
機器學習(一)k-進鄰演算法
k-進鄰演算法
概述

原理
存在一個樣本資料集合,也稱作為訓練樣本集,並且樣本集中每個資料都存在標籤,即我們知道樣本集中每一個數據與所屬分類的對應關係。輸入沒有標籤的新資料後,將新的資料的每個特徵與樣本集中資料對應的特徵進行比較,然後演算法提取樣本最相似資料(最近鄰)的分類標籤。一般來說,我們只選擇樣本資料集中前k個最相似的資料,這就是k-近鄰演算法中k的出處,通常k是不大於20的整數。最後,選擇k個最相似資料中出現次數最多的分類,作為新資料的分類。
步驟
- 計算已知類別資料集中的點與當前點之間的距離;
- 按照距離遞增次序排序;
- 選取與當前點距離最小的k個點;
- 確定前k個點所在類別的出現頻率;
- 返回前k個點所出現頻率最高的類別作為當前點的預測分類。
相關公式(歐氏距離)
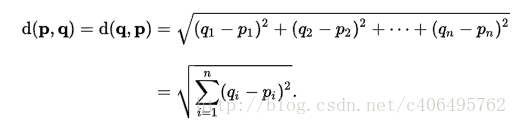
核心程式碼如下
def classify0(inX, dataSet, labels, k): dataSetSize = dataSet.shape[0] diffMat = tile(inX, (dataSetSize,1)) - dataSet sqDiffMat = diffMat**2 sqDistances = sqDiffMat.sum(axis=1) distances = sqDistances**0.5 sortedDistIndicies = distances.argsort() classCount={} for i in range(k): voteIlabel = labels[sortedDistIndicies[i]] classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True) return sortedClassCount[0][0]
注意事項
資料要做歸一化,要不其中一項的影響會特別大
比如距離的範圍0到5000,年齡範圍0到100,在算距離的時候,距離這個特徵產生的影響遠遠比年齡大,導致年齡這個特徵不起作用,正確做法是把所有特徵變為【0,1】之間,python程式碼如下
def autoNorm(dataSet): minVals = dataSet.min(0) maxVals = dataSet.max(0) ranges = maxVals - minVals normDataSet = zeros(shape(dataSet)) m = dataSet.shape[0] normDataSet = dataSet - tile(minVals, (m,1)) normDataSet = normDataSet/tile(ranges, (m,1)) #element wise divide return normDataSet, ranges, minVals
簡單例子

判斷一個電影是愛情片還是武打片,取兩個特徵打鬥鏡頭和接吻鏡頭,由於這兩個特徵是否歸一化影響不大,所以這裡忽略歸一化,有了這四個訓練集,現在測試資料有一部電影打鬥鏡頭101次,接吻鏡頭20次,是什麼型別的電影
通過計算,我們可以得到如下結果:
(101,20)->動作片(108,5)的距離約為16.55
(101,20)->動作片(115,8)的距離約為18.44
(101,20)->愛情片(5,89)的距離約為118.22
(101,20)->愛情片(1,101)的距離約為128.69
通過計算可知,電影到動作片 (108,5)的距離最近,為16.55。如果演算法直接根據這個結果,判斷該紅色圓點標記的電影為動作片,這個演算法就是最近鄰演算法,而非k-近鄰演算法。k-近鄰演算法,我們假設k=3,也就是取距離最近前三個的最大值作為其結果,最近的前三個為
動作片(108,5)的距離約為16.55
動作片(115,8)的距離約為18.44
愛情片(5,89)的距離約為118.22
裡面出現動作片次數2大於愛情片1,所以(101,20)利用k-進鄰演算法的結果是動作片
喜歡的小夥伴可以給個贊哦