
使用caffe fine-tune一個單標籤影象分類模型
進行網路模型的訓練與測試(基於預訓練的模型)。
準備資料
這步主要是自己先把資料集劃分好,比如訓練集、驗證集和測試集各多少張,並把相應的圖片放到對應的資料夾下。一些針對影象本身的預處理,比如要進行資料增強,就可以在此步實現(資料增強在第2步資料轉換時也可以做,但是沒有自己手動的資料增強靈活)。除此之外,就是要生成一個txt檔案來描述資料集的ground-truth,如下圖所示: 
檔案在形式上就包含兩項,第一項是圖片名稱(或者包含名稱的路徑),第二項是圖片對應的類別ID(以單個整數表示,如0,1,2,3……),中間以空格間隔。
資料轉換
這一步可以利用caffe自帶的例子中的指令碼完成資料轉換。從caffe的根目錄進入到次級目錄examples中,再找到imagenet資料夾,裡面有一個名為create_imagenet.sh的檔案,此檔案即進行資料轉換的指令碼。將此指令碼檔案複製一份到自己專案的合適目錄下,然後進行一定的更改即可,下面以本人具體工作為例進行些許解釋。
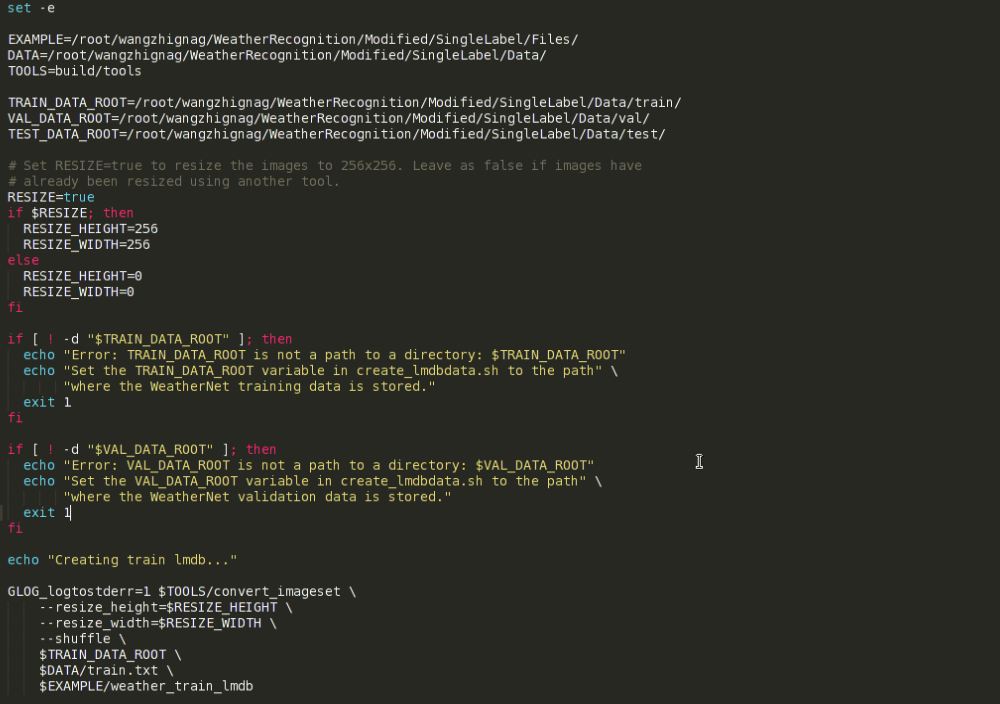
上圖即為資料轉換指令碼檔案的主要內容,主要有一些路徑和引數需要進行更改。圖中,從上到下各變數代表的意思依次是:EXAMPLE指定轉換後的lmdb資料存放的路徑,DATA指定原生資料所在目錄,TOOLS指定實際進行資料轉換時所用到的檔案所在的目錄,即build/tools,注意這是個相對路徑,此路徑不必做更改,不過這樣一來,則必須在caffe的根目錄下執行該指令碼檔案。將TOOLS改為絕對路徑應該就破除了上句所說的限制,但本人並未嘗試過。從指令碼檔案中再往下看,三個…DATA_ROOT變數分別代表訓練集、驗證集和測試集所在目錄。也就是說,在第一步準備資料之後,資料集和對應的標註檔案應是下圖所示樣子:

接著往下看,首先是RESIZE選項,預設為true,由於本人使用的是AlexNet預訓練模型,一般是先把圖片resize到256*256的大小(再做裁剪,後面會提到)。當然,resize的高和寬都是可以根據具體的要求而更改的。如不需要resize,將RESIZE變數設為false即可。
再往下是執行時的一些錯誤提示資訊,這裡主要是針對資料集的路徑進行了異常檢測,也可以根據需要自行新增其他的錯誤提示,萬一資料集路徑寫錯,執行時大概會報如下錯誤:

指令碼檔案的最後是實際呼叫資料轉換檔案進行操作的關鍵部分,這裡指定了圖片resize的大小和shuffle選項,shuffle就是指將原資料集打亂重新排列,另外,最後三項分別指定了如前所述的資料集所在目錄、ground-truth標註檔案和生成資料的名稱及儲存路徑,指令碼檔案執行情況如下圖所示:
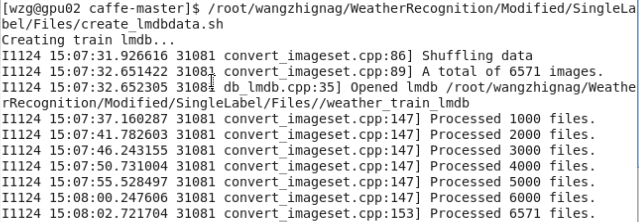
最終完成後,最終會在指定的目錄下得到如下三個資料夾,名字是指令碼檔案中指定的。

除了生成這些檔案,還需要生成一個均值檔案,因為機器學習演算法一般都會對資料做去均值化處理,此均值檔案會在網路訓練時用到。同樣的有一個執行這種操作的指令碼檔案,也可以在”caffe_root”/examples/imagenet檔案下找到,內容很簡單,如下所示: 
前三個變數和上個指令碼中是一樣的,只是具體命令上需要注意一下,這裡用到了剛剛生成的訓練集的lmdb檔案,本工作中的名字是”weather_train_lmdb”,請根據具體情況自行更改。命令的第二行即生成的均值檔案的名稱和儲存路徑。在caffe根目錄下執行此指令碼檔案,最終會在指定路徑下得到”_mean.binaryproto”檔案。
網路模型的定義/編輯
資料轉換完成後,就可以對我們所用的網路結構進行編輯更改了,完全自定義新的網路結構並從頭訓練當然也是可以的,不過本文旨在說明使用caffe做fine-tune的過程,下面就以AlexNet為例,進行網路結構編輯的說明。caffe中,網路結構最終是以.prototxt(檔案字尾)檔案來定義的,可以通過寫程式碼來定義網路,不過最後還是要生成一個.prototxt檔案來執行,所以本人就直接在AlexNet的定義檔案中直接進行了修改。AlexNet的網路定義檔案可以在”caffe_root”/models/bvlc_alexnet資料夾下找到,即train_val.prototxt檔案。對於一個普通的識別任務來講,主要就是要更改輸入層和輸出層(全連線層的最後一層)。原AlexNet的網路定義檔案的輸入層部分如下所示: 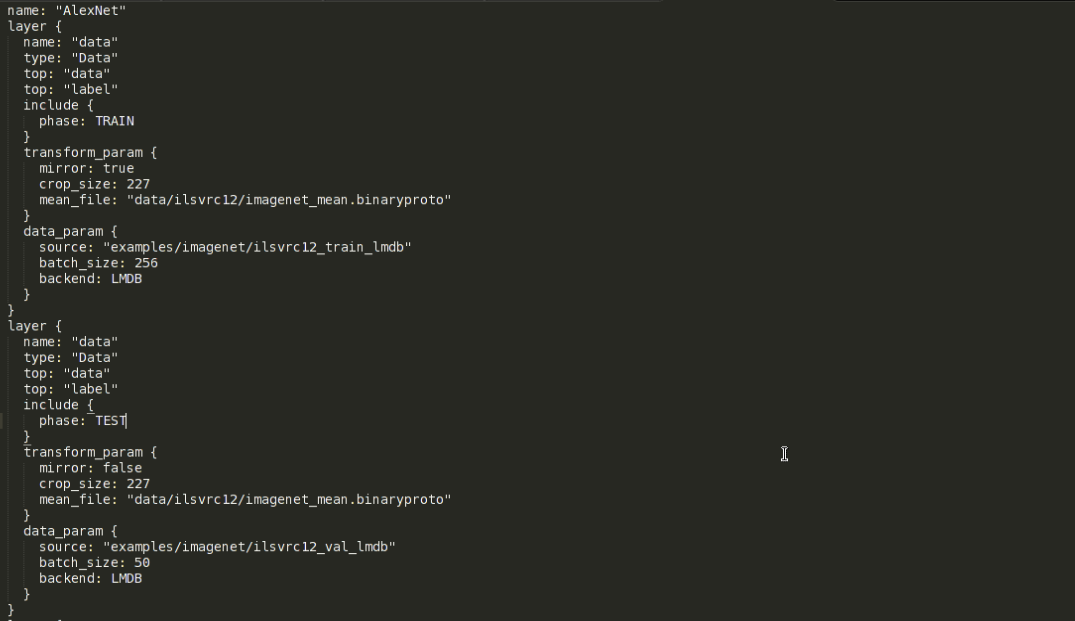
可以看到,此檔案包含兩個輸入層,每個layer對應的大括號中的內容分別對應著一個輸入層的定義。具體的prototxt檔案的格式、每層網路的定義請參見caffe官網http://caffe.berkeleyvision.org/
兩個輸入層一個是訓練時用,一個是測試驗證時用,以include{phase:}標籤來區別,訓練的輸入層對應的phase是TRAIN,而測試驗證的輸入層對應的是TEST。本人為了後續訓練測試時的靈活性起見,將訓練和測試網路用兩個獨立的prototxt檔案來定義,其實它們主要是輸入層的不同。
再來看transform_param,這是轉換引數,此項主要用於資料增強,mirror變數代表圖片映象變換,其值為true則在訓練時對圖片進行隨機的映象變換。crop_szie代表圖片裁剪後的大小,而AlexNet指定的輸入影象為227*227,而我們之前做資料轉換時圖片resize的大小是256*256,所以這裡要裁剪一下。如果是訓練階段,則裁剪是在圖片內隨機進行的,這樣也可以起到一定的資料增強效果,如果是測試階段,則裁剪圖片正中央的部分。這裡一定要保證圖片原始尺寸比裁剪後的尺寸大。mean_file要指定我們之前在資料轉換階段生成的均值檔案,指定好之後,就可以在訓練測試時對資料做去均值化處理了。
data_param中,source變數指定轉換後的lmdb檔案路徑,batch_size很好理解,就是一個batch包含多少張圖片,backend指定資料的型別,這裡自然是LMDB。
接下來是輸出層、loss層和accuracy層的修改,下圖展示的是我更改後的定義: 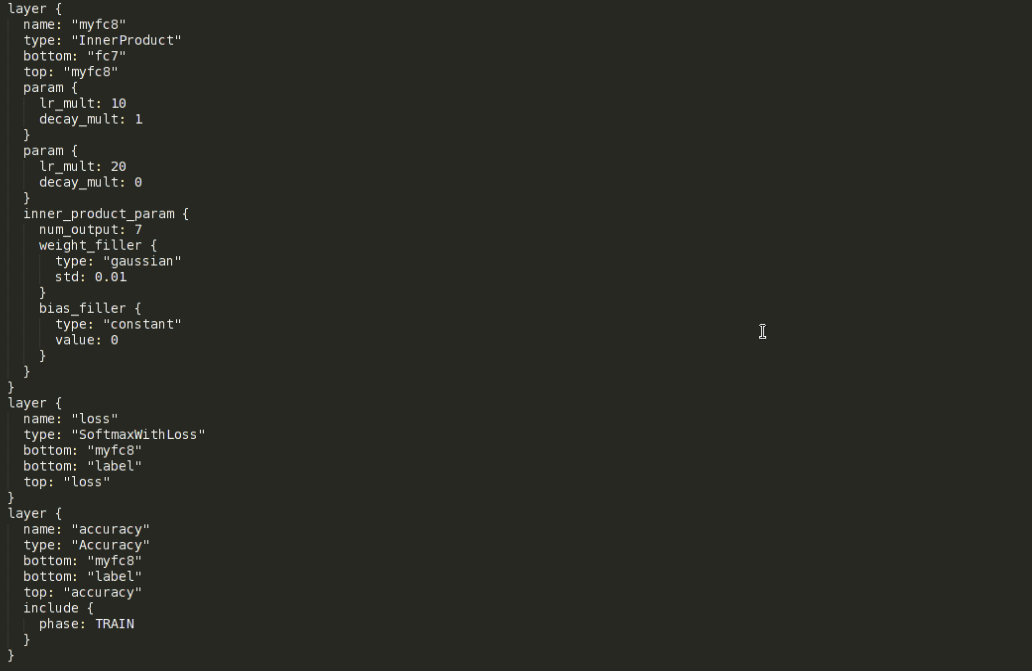
原本輸出層的名字是fc8,這裡首先要把名字改掉。因為fine-tune時會從預訓練的模型中拷貝引數,而實際操作時是按對應層的名字進行引數拷貝的,改掉名字後就會自動忽略這一層而不會進行拷貝。然後top變數對應的值也改成當前層的名字,之後兩個param中分別定義了當前層網路的權重和偏置的學習率以及權值衰減引數。權值衰減引數是正則項(為了避免過擬合,大多數網路除了正則項還會在網路中加入dropout層)的係數,這裡一般不做更改。兩個lr_mult(learning rate)都是其它層的10倍,因為其他層是在做fine-tune,而輸出層根據任務的不同,輸出單元的個數往往和預訓練模型不一樣,這就導致無法對輸出層也做fine-tune(輸出單元數目不同,無法直接拷貝引數)。那麼輸出層就需要從頭訓練,給一個較大的學習率是希望它能儘快收斂。再下面是inner_product_parm,這裡面主要修改的是num_output,即輸出單元的個數,具體視不同任務而定,比如本工作中類別數目是7類,所以圖中此項的值就為7。其餘的都不更改。至於剩餘的引數這裡就不專門介紹了,感興趣者可以查閱官網或其他資料進行了解。
loss層和accuracy層裡面主要把除label外的bottom項改成我們自己的輸出層的名字即可。到此為止,網路模型就修改完畢了。
Solver的定義/編輯
solver可以簡單地理解為一個配置檔案,裡面定義了很多和訓練測試相關的引數,本工作的solver檔案截圖如下: 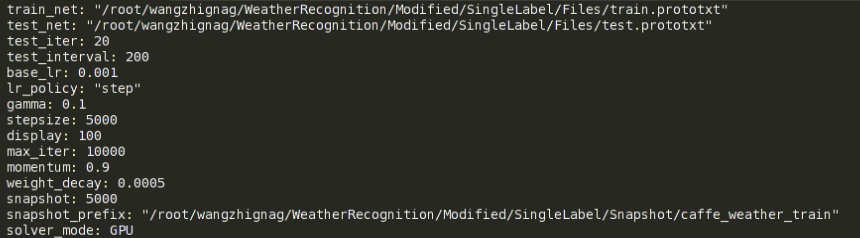
前兩項分別用來指明網路模型的定義檔案的路徑,由於本人是將訓練網路和測試網路分開定義的,所以這裡就對應著有這兩項,原本caffe自帶的AlexNet例子中只有下面這一行:
net: "models/bvlc_alexnet/train_val.prototxt"- 1
- 1
solver檔案中接下來是test_iter,這個變數要特別注意一下,它指定的數字和網路結構定義中指定的batch_size的乘積要等於測試集包含的圖片的數量。比如本例中,測試集總共1000張圖片,batch_size是50,所以test_iter就得設為20。其實這個test_iter就指定了一次測試跑多少個iteration(一個iteration就是一次迭代),也就等於跑多少個batch,只有test_iter*batch_size等於測試集圖片總數時,才是一次測試恰好把測試集遍歷一遍。
test_interval和display放到一起來說,前者指定訓練中每隔多少次iteration進行一次測試,後者指定每隔多少次iteration進行階段性的輸出顯示,顯示內容主要就是loss和accuracy的情況。
base_lr指的是基礎learning rate,它和網路定義中每層各自的learning rate的乘積是各個引數實際的學習率,solver檔案中的weight_decay也是同樣道理,它指的是基礎的權值衰減係數。lr_ploicy指的是學習策略,如果設為”fixed”,則在整個訓練過程中,基礎學習率保持不變。不過這裡我們採用”step”策略,它和gamma、stepsize項共同起作用。實際效果就是訓練中每隔stepsize指定的迭代次數,基礎學習率就乘以一次gamma值,gamma是一個小數,一般設為0.1,這樣做的理由是:訓練越往後網路引數越趨近於收斂,相應地也應該調低學習率。max_iter指定一共訓練多少個iteration,momentum指定隨機梯度下降優化方法中的動量值,這裡對演算法本身不做介紹。snapshot指定每隔多少次iteration對模型引數和記憶體狀態進行一次儲存,目的是應對突然斷電或者訓練到後面網路效能反而下降的情況。snapshot中儲存的中間模型引數既可以直接拿來使用,也可以繼續在其上fine-tune(這點就是為了應付突然斷電的情況)。snapshot_prefix指定的是snapshot儲存的路徑和名字字首,根據迭代次數不同,名字後還會加上儲存snapshot時的iteration次數。solver_mode指定了硬體是用CPU還是GPU。另外,如不指定所用的優化方法,則預設使用隨機梯度下降演算法。針對不同的優化方法,solver中的引數也有不同,這裡不做過多介紹。
到此,solver檔案就修改完畢了。
網路模型的訓練與測試
前面的準備工作都做好後就可以開始進行網路的訓練與測試了,這一步可以直接從命令列進行,具體參見caffe官網fine-tune例子。本工作中為了能夠靈活地進行展示與繪圖,決定使用caffe的Python介面,通過寫程式碼來進行訓練測試。不過首先需要編譯pycaffe。
程式碼中,首先要匯入caffe模組,後兩行用來指定在GPU模式下訓練網路以及指定使用哪塊顯示卡(多卡情況下)。
import caffe
caffe.set_mode_gpu()
caffe.set_device(2)- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
然後指定好預訓練好的模型所在的目錄,為fine-tune做準備。
weights = caffe_root + 'models/weatherNet/weatherDB_sp1.caffemodel'- 1
- 1
再接下來就是定義執行solver的函數了:
def run_solvers(niter, solver, disp_interval=100, test_interval=200, test_iter=20):
fig1,ax1=plt.subplots() #used for draw
fig2,ax2=plt.subplots() #used for draw
train_loss=np.zeros(np.ceil(niter*1.0/disp_interval))
train_acc=np.zeros(np.ceil(niter*1.0/disp_interval))
test_loss=np.zeros(np.ceil(niter*1.0/test_interval))
test_acc=np.zeros(np.ceil(niter*1.0/test_interval))
atom_train_loss, atom_train_acc, atom_test_loss, atom_test_acc = 0, 0, 0, 0
train_count, test_count = 0, 0
for it in range(1, niter+1):
solver.step(1)
atom_train_loss += solver.net.blobs['loss'].data
atom_train_acc += solver.net.blobs['accuracy'].data
if it % disp_interval == 0:
train_loss[train_count] = atom_train_loss/disp_interval
train_acc[train_count] = atom_train_acc/disp_interval
atom_train_loss=0
atom_train_acc=0
print '\n##########%d iteration train: loss=%.3f, accuracy=%.3f\n' %(it,
train_loss[train_count], train_acc[train_count])
train_count += 1
if it % test_interval == 0:
for test_it in range(test_iter):
solver.test_nets[0].forward()
atom_test_loss += solver.test_nets[0].blobs['loss'].data
atom_test_acc += solver.test_nets[0].blobs['accuracy'].data
test_loss[test_count] = atom_test_loss/test_iter
test_acc[test_count] = atom_test_acc/test_iter
atom_test_loss=0
atom_test_acc=0
print '##########%d iteration Test: loss=%.3f, accuracy=%.3f\n' %(it,
test_loss[test_count], test_acc[test_count])
test_count += 1
################## Draw
ax1.cla()
ax1.set_title('Display Loss')
ax1.set_xlabel('Iteration/100')
ax1.set_ylabel('Loss')
ax1.set_xlim(0,100)
ax1.grid()
ax1.plot(train_loss[:train_count],'r',label='train loss')
ax1.plot(range(0,test_count*2,2),test_loss[:test_count],'g',label='test
loss')
ax1.legend(loc='best')
ax2.cla()
ax2.set_title('Display Accuracy')
ax2.set_xlabel('Iteration/100')
ax2.set_ylabel('Accuracy')
ax2.set_xlim(0,100)
ax2.grid()
ax2.plot(train_acc[:train_count],'r',label='train accuracy')
ax2.plot(range(0,test_count*2,2),test_acc[:test_count],'g',label='test
accuracy')
ax2.legend(loc='best')
plt.pause(1)
return train_loss, test_loss, train_acc, test_acc- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
函式引數中,niter對應的就是solver檔案中的max_iter,即訓練總共迭代多少次。solver引數指定solver檔案的路徑,disp_interval=100, test_interval=200, test_iter=20這三項分別對應solver檔案中的display、test_interval和test_iter。
fig1,ax1=plt.subplots() #used for draw
fig2,ax2=plt.subplots() #used for draw- 1
- 2
- 1
- 2
開頭這兩句是為後面展示loss和accuracy的動態畫圖生成的物件,畫圖相關內容請參見我的上篇博文。
train_loss=np.zeros(np.ceil(niter*1.0/disp_interval))
train_acc=np.zeros(np.ceil(niter*1.0/disp_interval))
test_loss=np.zeros(np.ceil(niter*1.0/test_interval))
test_acc=np.zeros(np.ceil(niter*1.0/test_interval))
atom_train_loss, atom_train_acc, atom_test_loss, atom_test_acc = 0, 0, 0, 0
train_count, test_count = 0, 0- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
接下來這些程式碼是為儲存相關的loss、accuracy而準備的,主要是提前為變數分配好記憶體空間。
迴圈裡是執行solver並進行統計的主要內容,關鍵程式碼就是下面這一行:
solver.step(1)- 1
- 1
step()函式是caffe中solver物件自帶的,每迴圈一次就step一下,而step一次其實是包含兩個步驟,即網路在一個batch上前向計算一次,得到相應的loss和accuracy。然後再反向傳播一次,進行網路引數的更新。
atom_train_loss += solver.net.blobs['loss'].data
atom_train_acc += solver.net.blobs['accuracy'].data
if it % disp_interval == 0:
train_loss[train_count] = atom_train_loss/disp_interval
train_acc[train_count] = atom_train_acc/disp_interval
atom_train_loss=0
atom_train_acc=0
print '\n##########%d iteration train: loss=%.3f, accuracy=%.3f\n' %(it,
train_loss[train_count], train_acc[train_count])
train_count += 1
if it % test_interval == 0:
for test_it in range(test_iter):
solver.test_nets[0].forward()
atom_test_loss += solver.test_nets[0].blobs['loss'].data
atom_test_acc += solver.test_nets[0].blobs['accuracy'].data
test_loss[test_count] = atom_test_loss/test_iter
test_acc[test_count] = atom_test_acc/test_iter
atom_test_loss=0
atom_test_acc=0
print '##########%d iteration Test: loss=%.3f, accuracy=%.3f\n' %(it,
test_loss[test_count], test_acc[test_count])
test_count += 1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
這段程式碼主要進行loss和accuracy的統計,大概意思是每次迭代都對loss和accuracy進行累加,等到了該顯示的迭代次數時,對loss、accuracy求一個平均值,並記錄下來。用於累加的atom…_loss和atom…_acc清空,然後在控制檯對當前的結果進行顯示。前一段程式碼是針對訓練資料的,而後一段則是針對測試的,性質都一樣。
再往下就是畫圖程式碼了,關於畫圖的內容就不再細講了,可以參考我的上篇博文。
實際執行時,使用下面三句程式碼:
solver =
caffe.get_solver('/root/wangzhignag/WeatherRecognition/Modified/SingleLabel/Files/so
lver.prototxt')
solver.net.copy_from(weights)
train_loss, test_loss, train_acc, test_acc = run_solvers(10000,solver)- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
第一句是從我們定義的solver檔案中獲取相關引數的設定,從而建立一個solver物件。第二句是使用預訓練的模型給網路做引數初始化,這裡的weights是前面指定好的預訓練模型的路徑。最後一句則是呼叫剛剛定義的run_solver()函式來得到相應的loss和accuracy。
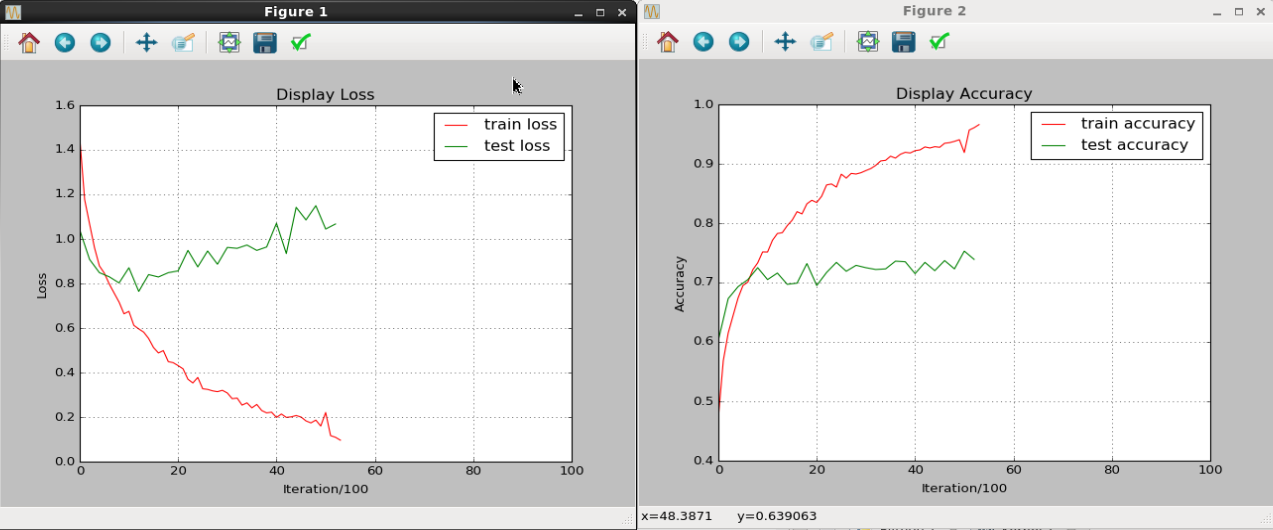
上圖是執行過程中的結果展示情況,可以看出無論是loss還是accuracy,訓練集和測試集上的結果都有著明顯的gap,個人猜測應該是資料量不足導致無法完全發揮CNN的效能。動態畫出中間結果也是為了能及時地發現過擬合現象,從而儘早停止訓練。
接著,再定義一個專門計算準確率的函式:
def eval_net(Netdef=caffe_root + 'models/weatherNet/test.prototxt',
weights='/root/wangzhignag//WeatherRecognition/SingleLabelWeatherNet/snapshot/caffe_
weather_train_iter_10000.caffemodel',
test_iters=20):
test_net = caffe.Net(Netdef, weights, caffe.TEST)
accuracy = 0
for it in xrange(test_iters):
accuracy += test_net.forward()['accuracy']
accuracy /= test_iters
return test_net, accuracy- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
函式引數包括測試網路的定義檔案(prototxt)的路徑,訓練好的網路模型的路徑,以及test_iter(含義與run_solver函式的一樣)。函式體裡面,先使用網路定義檔案和訓練好的網路模型來創建出一個測試網路的物件,具體求值過程很簡單,就是每次迭代累加accuracy,最後求一個平均值就OK了。
至此,整個流程就都介紹完了,還有一些附加的功能比如展示圖片和相應的預測結果,給出前K大得分對應的類別等等這裡就不介紹了,感興趣者可以參考caffe官網中給出的例子使用jupyter notebook進行fine-tune。