
卷積神經網路提取特徵並用於SVM
目標是對UCI的手寫數字資料集進行識別,樣本數量大約是1600個。圖片大小為16x16。要求必須使用SVM作為二分類的分類器。
本文重點是如何使用卷積神經網路(CNN)來提取手寫數字圖片特徵,主要想看如何提取特徵的請直接看原始碼部分的94行左右,只要對tensorflow有一點了解就可以看懂。在最後會有完整的原始碼、處理後資料的分享連結。轉載請保留原文連結,謝謝。
UCI手寫數字的資料集
卷積和池化形象理解
卷積
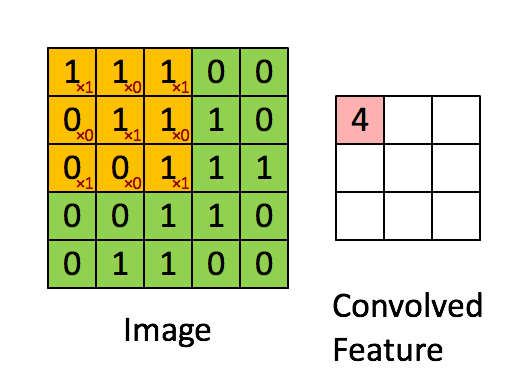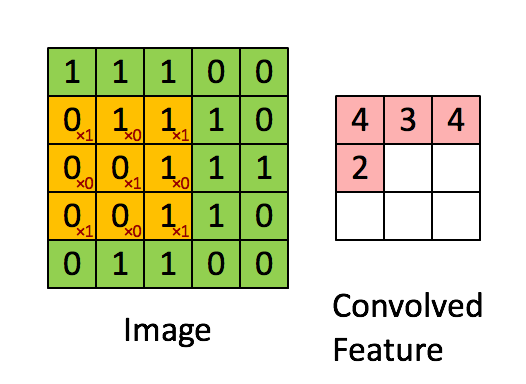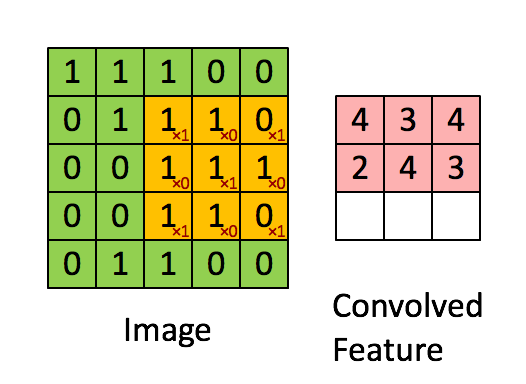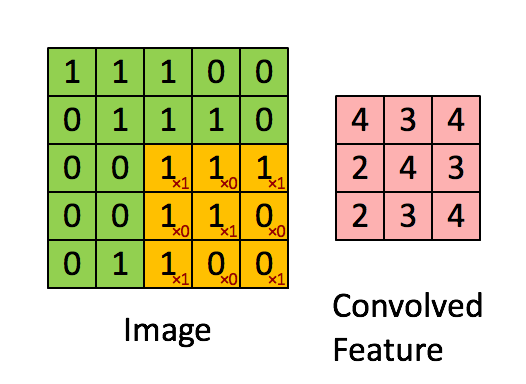
池化
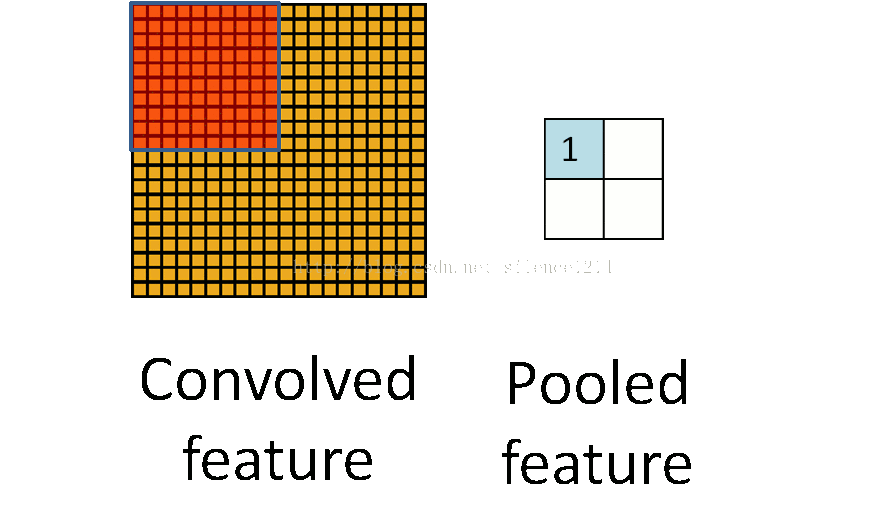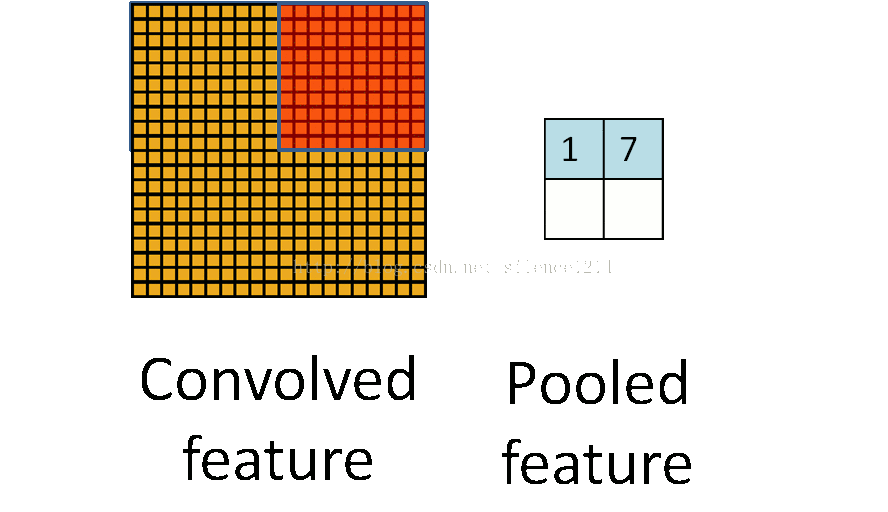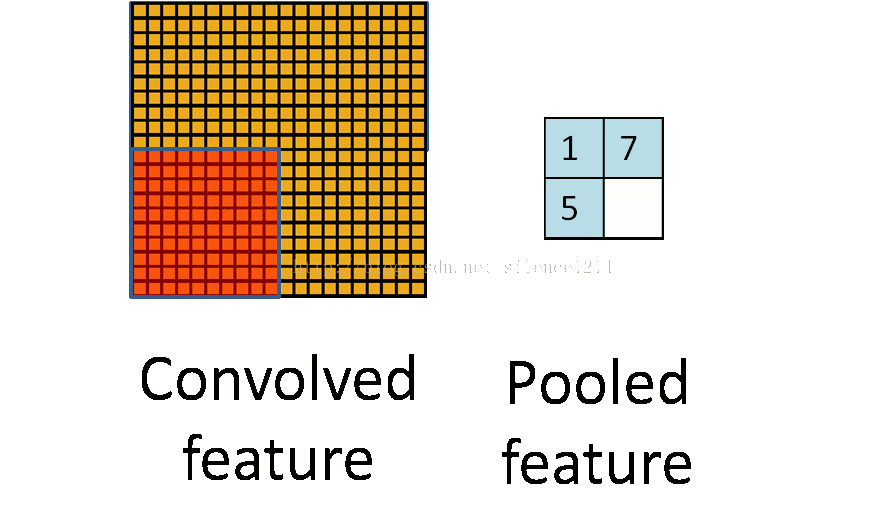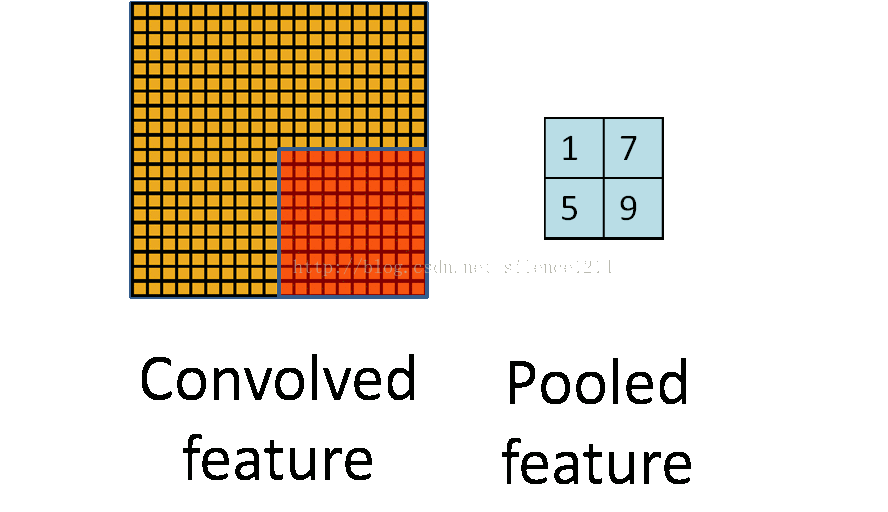
仔細的看,慢慢想就能明白CNN提取特徵的思想巧妙之處。
能明白這兩點,剩下的東西就和普通的神經網路區別不大了。
為什麼要用CNN提取特徵?
1.由於卷積和池化計算的性質,使得影象中的平移部分對於最後的特徵向量是沒有影響的。從這一角度說,提取到的特徵更不容易過擬合。而且由於平移不變性,所以平移字元進行變造是無意義的,省去了再對樣本進行變造的過程。
2.CNN抽取出的特徵要比簡單的投影、方向,重心都要更科學。不會讓特徵提取成為最後提高準確率的瓶頸、天花板
3.可以利用不同的卷積、池化和最後輸出的特徵向量的大小控制整體模型的擬合能力。在過擬合時可以降低特徵向量的維數,在欠擬合時可以提高卷積層的輸出維數。相比於其他特徵提取方法更加靈活
演算法流程
整理訓練網路的資料 -> 建立卷積神經網路 -> 將資料代入進行訓練 -> 儲存訓練好的模型 -> 把資料代入模型獲得特徵向量 -> 用特徵向量代替原本的X送入SVM訓練 -> 測試時同樣將X轉換為特徵向量之後用SVM預測,獲得結果。
CNN結構和引數
如圖所示:
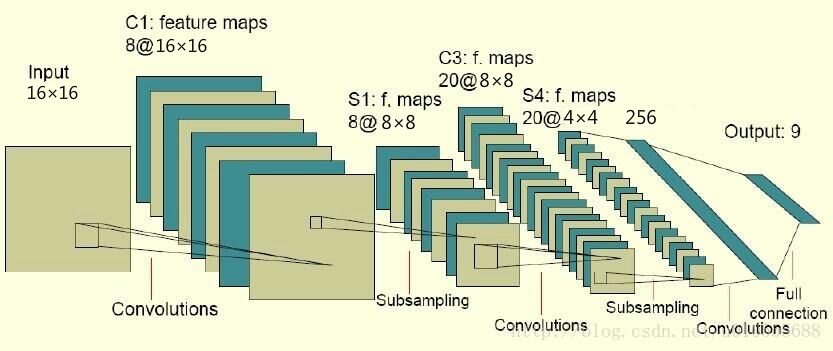
第一個卷積核大小為5x5
第一個池化層是2x2最大池化,輸出32維
第二個卷積核大小為5x5
第二個池化層是2x2最大池化,輸出64維
全連線層輸出256維特徵向量。
輸出層最終採用softmax函式,以交叉熵作為優化目標。
SVM的引數
SVM採用的是RBF核
C取0.9
Tol取1e-3
Gamma為scikit-learn自動設定
其實在實驗中發現,如果特徵提取的不夠好,那麼怎麼調SVM的引數也達不到一個理想的狀態。而特徵提取的正確,那麼同樣,SVM的引數影響也不是很大,可能調了幾次最後僅僅改變一兩個樣本的預測結果。
樣本處理過程
1.將原樣本隨機地分為兩半。一份為訓練集,一份為測試集
2.重複1過程十次,得到十個訓練集和十個對應的測試集
操作過程
1.取十份訓練集中的一份和其對應的測試集。代入到CNN和SVM中訓練。計算模型在剩下9個測試集中的表現。
2.依次取訓練集和測試集,則可完成十次第一步。
3.將十次的表現綜合評價
原始碼及註釋
# coding=utf8 import random import numpy as np import tensorflow as tf from sklearn import svm right0 = 0.0 # 記錄預測為1且實際為1的結果數 error0 = 0 # 記錄預測為1但實際為0的結果數 right1 = 0.0 # 記錄預測為0且實際為0的結果數 error1 = 0 # 記錄預測為0但實際為1的結果數 for file_num in range(10): # 在十個隨機生成的不相干資料集上進行測試,將結果綜合 print 'testing NO.%d dataset.......' % file_num ff = open('digit_train_' + file_num.__str__() + '.data') rr = ff.readlines() x_test2 = [] y_test2 = [] for i in range(len(rr)): x_test2.append(map(int, map(float, rr[i].split(' ')[:256]))) y_test2.append(map(int, rr[i].split(' ')[256:266])) ff.close() # 以上是讀出訓練資料 ff2 = open('digit_test_' + file_num.__str__() + '.data') rr2 = ff2.readlines() x_test3 = [] y_test3 = [] for i in range(len(rr2)): x_test3.append(map(int, map(float, rr2[i].split(' ')[:256]))) y_test3.append(map(int, rr2[i].split(' ')[256:266])) ff2.close() # 以上是讀出測試資料 sess = tf.InteractiveSession() # 建立一個tensorflow的會話 # 初始化權值向量 def weight_variable(shape): initial = tf.truncated_normal(shape, stddev=0.1) return tf.Variable(initial) # 初始化偏置向量 def bias_variable(shape): initial = tf.constant(0.1, shape=shape) return tf.Variable(initial) # 二維卷積運算,步長為1,輸出大小不變 def conv2d(x, W): return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME') # 池化運算,將卷積特徵縮小為1/2 def max_pool_2x2(x): return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') # 給x,y留出佔位符,以便未來填充資料 x = tf.placeholder("float", [None, 256]) y_ = tf.placeholder("float", [None, 10]) # 設定輸入層的W和b W = tf.Variable(tf.zeros([256, 10])) b = tf.Variable(tf.zeros([10])) # 計算輸出,採用的函式是softmax(輸入的時候是one hot編碼) y = tf.nn.softmax(tf.matmul(x, W) + b) # 第一個卷積層,5x5的卷積核,輸出向量是32維 w_conv1 = weight_variable([5, 5, 1, 32]) b_conv1 = bias_variable([32]) x_image = tf.reshape(x, [-1, 16, 16, 1]) # 圖片大小是16*16,,-1代表其他維數自適應 h_conv1 = tf.nn.relu(conv2d(x_image, w_conv1) + b_conv1) h_pool1 = max_pool_2x2(h_conv1) # 採用的最大池化,因為都是1和0,平均池化沒有什麼意義 # 第二層卷積層,輸入向量是32維,輸出64維,還是5x5的卷積核 w_conv2 = weight_variable([5, 5, 32, 64]) b_conv2 = bias_variable([64]) h_conv2 = tf.nn.relu(conv2d(h_pool1, w_conv2) + b_conv2) h_pool2 = max_pool_2x2(h_conv2) # 全連線層的w和b w_fc1 = weight_variable([4 * 4 * 64, 256]) b_fc1 = bias_variable([256]) # 此時輸出的維數是256維 h_pool2_flat = tf.reshape(h_pool2, [-1, 4 * 4 * 64]) h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, w_fc1) + b_fc1) # h_fc1是提取出的256維特徵,很關鍵。後面就是用這個輸入到SVM中 #比方說,我訓練完資料了,那麼想要提取出來全連線層的h_fc1, #那麼使用的語句是sess.run(h_fc1, feed_dict={x: input_x}),返回的結果就是特徵向量 # 設定dropout,否則很容易過擬合 keep_prob = tf.placeholder("float") h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob) # 輸出層,在本實驗中只利用它的輸出反向訓練CNN,至於其具體數值我不關心 w_fc2 = weight_variable([256, 10]) b_fc2 = bias_variable([10]) y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop, w_fc2) + b_fc2) cross_entropy = -tf.reduce_sum(y_ * tf.log(y_conv)) # 設定誤差代價以交叉熵的形式 train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy) # 用adma的優化演算法優化目標函式 correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) sess.run(tf.initialize_all_variables()) for i in range(3000): # 跑3000輪迭代,每次隨機從訓練樣本中抽出50個進行訓練 batch = ([], []) p = random.sample(range(795), 50) for k in p: batch[0].append(x_test2[k]) batch[1].append(y_test2[k]) if i % 100 == 0: train_accuracy = accuracy.eval(feed_dict={x: batch[0], y_: batch[1], keep_prob: 1.0}) # print "step %d, train accuracy %g" % (i, train_accuracy) train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.6}) # 設定dropout的引數為0.6,測試得到,大點收斂的慢,小點出現過擬合 print "test accuracy %g" % accuracy.eval(feed_dict={x: x_test3, y_: y_test3, keep_prob: 1.0}) for h in range(len(y_test2)): if np.argmax(y_test2[h]) == 7: y_test2[h] = 1 else: y_test2[h] = 0 for h in range(len(y_test3)): if np.argmax(y_test3[h]) == 7: y_test3[h] = 1 else: y_test3[h] = 0 # 以上兩步都是為了將源資料的one hot編碼改為1和0,我的學號尾數為7 x_temp = [] for g in x_test2: x_temp.append(sess.run(h_fc1, feed_dict={x: np.array(g).reshape((1, 256))})[0]) # 將原來的x帶入訓練好的CNN中計算出來全連線層的特徵向量,將結果作為SVM中的特徵向量 x_temp2 = [] for g in x_test3: x_temp2.append(sess.run(h_fc1, feed_dict={x: np.array(g).reshape((1, 256))})[0]) clf = svm.SVC(C=0.9, kernel='rbf') clf.fit(x_temp, y_test2) # SVM選擇了rbf核,C選擇了0.9 for j in range(len(x_temp2)): # 驗證時出現四種情況分別對應四個變數儲存 if clf.predict(x_temp2[j])[0] == y_test3[j] == 1: right0 += 1 elif clf.predict(x_temp2[j])[0] == y_test3[j] == 0: right1 += 1 elif clf.predict(x_temp2[j])[0] == 1 and y_test3[j] == 0: error0 += 1 else: error1 += 1 accuracy = right0 / (right0 + error0) # 準確率 recall = right0 / (right0 + error1) # 召回率 print 'svm right ratio ', (right0 + right1) / (right0 + right1 + error0 + error1) #分類的正確率 print 'accuracy ', accuracy print 'recall ', recall print 'F1 score ', 2 * accuracy * recall / (accuracy + recall) # F1值
最後結果為:
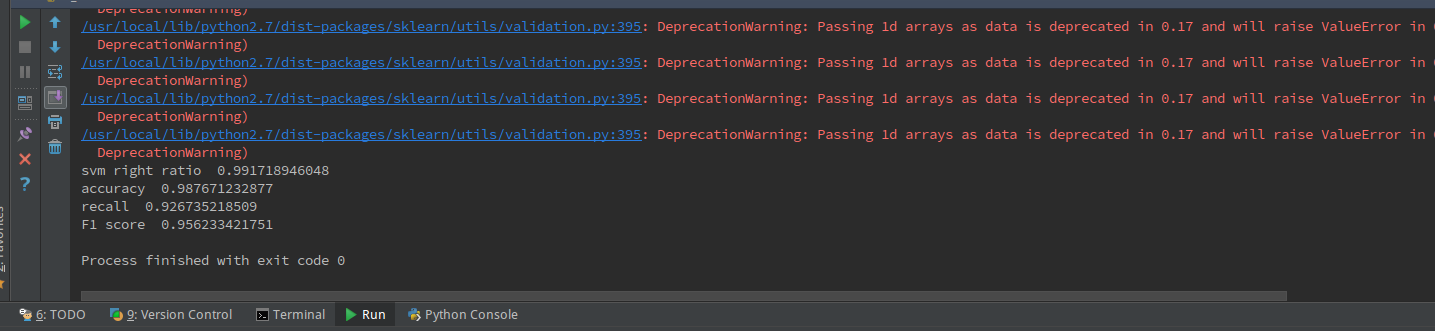
分類的正確率達到了99.1%,準確率98.77%,召回率為92.67%,F1值為0.9562
由於我們是十次驗證取平均值,所以模型的泛化能力和準確度都還是比較令人滿意的。
全部原始碼和使用到的資料(按照前文規則生成的訓練集和測試集)下載連結:https://raw.githubusercontent.com/chuxiuhong/cloudphoto/master/CNN-SVM.rar
相關推薦
卷積神經網路提取特徵並用於SVM
目標是對UCI的手寫數字資料集進行識別,樣本數量大約是1600個。圖片大小為16x16。要求必須使用SVM作為二分類的分類器。 本文重點是如何使用卷積神經網路(CNN)來提取手寫數字圖片特徵,主要想看如何提取特徵的請直接看原始碼部分的94行左右,只要對tensorflow有一點了解就可以看懂。在最後會有完整的
視覺化探索卷積神經網路提取特徵
前言 卷積神經網路的發展主要是為了解決人類視覺問題,不過現在其它方向也都會使用。發展歷程主要從Lenet5->Alexnet->VGG->GooLenet->ResNet等。 傳統神經網路 傳統BP神經網路層與層之間都是全連線的,對於影象處理領域,當神
基於Python的卷積神經網路和特徵提取
基於Python的卷積神經網路和特徵提取 發表於2015-08-27 21:39| 4577次閱讀| 來源blog.christianperone.com/| 13 條評論| 作者Christian S.Peron 深度學習特徵提取神經網路Pythonnolea
cs231n 卷積神經網路與計算機視覺 2 SVM softmax
linear classification 上節中簡單介紹了影象分類的概念,並且學習了費時費記憶體但是精度不高的knn法,本節我們將會進一步學習一種更好的方法,以後的章節中會慢慢引入神經網路和convolutional neural network。這種新的演
cs231n 卷積神經網路與計算機視覺 2 SVM softmax
linear classification 上節中簡單介紹了影象分類的概念,並且學習了費時費記憶體但是精度不高的knn法,本節我們將會進一步學習一種更好的方法,以後的章節中會慢慢引入神經網路和convolutional neural network。這種新的演算法有兩
淺析卷積神經網路為何能夠進行特徵提取
CNN在分類領域,有著驚人的效果。我們今天來聊聊為何CNN能有這麼大的能力。 在此之前,我們先了解兩個數學概念,特徵值和特徵向量。 這裡先放3個傳送門: 前兩個是有關特徵值和特徵向量的部落格,最後一個是一個求解特徵值和特徵向量的部落格。OK,進入正題,這裡引
用於說明卷積神經網路(ConvNet)的Python指令碼
借鑑:https://github.com/gwding/draw_convnet 直接上程式碼: import os import numpy as np import matplotlib.pyplot as plt plt.rcdefaults() from matplotlib.li
基於卷積神經網路特徵圖的二值影象分割
目標檢測是當前大火的一個研究方向,FasterRCNN、Yolov3等一系列結構也都在多目標檢測的各種應用場景或者競賽中取得了很不錯的成績。但是想象一下,假設我們需要通過影象檢測某個產品上是否存在缺陷,或者通過衛星圖判斷某片海域是否有某公司的船隻
MTCNN-將多工級聯卷積神經網路用於人臉檢測和對齊
論文連結: 摘要:由於姿勢、光照或遮擋等原因,在非強迫環境下的人臉識別和對齊是一項具有挑戰性的問題。最近的研究顯示,深度學習演算法可以很好的解決上述的兩個問題。在這篇文章中,我們利用檢測和校準之間固有的相關性在深度級聯的多工框架下來提升它們的效能。尤其是,我們利
深度學習(十五)基於級聯卷積神經網路的人臉特徵點定位
基於級聯卷積神經網路的人臉特徵點定位作者:hjimce一、相關理論本篇博文主要講解2013年CVPR的一篇利用深度學習做人臉特徵點定位的經典paper:《Deep Convolutional Netwo
理解卷積神經網路CNN中的特徵圖 feature map
一直以來,感覺 feature map 挺晦澀難懂的,今天把初步的一些理解記錄下來。參考了斯坦福大學的機器學習公開課和七月演算法中的機器學習課。 CNN一個牛逼的地方就在於通過感受野和權值共享減少了神經網路需要訓練的引數的個數。總之,卷積網路的
Tensorflow訓練卷積神經網路並儲存模型,載入模型並匯入手寫圖片測試
剛學習tensorflow,折騰了這幾天,之前一直按照書上的教程訓練網路,看那些沒玩沒了的不斷接近於1的準確率,甚是無聊,我一直想將辛辛苦苦訓練出來的網路,那些識別率看上去很高的網路,是否能真正用來識別外面匯入的圖片呢,而不僅僅是那些訓練集或者測試集的圖片。
3用於MNIST的卷積神經網路-3.4卷積濾波器核的數量與網路效能之間的關係
程式碼: #-*- coding:utf-8 -*- #實現簡單卷積神經網路對MNIST資料集進行分類:conv2d + activation + pool + fc import csv import tensorflow
基於Tensorflow, OpenCV. 使用MNIST資料集訓練卷積神經網路模型,用於手寫數字識別
基於Tensorflow,OpenCV 使用MNIST資料集訓練卷積神經網路模型,用於手寫數字識別 一個單層的神經網路,使用MNIST訓練,識別準確率較低 兩層的卷積神經網路,使用MNIST訓練(模型使用MNIST測試集準確率高於99%
4用於cifar10的卷積神經網路-4.6設計模型訓練和評估的會話流程
在TensorFlow中實現這個網路模型 0、載入資料集 1、啟動會話 2、一輪一輪的訓練模型 2.1、在每一輪中分多個批次餵給資料 2.1.1在每個批次上執行訓練節點,訓練模型 2.1.2經過
ABCNN基於注意力的卷積神經網路用於句子建模--模型介紹篇
本文是Wenpeng Yin寫的論文“ABCNN: Attention-Based Convolutional Neural Network for Modeling Sentence Pairs”的閱讀筆記。其實該作者之前還發過一篇“Convolution N
Tensorflow實現卷積神經網路,用於人臉關鍵點識別
今年來人工智慧的概念越來越火,AlphaGo以4:1擊敗李世石更是起到推波助瀾的作用。作為一個開挖掘機的菜鳥,深深感到不學習一下deep learning早晚要被淘汰。 既然要開始學,當然是搭一個深度神經網路跑幾個資料集感受一下作為入門最直觀了。自己寫程式碼實
卷積神經網路特徵圖視覺化(自定義網路和VGG網路)
藉助Keras和Opencv實現的神經網路中間層特徵圖的視覺化功能,方便我們研究CNN這個黑盒子裡到發生了什麼。 自定義網路特徵視覺化 程式碼: # coding: utf-8 from keras.models import Model import c
TensorFlow實現用於影象分類的卷積神經網路(程式碼詳細註釋)
這裡我們採用cifar10作為我們的實驗資料庫。 首先下載TensorFlow Models庫,以便使用其中提供的CIFAR-10資料的類。 git clone https://github.com/tensorflow/models.git cd mo
影象語義分割(1)-FCN:用於語義分割的全卷積神經網路
論文地址:Fully Convolutional Networks for Semantic Segmentation [Long J , Shelhamer E , Darrell T . Fully Convolutional Networks for Semantic Segmen