
Caffe:如何執行一個pre-train過的神經網路——以VGG16為例
實驗環境:
Ubuntu 14.04
所需環境:
Caffe(GPU)
Python2.7
JUPYTER NOTEBOOK
所需依賴包:
numpy
matplotlib
skimage
h5py
本次實驗採用的網路介紹:
在ICIR論文《VERY DEEP CONVOLUTIONAL NETWORK SFOR LARGE-SCALE IMAGE RECOGNITION》中,作者提出了VGG的神經網路模型。VGG網路的介紹如圖1所示。
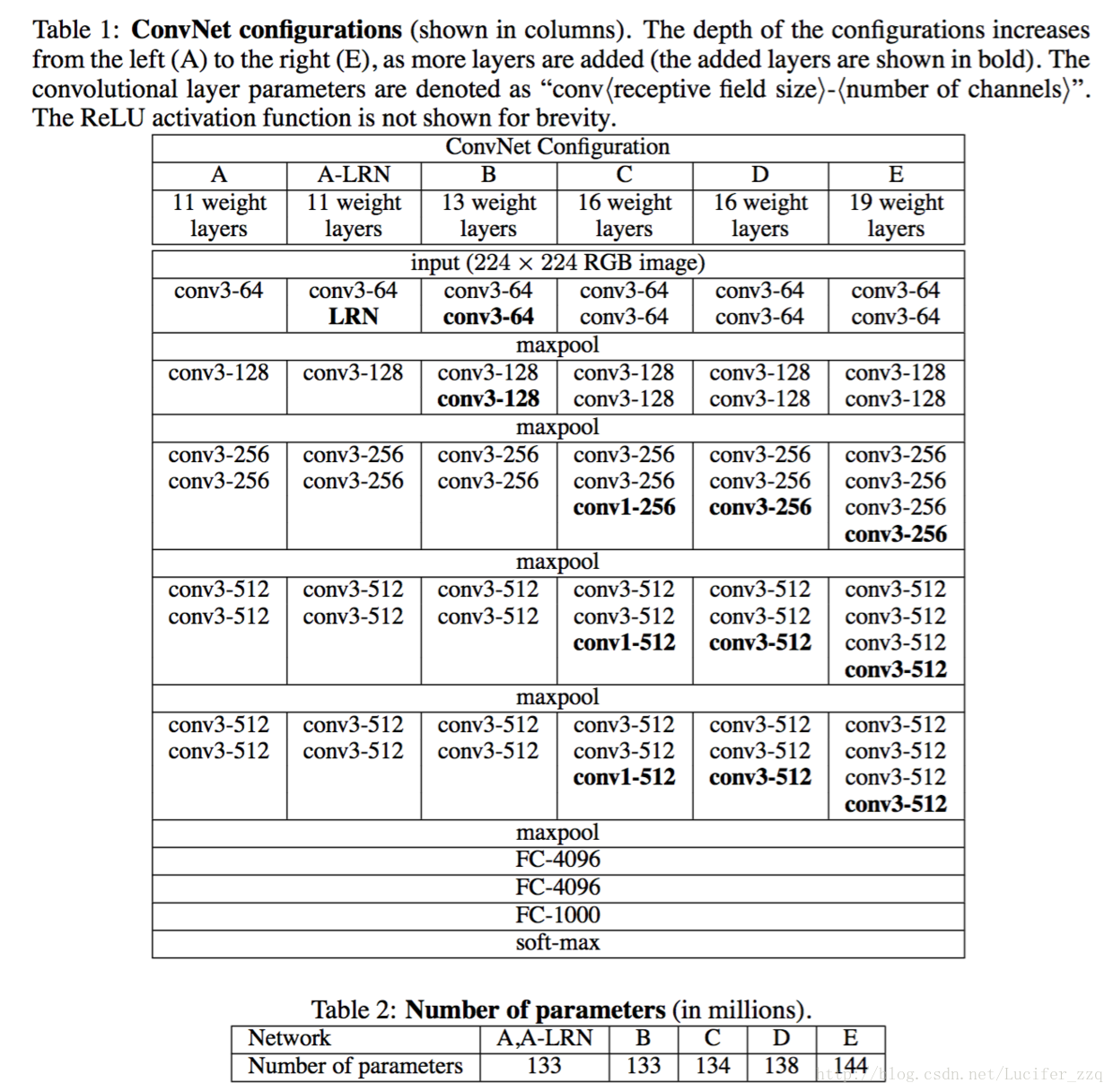
在我們的實驗中,我們採用的是D類網路,這個網路的示意圖如下:
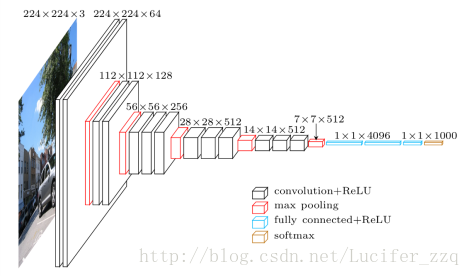
網路的輸入是一張224*224的圖片,之所以要乘一個3,是因為有3個通道。經過很多個規模為3*3的卷積核提取了很多個特徵。如224*224*3到224*224*64這經過了64個3*3的卷積核,換言之,可以理解為提取了原來圖片的64個特徵。經過一次池化後(在這裡採用的是max-pooling),圖片規模變為了112*112*64。經過一系列的操作,輸出是一個1000*1的向量,向量中每一個元素的值是一種概率的表徵。因此這個向量中1000個數字的和為1。在我們的實驗中只運行了前向過程。
下載資源並解壓後:首先在terminal中執行make,會自動下載檔案:
VGG_ILSVRC_16_layers.caffemodel
這個檔案中儲存了VGG16的weight和bias。
檔案VGG_2014_16.prototxt,儲存了VGG16的結構。
檔案tf_forward.py,描述了VGG16的前向傳播過程。
那現在我們思考一個問題:
假如我們對於最後的1000個數據不是很感興趣,而是想提取中間某一層的特徵呢?
比如說,我們想提取最後一個卷積層的輸出Cov_5(14*14*512),和第二個全連線層的輸出FC7(4096*1)並進行比較。那我們又應該怎麼做呢?
首先,將Cov_5進行降維處理將其轉化為一個512*1的矩陣。這就涉及到了對於每一個14*14的矩陣都需要進行一次特徵提取。我的操作是提取每一個14*14矩陣的最大值。
conv5_3=net_caffe.blobs[‘conv5_3’].data[0]
conv = [ [] for i in xrange(np.size(conv5,2)) ]
for i in xrange(np.size(conv5,2)):
//按塊劃分區域,一塊區域14*14的大小如果n=0,按行;n=1,按列取最大值
conv[i]=np.max(conv5[:,:,i]) //將最大值存入conv[i]
為了將512*1的向量和4096*1的向量進行比較。需要將兩個向量進行L2正則化。
L2正則化:平方和開根號。
conv_norm=conv/np.sqrt(np.sum(np.square(conv)))
np.squre()代表對陣列取平方操作
np.sum()代表對陣列進行求和操作
np.sqrt()代表對陣列進行求平方根操作
同理,再將FC7提取到的矩陣如法炮製即可。