
隨機計算(3)——Stochastic Circuit Synthesis by Cube Assignment
阿新 • • 發佈:2019-01-08
1、Abstract
SC(Stochastic Computing)對於位元翻轉表現出強大的容錯能力(The tolerance to bit-flip errors)。更重要的是,它相比於傳統的二進位制編碼方式計算,能夠利用更簡單的電路實現更復雜的算術功能。在這篇論文中,提出了一種特殊的設計高效能隨機計算電路的方法。這種方法是基於一種啟發式的廣度優點遍歷搜尋演算法在解空間中確定一個最優解進而使得電路滿足一些要求。
2、Introduction
對於SC的基本介紹可以檢視我的這篇部落格:https://blog.csdn.net/qq_34037046/article/details/84306846
中的Introduction
在這篇論文中,主要的貢獻:
1、提出了一種新的方法利用迭代的方法確定Cube
2、提出了一種啟發式廣度優先遍歷搜尋演算法來尋找更好的Cube 選擇方案;
3、將上述演算法拓展,從而可以應用到多變數多項式中。
這篇文章相對於以前文章中提出的方法主要的改進:
1、提出了廣度優先遍歷演算法,更加節省時間
2、不僅適用於單變數任意多項式,還適用於任意多變數多項式;
3、改進了這個演算法,不僅適用於二級電路,也適用於多級電路。
3、Background on Synthesis Stochastic Circuits
我們提出的方法是基於一個一般形式的隨機電路。
A、一般隨機計算電路和它的表示式
一個一般形式的隨機計算電路如下:
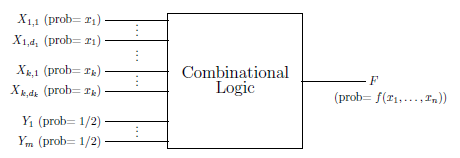
如上圖,可以將輸入分成k+1
另外,的選擇很重要。它能夠決定量化誤差的大小,越大,量化誤差越小。這個事先一般會提供需要的精度,這部分見部落格:
https://blog.csdn.net/qq_34037046/article/details/84306846
中的Part4 A有描述。
為了方便描述,接下來做出兩個定義:
我們將輸入寫成向量形式:,同樣,。任意輸入向量的概率是:
根據上面的式子我們可以總結到:在同一個集合中的任意兩個輸入向量的概率是相等的。換言之,一個構造了一個等價輸入向量類。這個類中含有的基數是