
非極大值抑制-NMS
阿新 • • 發佈:2019-01-06
圖片來源
原理如下:
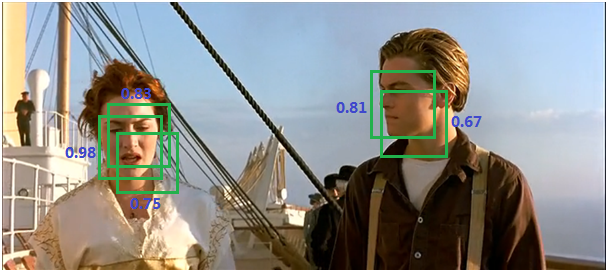
非極大值抑制的方法是:在進行目標檢測時會產生很多候選區域,如圖所示產生了1~5號框,而這些候選區域一般會有好多重疊的部分,先對這些框的概率從大到小進行排序,然後按概率從大到小遍歷所有框:
(1)從最大概率1號矩形框開始,分別判斷剩下的框與該框的重疊度IOU(IOU的計算)是否大於某個設定的閾值;
(2)假設2、3與1的IOU超過閾值,那麼就扔掉2、3;並標記第一個矩形框1保留下來。
(3)從剩下的矩形框4、5中,選擇概率最大的4,然後判斷4、5的IOU,IOU大於一定的閾值,那麼就扔掉;並標記4為第二個矩形框。
就這樣一直重複,找到所有被保留下來的矩形框。
程式碼如下:
def non_max_suppression_fast(boxes, probs, overlap_thresh=0.9, max_boxes=300):
# code used from here: http://www.pyimagesearch.com/2015/02/16/faster-non-maximum-suppression-python/
# if there are no boxes, return an empty list
if len(boxes) == 0:
return []
# 獲取框的座標
x1 = boxes[:, 0