
Tensorflow實現影象分割——FCN模型
轉載自:http://blog.csdn.net/scutjy2015/article/details/70230379
導讀:本專案是基於論文《語義分割全卷積網路的Tensorflow實現》的基礎上實現的,該實現主要是基於論文作者給的參考程式碼。該模型應用於麻省理工學院(http://sceneparsing.csail.mit.edu/)提供的場景識別挑戰資料集。
專案所需的七大條件
-
結果是在12GB TitanX上訓練大約6~7小時後獲得的。
-
該程式碼最初是用tensorflow0.11和python2.7編寫和測試的。 tf.summary的呼叫已更新tensorflow 0.12版本。如果要使用舊版本的tensorflow,請使用另一分支tf.0.11_compatible(https://github.com/shekkizh/FCN.tensorflow/tree/tf.0.11_compatible)。
-
在使用tensorflow1.0和windows時會有一些問題。這些問題已經在issue#9(https://github.com/shekkizh/FCN.tensorflow/issues/9)中討論過了。
-
訓練模型只需執行python FCN.py
-
要視覺化一個隨機批次的影象的結果,zhi'yao'yo使用標誌--mode=visualize
-
debug標誌可以在訓練期間設定,以新增關於啟用函式,梯度,變數等的資訊。
-
這個IPython筆記本(https://github.com/shekkizh/FCN.tensorflow/blob/master/logs/images/Image_Cmaped.ipynb)可以用於檢視彩色結果,如下方圖片所示。
實驗結果:時間更短 效率更高
通過批次大小為2,縮放大小為256*256的圖片訓練模型得到以下結果。請注意,雖然訓練圖片是256*256,dan沒有任何東西可以防止模型在任意大小的影象上工作。預測影象沒有進行後處理。通過9輪訓練 - 訓練時間較短,這解釋了為什麼某些概念似乎在模型中能被語義理解,而另一些概念似乎沒有。下面的結果來自驗證資料集的隨機影象。
網路設計和原論文在caffe中設定的幾乎一樣。新增的新層的權重用小值進行初始化,並使用Adam 優化器(學習率= 1e-4)進行學習。

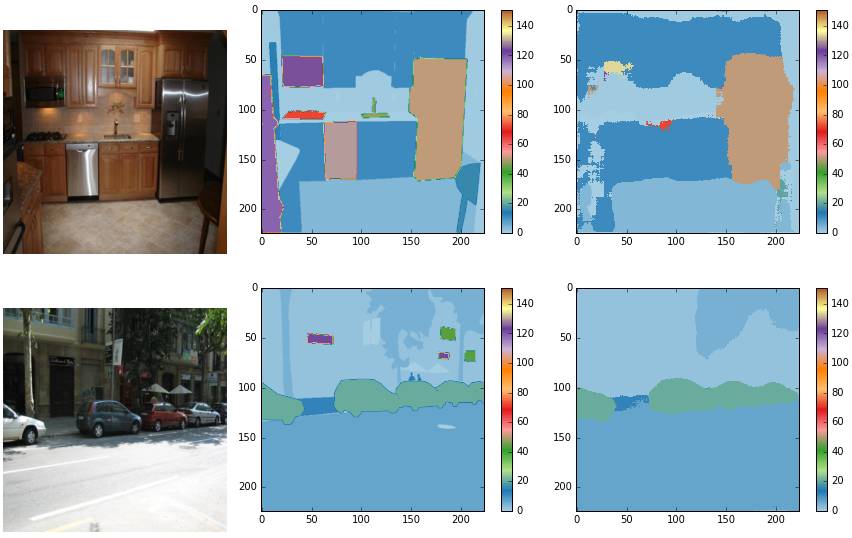
資料觀察
-
小批量是必要的,以適應記憶體大小,但這導致訓練過程慢
-
有很多例子的概念似乎被正確識別和feng- 在上面的例子中可以看到,汽車和人被識別得更好。我相信這可以通過訓練更長的時間來解決。
-
此外,影象大小調整會導致資訊丟失 - 可以注意到,實際上較小的物件被分割的準確率較低。

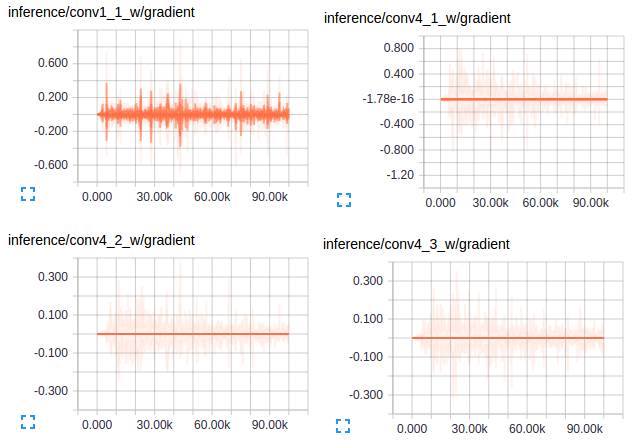
對於梯度:
-
如果仔細觀察梯度,你會注意到初始訓練幾乎完全集中在新增的新層次上 - 只有在這些層被合理訓練之後,我們才能看到VGG層獲得一些梯度流。這是可以理解的,因為新層次在開始時更多地影響損失目標。
-
使用VGG權重初始化網路的前幾層,因此在概念上講這些層需要較少的調整,除非訓練資料是非常多樣的- 在這種情況下不是。
-
卷積模型的第一層捕獲低級別的資訊,並且由於這些資訊依賴於資料集,你會注意到梯度tong'g調整第一層權重以使模型適應資料集。
-
來自VGG的其他卷積層具有非常小的梯度流動,因為這裡捕獲的概念對於我們的最終目標 - 分割是足夠好的。
-
這是轉移學習運作良好的核心原因。我只是想到在這裡指出一下。
論文地址:https://arxiv.org/pdf/1605.06211v1.pdf
論文視訊地址:http://techtalks.tv/talks/fully-convolutional-networks-for-semantic-segmentation/61606/
GitHub資源:https://github.com/shekkizh/FCN.tensorflow