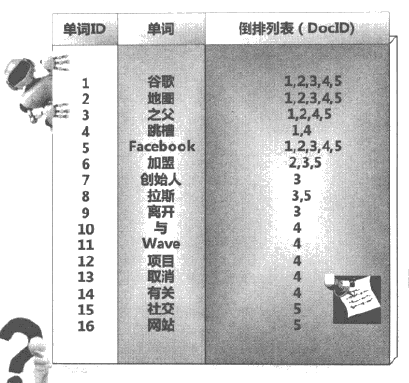
第1列單詞ID即為每個單詞的編號。
第2列即為對應的單詞。
第3列即為每個單詞對應的倒排序表。(比如單詞“拉斯”,單詞編號為8,倒排序表為{3,5},說明文件集合中文件3和文件5包含這個單詞。)
稍複雜的帶有單詞頻率資訊的倒排索引:

就編號8—拉斯—{(3:1);(5,1)}來說,(3,1)表示“拉斯”在文件3中出現一次,(5,1)表示“拉斯”在文件5中出現1次。
更實用的、基本完善的倒排索引:

就編號8—拉斯—2—{(3;1;<4>),(5;1;<4>)}來說,文件頻率2表示在兩個文件出現。“<4>”表示單詞出現的位置是文件中的第4個單詞。
這個倒排索引基本上是一個完備的索引系統了,實際搜尋系統的索引結構基本如此。
知識來源:維基百科、《這就是搜尋引擎-核心技術詳解》第三章等